Download and install the Weka system on your computer. We've prepared a set of instructions to get started and a minitutorial. Click here. You'll also need to download the Two Spirals dataset here.
Use Weka to train a multilayer perceptron (MLP) to classify the
Two Spirals data. The class labels are given in the Class
column whereas the variables A1 and A2 are
the x- and y-coordinates which are the input features.
Note that using the default settings gives poor results. When
accuracy is measured using the Percentage split % 66
setting, the accuracy is 52.9 % (36 correct, 32 incorrect
instances). Click Visualize classification errors and
let the x- and y-axis be the input variables A1 and
A2 respectively. You will be able to see that the
decision boundary, which is completely bonkers.
Adjust the MLP settings and experiment with different number of
hidden layers (the parameter hiddenLayers shows the
number of neurons on each hidden layer, separated by
colons :), and the number of training iterations
(trainingTime). You should get classification error
less than 10 %.
- Use Weka to train a nearest neighbor classifier (Lazy/IB1).
- Do the same with a decision tree (Trees/J48).
- Visualize the decision boundaries and explain why the MLP, nearest neighbor, and decision tree classifiers work or don't work in this case.
Hint: For item 3, open GUI Chooser in Weka, click "Visualization" in the top menu, and choose "BoundaryVisualizer".
Digital Signal Processing
The topics of this week include two special kinds of data that require somewhat specific techniques: digital signals (such as audio or images), and natural language.
Next week we will finish the Digital Signal Processing and Robotics theme by studying robotics.
| Theme | Objectives (after the course, you ...) |
| Natural language processing |
|
| Digital Signal Processing and Robotics |
|
Digital signal representations
Digital image and audio signals represent recordings of natural signals in numerical form. For images, the values represent pixel intensities stored in a two-dimensional array. A third dimension can be used to store different bands for, e.g., red, green, and blue (RGB). We can also think of the values are functions of the x and y coordinates, F(x,y).
Fun fact (but not required for the exam): In the case of audio, the signal can be thought to be a signal of time, F(t), but other representations such as those that are functions of frequency, F(f), are commonly used. The frequency representation is particularly well suited for compact representation since frequency bands outside the audible range 20 Hz to 20 kHz can be left out without observable (to humans) effect.
Pattern recognition
Pattern recognition is a good example of an AI problem involving digital signals. It means generally the problem is recognizing an object in a signal (typically an image). The task is made hard because signals tend to vary greatly depending on external conditions such as camera angle, distance, lighting conditions, echo, noise, and differences between recording devices. Therefore the signal is practically always different even if it is from the same object.
Based on these facts, an essential requirement for successful pattern recognition is the extraction of invariant features in the signal. Such features are insensitive (or as insensitive as possible) to variation in the external conditions, and tend to be similar in recordings of the same object. In the lecture slides there is a famous photograph of an Afghan girl by Steve McCurry. She was identified based on the unique patterns in the iris of the eye. Here the iris is the invariant feature, which remains unchanged when a person grows older even if their appearance may otherwise change. The iris is an example of invariance, and a metaphor for more general invariance with respect to external conditions.
SIFT and SURF
Good examples of commonly used feature extraction techniques for image data include Scale-Invariant Feature Transform (SIFT) and Speeded-Up Robust Features (SURF). We take a closer look at the SURF technique. It can be broken into two or three stages:
- Choosing interest points: We identify a set of (x,y) points by maximizing the determinant of a so called Hessian matrix that characterizes the local intensity variation around the point. The interest points tend to be located at "blobs" in the image. (You are not required to decode the details of this -- a rough idea is enough.)
- Feature descriptors: The intensity variation around each interest point is described by a feature descriptor which is a 64-dimensional vector (array of 64 real values). In addition, the feature has a scale (size) and an orientation (dominant direction).
- Feature matching: If the problem is to match objects between two images, then both of the above tasks are performed on both images. We then find pairs of feature descriptors (one extracted from image A and the other from image B) that are sufficiently close to each other in Euclidean distance.
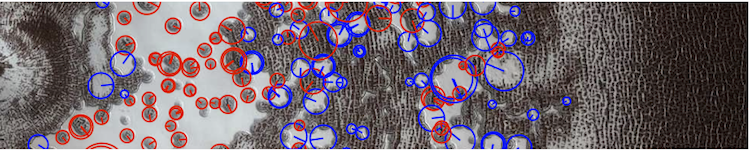
Above is an example of detected features: interest point location, scale, and orientation shown by the circles, and the type of contrast shown by the color, i.e., dark on light background (red) or light on dark background (blue). Image credit: NASA/Jet Propulsion Laboratory/University of Arizona. Image from the edge of the south polar residual cap on Mars.
The TMC template for the pattern recognition task implements SURF feature extraction and matching. When you run the template, you should get the face example presented at the lecture.
The red dots in the images are the locations of the SURF interest points. The lines between points in the two images represent matches, i.e., pairs of features whose descriptor vectors are sufficiently close to each other to be classified as belonging to the same or similar looking object.
Change the files img1.jpg and img2.jpg in
the example folder to another pair of images, and
rerun the template. Note: The images must be the same
height. (Width can be different.)
Try at least five different pairs of images, some of which include the same building, person, and/or object. Try to find examples where the feature matching works, and examples where it doesn't.
Use the same template as in the previous exercise.
Choose one or more images and do the following modifications (one at a time):
- change brightness, contrast, and color balance
- rotate the image
- crop and rescale
- add noise or blur
Does SURF recognize the objects in the image as the same despite the alterations?
An alternative (more fun) way: Take multiple photos of the same image from slightly different angles, different distances, in different lighting conditions, with occlusion, etc. Does SURF recognize the object despite such changes in external conditions?
Natural Language Processing
Language is another example of an area where AI has hard time considering how easy it feels to us, as humans, to understand natural scenes or language. This is probably in part because we don't appreciate the hardness of tasks that even a child can perform without much apparent practice. (Of course, a child actually practices these skills very intensively, and in fact, evolution has trained us for millions of years, preconditioning our "neural networks" to process information in this form.)
The features that make language distinctive and different from many other data sources for which we may apply AI techniques include:
- Even though language follows an obvious linear structure where a piece of text has a beginning and an end, and the words inbetween are in a given order, it also has hierarchical structures including, e.g., text–paragraph–sentence–word relations, where each sentence, for example, forms a separate unit.
- Grammar constrains the possible (allowed) expressions in natural languages but still leaves room for ambiguity (unlike formal languages such as programming languages which must be unambiguous).
- Compared to digital signals such as audio or image, natural language data is much closer to semantics: the idea of a chair has a direct correspondence with the word 'chair' but any particular image of a chair will necessarily carry plenty of additional information such as the color, size, material of the chair and even the lighting conditions, the camera angle, etc, which are completely independent of the chair itself.
Formal languages and grammars
Natural language processing (NLP) applies many concepts from
theoretical computer science which are applicable to the study of
formal languages. A formal language is generally a set of
strings. For example, the set of valid mathematical expressions is a
formal language that includes the
string (1+2)×6–3 but not the string
1+(+×5(. A (formal) grammar is a set
of symbol manipulation rules that enables the generation of the
valid strings (or "sentences") in the language.
An important subclass of formal languages is context-free
languages. A context-free language is defined by a
context-free grammar, which is a grammar with rules of the
form V⟶w, where V is
a non-terminal symbol, and w is a sequence of
non-terminal or terminal symbols. The context-free nature
of the rules means that such a rule can be applied independently
of the surrounding context, i.e., the symbols before or
after V.
An example will hopefully make the matter clear. Let S
be a start symbol, which is also the only non-terminal symbol
in the grammar. Let the set of terminal symbols be ()[].
The set of rules is given by
S ⟶ SS S ⟶ S ⟶ (S) S ⟶ [S]
The language defined by such a grammar is the set of strings that
can be generated by repeated application of any of the above rules,
starting with the start symbol S.
For example, the string () can be generated by first
applying the rule S ⟶ (S) to the start symbol,
whereupon we obtain the intermediate string (S).
Applying the rule S ⟶ to the symbol S
in the intermediate string, to obtain the final outcome
().
As another example, the string (())[] also belongs to
the language. Can you figure out a sequence of rules to generate it
from the start symbol S? Notice that each application
of a rule only applies to a single symbol in the intermediate
string. So for example, if you apply the rule S ⟶ (S)
to the intermediate string SS, only one of the symbols
gets parentheses around it (you are free to choose which one):
S(S) or (S)S. If you want to apply the
same rule to both symbols, you can, you just have to apply the same
rule twice, which gives (S)(S).
Try working out a sequence of rules to
obtain (())[]. To check the correct answer, you can
look at the example solution below but don't look before you've
tried it by yourself.
Apply the following sequence of rules:
S ⟶ SSto the start symbolS: resultSSS ⟶ (S)to the firstS: result(S)SS ⟶ (S)to the firstS: result((S))SS ⟶to the firstS: result(())SS ⟶ [S]to the onlyS: result(())[S]S ⟶to the onlyS: result(())[]
Parsing
Efficient algorithms for deciding whether a given string belongs to a given context-free language exist. They are based on parsing, which means the construction of a parse tree. The parse tree represents the hierarchical structure of the string. An example parse tree is shown below.
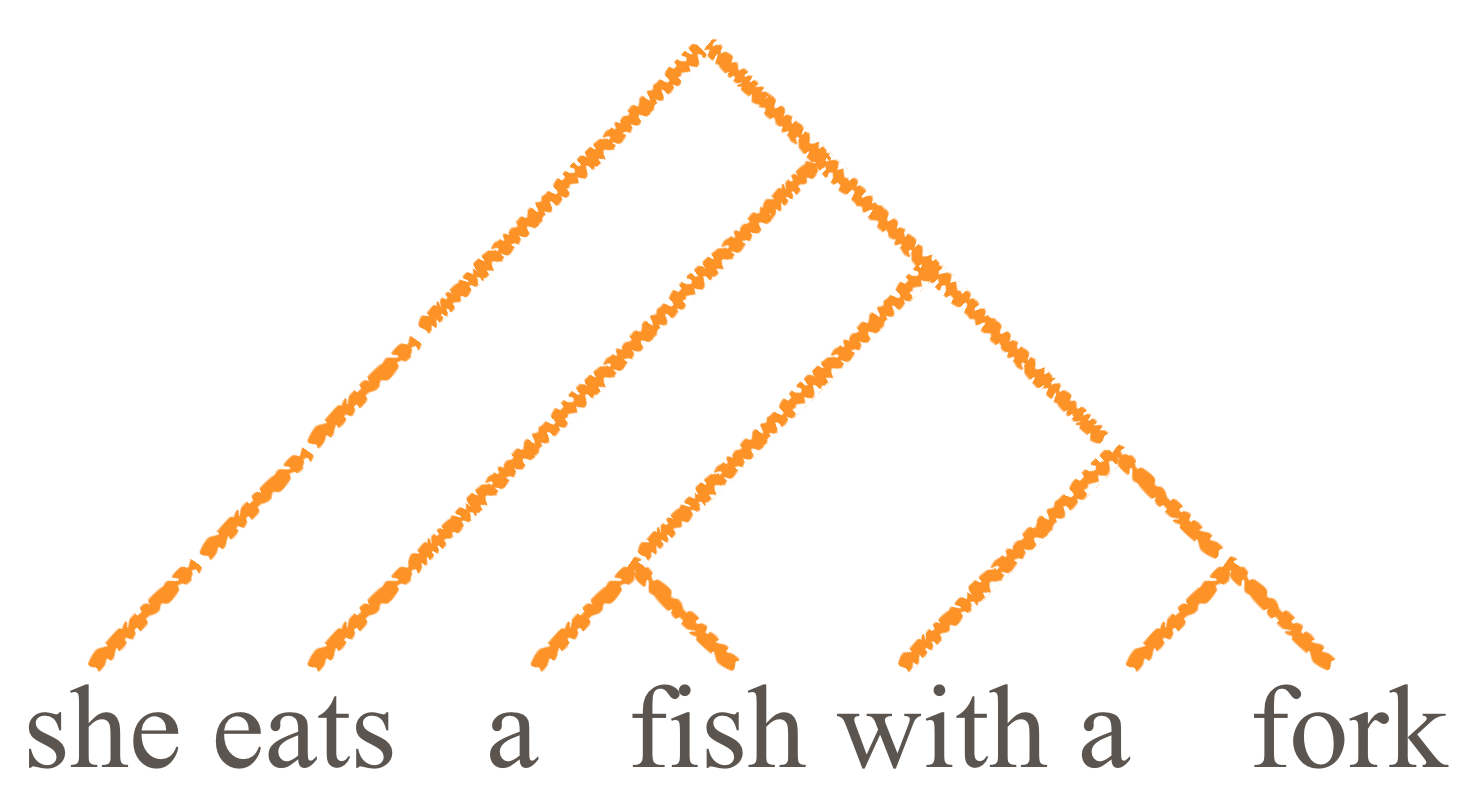
In the above tree, the sentence "she eats a fish with a fork" has two main components: "she" and the rest of the sentence. The rest of the sentence likewise has two parts: "eats" and "a fish with a fork". The interpretation of this parse tree is that the object of eating is a fish that has a fork. (A possible but rather unusual scenario as fish rarely have forks.)
The above parse tree demonstrates the ambiguity of natural language, which is a challenge to AI applications. A potential solution in such scenarios is to use the semantics of the words and to attach word-dependent probabilities to different rules. This could for instance suggest that the probability of eating something with a fork is a more probable construction than a fish that has a fork. This method is called lexicalized parsing.
CYK algorithm
The Cooke–Younger–Kasami (CYK) algorithm is an O(mn3) time algorithm for parsing context-free languages. Here n refers to the number of words in the sentence, and m is the number of rules in the grammar. It is based on dynamic programming where the sentence is parsed by first processing short substrings (sub-sentences) that form a part of the whole, and combining the results to obtain a parse tree for the whole sentence.
To present the idea of the CYK algorihtm, we'll start with an example.
In our naive example grammar, we have the following set of rules:
S ⟶ NP VP
VP ⟶ V NP
VP ⟶ VP ADV
VP ⟶ V
NP ⟶ N
V ⟶ fish
N ⟶ Robots
N ⟶ fish
ADV ⟶ today
The starting symbol is again S, which stands for both 'start' as well
as 'sentence'. NP stands for noun-phrase, VP for verb-phrase, V and N
are of course verb and noun respectively, and finally ADV stands
for adverb (a specifier that says how or when something
is done).
The terminal symbols — note that here we consider words as atomic symbols, and not sequences of characters — are 'fish', 'Robots', and 'today'. Also note that the word 'fish' is both a verb (V) and a noun (N).
CYK table
A fundamental data structure in CYK is a triangular table that is usually depicted as a lower-triangular (or upper-triangular) matrix of size n × n. The completed table for our small example is below. This would be the result of running the CYK algorithm with the sentence "Robots fish fish today" as input.
| S (1,4) | |||
| S (1,3) | S,VP (2,4) | ||
| S (1,2) | S,VP (2,3) | VP (3,4) | |
|
N,NP (1,1) |
V,N,VP,NP (2,2) |
V,N,VP,NP (3,3) |
ADV (4,4) |
First of all, pay attention to the numbering scheme of the table cells. Each cell is numbered as shown in the top right corner: (1,4), (1,3), etc. The numbering may be slighly confusing since it doesn't follow the more usual (row, column) numbering. Instead, the numbers given the start and the end of the sub-sentence that the cell corresponds to. For example, the cell (1,4) refers to the whole sentence, i.e., words 1–4, while the cell (2,3) refers to the words fish fish, i.e., words 2–3.
After the algorihtm is completed, the contents of the cells in the CYK table correspond to the possible interpretations (if any) of the words in question in terms of different non-terminals. For example, the words fish fish are seen to have two interpretations: as a sentence (S) and as a verb-phrase (VP). This is because we can generate these two words by starting either from S or VP.
Just to keep you on your toes, let's make sure you understand what we mean when we say that fish fish can be generated from S and VP. That is, give a list of rules to generate these two words starting from S, and then do the same starting from VP.
Starting from S, we first apply the only rule that has S on the left, i.e., S ⟶ NP VP. Then apply NP ⟶ N to obtain N VP, and VP ⟶ V, to obtain N V. Finally, apply N ⟶ fish and V ⟶ fish to obtain "fish fish".
Starting from VP, apply VP ⟶ V NP. Then, apply V ⟶ fish, NP ⟶ N, and finally N ⟶ fish.
The interpretations of "fish fish" as a sentence (S) and a verb-phrase (VP) are quite different. In the former, the first 'fish' is generated through NP and N, i.e., the first word is considered a noun, while the second 'fish' is generated through VP and V, i.e., it is considered a verb. So there are some sea creatures (the first 'fish') that try to catch other sea creatures. On the other hand, in the VP interpretation, the first 'fish' is generated through V, so it is a verb, and the second 'fish' is a noun. This time the interpretation is that what is going on is an attempt to catch some sea creatures but it is not explicated who is fishing since the words only form a verb-phrase that can be combined with a subject noun.
The other elements in the table have similar interpretations. The above example is actually somewhat unusual in the sense that all sub-sentences can be parsed and therefore, all cells in the table contain at least one non-terminal symbol. This is by no means a general property. For example, "Robots Robots Robots" wouldn't have an interpretation as a valid sub-sentence in a grammatical sentence, and the table for a sentence containing these words (consecutively) would have empty cells.
Operation of the algorithm
The CYK algorithm operates by processing one row of the table at a time, starting from the bottom row which corresponds to one-word sub-sentences, and working its way to the top node that corresponds to the whole sentence. This shows the dynamic programming nature of the algorithm: the short sub-sentences are parsed first and used in parsing the longer sub-sentences and whole sentence.
More specifically, the algorithm tries to find on each row any rules that could have generated the corresponding symbols. On the bottom row, we can start by finding rules that could have generated each individual word. So for example, we notice that the word 'Robots' could have been generated (only) by the rule N ⟶ Robots, and so we add N into the cell (1,1). Likewise we add both V and N into the cells (2,2) and (3,3) because the word 'fish' could have been generated from either V or N. At this stage, the CYK table would look as follows:
| (1,4) | |||
| (1,3) | (2,4) | ||
| (1,2) | (2,3) | (3,4) | |
|
N (1,1) |
V,N (2,2) |
V,N (3,3) |
ADV (4,4) |
The same procedure is repeated as long as there are rules that we haven't applied yet in a given cell. This implies that we will also apply the rule NP ⟶ N in the cell (1,1) after having added the symbol N in it, etc.
Only after we have made sure that no other rules can be applied on the bottom row, we move one row up. Now we will also consider binary rules where the right side has two symbols. A binary rule can be applied in a given cell if the two symbols on the right side of the rule are found in cells that correspond to splitting the sub-sentence in the current cell into two consecutive parts. This means that in cell (1,2) for example, we can split the sub-sentence 'Robots fish' into two parts that correspond to cell (1,1) and (2,2) respectively. As these two cells contain the symbols NP and VP, and the rule S ⟶ NP VP contains exactly these symbols on the right side, we can add the symbol S on the left side of the rule into the cell (1,2).
| (1,4) | |||
| (1,3) | (2,4) | ||
| S (1,2) | (2,3) | (3,4) | |
|
N,NP (1,1) |
V,N,VP,NP (2,2) |
V,N,VP,NP (3,3) |
ADV (4,4) |
This process is iterated until again we can't apply more rules on the second row from the bottom, after which we move one level up. This is repeated on all levels until we reach the top node and the algorithm terminates.
Pseudocode for the CYK algorithm is as follows:
1: T = n x n array of empty lists
2: for i in 1,...,n:
3: T[i,i] = [word[i]]
4: for len = 0,...,n-1:
5: while rule can be applied:
6: if x ⟶ T[i,i+len] for some x:
7: add x in T[i,i+len]
8: if x ⟶ T[i,i+k] T[i+k+1,i+len] for some k,x:
9: add x in T[i,i+len]
The variable len refers to the length of the
sub-sentence being processed in terms of the distance between
its start and end. So for example, in the first iteration of the
loop on lines 4–9, we process individual words in cell
(1,1), (2,2), ..., (7,7), and so len = 0.
The if statements on lines 6 and 8 check whether there
exists a rule where the symbol(s) on the right side are found in the
specific cells given in the pseudodode (T[i,i+len] on
line 6, or T[i,i+k] and T[i+k+1,i+len] on
line 8). If this is the case, then the symbol x on the
left side of the rule is added into
cell T[i,i+len]. This means that the sub-sentence
(i,i+len) can be generated from symbol x.
Constructing parse trees from the CYK table
What is not shown in the pseudocode, is that we should also keep track of how we obtained each entry in the CYK table. Each time we apply a rule, we should therefore store the symbol(s) in the other cell(s) where the symbols on the right side of the rule were found. For example, in the very last step of the algorithm in the above example, we would store that the symbol S was obtained because we found NP in cell (1,1) and VP in cell (2,4), etc. Note that it is important to store references not only the cell but also the individual symbols that were used.
If there are multiple ways to obtain a given symbol in a given cell, then we store information about each possible way as a separate set of references. These different ways will correspond to different ways to parse the sentence.
Having stored the references to the symbols that enabled us to obtain the symbols in the higher rows of the table, we can reconstruct parse trees by traversing the references between the symbols, starting from the symbol S in top node (if one exists; if there is no S in the top node, the sentence is invalid/not grammatical, and it doesn't belong to the language at all).
In the above example there should be only one possible parse tree but the lecture slides and the next exercise show cases where there are more than one.
Your task is to parse the sentence "Google bought DeepMind for
$500M in January" using the CYK algorithm. Use the following
grammar rules:
S ⟶ NP VP
NP ⟶ NP PP
VP ⟶ VP PP
VP ⟶ V NP
VP ⟶ V
PP ⟶ P NP
NP ⟶ N
N ⟶ Google
N ⟶ DeepMind
N ⟶ $500M
N ⟶ January
V ⟶ bought
P ⟶ for
P ⟶ in
You should fill in the CYK table, according to the above instructions. The two bottom rows are given to get you started nicely.
| S | VP | PP | PP | |||
|
N,NP |
V,VP bought |
N,NP DeepMind |
P for |
N,NP $500M |
P in |
N,NP January |
So for example, in the first cell in the third row from the bottom, you should add S due to the rule S ⟶ NP VP because we have NP in cell (1,1) and VP in cell (2,3).
- Complete the CYK table.
- Construct all the parse trees from the CYK table by keeping track of which nodes we used to obtain each entry in the table. Which of them is most likely to be the correct one?
Hint: You'll probably want to start numbering the cells using the numbering scheme explained above.
Applications of NLP
You'll find a template for this exercise in TMC.
-
Implement method
extractSubjectin classExtractor. The input will be a parse tree of a sentence. You should try to identify the subject of the sentence (who/what does something). One heuristic method that doesn't always work, but is close enough, is as follows:- Assume that the root node of the parse tree, S, has children NP (noun phrase) and VP (verb phrase). If this is not the case, you can skip the sentence and return null.
- Choose the child NP.
- The subject can be assumed to a noun in the NP subtree (see example below). You can identify nouns by the POS-tag which should be either NN, NNP, NNPS, or NNS.
- Use breadth-first search to find the noun closest to the root.
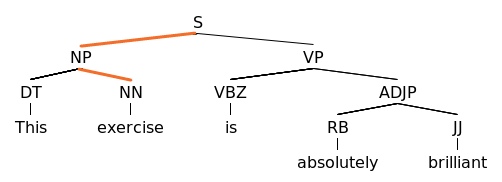
The TMC template has tests to verify your solution.
-
Next, implement the following logic in method
mainin classMainusing the tools available in classNLPUtils: The template has ready-made functionality for iterating through all sentences in Franz Kafka's The Metamorphosis. Reject all sentences that don't contain the word "Gregor".
-
For all remaining sentences, produce a
parsing tree. (If the parsing fails, reject the sentence.) Use the
method you implemented in item 1 to identify the subject of the
sentence. Print out all sentences where the subject is "Gregor".
- Use the output to find out what Gregor does in a similar spirit as this cool applet. (No, you don't have to make a visualization!)
Hint: In item 2, you can use method contains.
Note added on Oct 6, 8.10pm: there was a bug in the exercise
template that has now been fixed. The problem manifested itself in
a java.util.zip.ZipException. Unfortunately the TMC
plugin is unable to correct the problem in template updates so if
you're having this problem, you'll have to delete the NLP exercise
folder from you computer and download the exercise again. If you're
using Netbeans, the NLP folder should be in your NetBeansProjects.