What is AI?
In this first part, we will discuss what we mean when we talk about AI. It turns out that there is no exact definition at all, but that the field is rather being redefined at all times.
We will also briefly discuss the philosophical aspects of AI: whether intelligent behavior implies or requires the existence of a ''mind'', and in what extent is consciousness replicable as a computational process. However, this course is first and foremost focused on building practically useful AI tools, and we will quickly push considerations about consciousness aside as they tend to be only in the way when designing working solutions to real problems.
The first technical topic, also covered in Part 1, is problem-solving by search.
| Theme | Objectives (after the course, you ...) |
|---|---|
| Philosophy and history of AI |
|
| Games and search (will be continued) |
|
A (Very) Brief History of AI
Artificial Intelligence (AI) is a subdiscipline of Computer Science. Indeed, it is arguably as old as Computer Science itself: Alan Turing (1912-1954) proposed the Turing machine -- the formal model underlying the theory of computation -- as a model with equivalent capacity to carry out calculations as a human being (ignoring resource constraints on either side).
The term AI was proposed by John McCarthy (1927-2011) -- often referred to as the Father of AI -- as the topic of a summer seminar, known as Dartmouth conference held in 1956 at Dartmouth College.
As computers developed to the level where it was feasible to experiment with practical AI algorithms in the 1940s and 1950s, the most distinctive AI problems were games. Games provided a convenient restricted domain that could be formalized easily. Board games such as checkers, chess, and (recently quite prominently) Go, have inspired countless researchers, and continue to do so.
Closely related to games, search and planning algorithms were an area where AI lead to great advances in the 1960s: in a little while, we will be able to admire the beauty of, for example, the A* search algorithm and alpha-beta pruning, and apply them to solve AI problems.
There's an old (geeky) joke that AI is defined as ''cool things that computer can't do.'' The joke is that under this definition, AI can never make any progress: as soon as we find a way to do something cool with a computer, it stops being an AI problem.
However, there is an element of truth in the definition in the sense that fifty years ago, for instance, search and planning algorithms were considered to belong to the domain of AI. Nowadays algorithms such as breadth-first and depth-first search, and A*, are thought (and taught) as belonging to Data Structures and Algorithms.
The history of AI, just like many other fields of science, has witnessed the coming and going (and coming back and going again, etc.) of various different paradigms. Typically, a particular paradigm is adopted by most of the research community and ultra-optimistic estimates of progress in the near-future are provided. All such scenarios so far have ended up running into unsurmountable, unexpected problems and the interest has died out. For example, in the 1960s artificial neural networks were widely believed to solve all AI problems by imitating the learning mechanisms in the nature (such as the human central nervous system and the brain, in particular). However, certain negative results about the expressibility of certain neural computation models quickly lead to pessimism and an AI winter followed.
The 1980s brought a new wave of AI methods based on logic-based methods. So called expert systems, manipulating knowledge elicited from domain experts, such as medical doctors, showed great promise by solving nicely contained, well-defined ''toy problems'', but turned out to fail every time when they were deployed in more complex, real-world problems. The second (or the third, depending on the counting) AI winter lasted from the late 1980s until the mid-1990s.
Currently, since the turn of the millennium, AI has been on the rise again. In the late 1990s, the ''classical'' or ''Good Old-Fashioned AI'' (GOFAI) that addressed crisp, clearly defined, and isolated problems begun to be replaced by so called ''modern AI'' (in lack of a better name). Modern AI introduced methods that were able to handle uncertain and imprecise information, most notably by probabilistic methods, and which had the great advantage that it was designed to work in the real world. The rise of modern AI has continued until present day, further boosted by the come-back of neural networks under the label Deep Learning.
Whether the history will repeat itself, and the current boom will be once again followed by an AI winter, is a matter that only time can tell. Even if it does, the significance of AI in the society is going to stay. Today, we live our life surrounded by AI, most of the time happily unaware of it: the music that we listen, the products that we buy online, the movies and series that we watch, our routes of transportation, and the information that we have available, are all influenced more and more by AI.
No wonder that you have decided to learn more about AI!
Being able to apply AI methods and thus to be part of the progress of AI is a great way to change the world for the better. And even if you wouldn't aspire to become an AI researcher or developer, it is almost your duty as a citizen to understand at least the fundamentals of AI so that you can better use it: be aware of its limitations and enjoy all the goodies it can provide.
On the Philosophy of AI
The best known contribution to AI by Turing is his imitation game, which later became known as the Turing test. In the test, a human interrogator interacts with two players, A and B, by exchanging written messages (in a ''chat''). If the interrogator cannot determine which player, A or B, is a computer and which is a human, the computer is said to pass the test. The argument is that if a computer is indistinguishable from a human in a general natural language conversation, then it must have reached human-level intelligence.
Turing's argument that whether a being is intelligent or not can be decided based on the behavior it exhibits has been challenged by some. The best known counter-argument is John Searle's Chinese Room thought experiment. Searle descibes an experiment where a person who doesn't know Chinese is locked in a room. Outside the room is a person who can slip notes written in Chinese inside the room through a mail slot. The person inside the room is given a large manual where she can find detailed instructions for responding to the notes she receives from the outside.
Searle argued that that even if the person outside the room gets the impression that he is in a conversation with another Chinese-speaking person, the person inside the room does not understand Chinese. Likewise, his argument continues, even if a machine behaves in an intelligent manner, for example, by passing the Turing test, it doesn't follow that it is intelligent or that it has a ''mind'' in the way that a human has. The word ''intelligent'' can also be replaced by the word ''self-conscious'' and a similar argument can be made.
The definition of intelligence, natural or artificial, and consciousness appears to be extremely evasive and leads to apparently never-ending discourse. In an intellectual company, with plenty of good Burgundy (Bordeaux will also do), this discussion can be quite enjoyable. However, as John McCarthy pointed out, the philosophy of AI is ''unlikely to have any more effect on the practice of AI research than philosophy of science generally has on the practice of science.''
Your first exercise will be to take a look into current AI research. Find an AI-related scientific article from recent years. Pick one that you can understand, by and large: try to see what the problem statement, methodology, and conclusions are, roughly.
Good places to start your search are, e.g., the proceedings of AAAI, IJCAI, and ECAI conferences or magazine-style publications that may be somewhat less technical and intended for broader audiences, such as AI Magazine. However, please try to avoid articles that are overly polemic and superficial -- the idea is to take a look at academic AI, and ignore the BS on my Facebook feed...
Read the article through and answer the following questions:
- What is the research problem?
- Is the topic related to the topics of this course?
- Generally speaking, what impression does the article give about modern AI research? Reflect on the history and philosophy of AI discussed above.
- What studies would be needed to undertand the article in detail?
- Bonus question: Considering the article you chose, how relevant is the ''Terminator'' scenario where AI becomes self-conscious and turns against the humankind?
Solving the above exercise gives you one point (1p). Some exercises such as Ex1.4 below require a bit more effort, and they may give you two point (2p). This is indicated in the exercise heading as above.
Solutions to ''pencil-and-paper'' exercises such as this one are returned at the exercise sessions where you should make sure to mark completed exercises on the sheet that is circulated in the beginning.
For programming exercises, you will be able to use the TMC system which helps you see whether the solution is correct. However, even the TMC exercises are marked at the exercise session. In other words, it is not enough to upload the programming exercises on TMC to get the points.
We will now put our wine glasses aside, roll our sleeves, and turn our minds toward more practical considerations. Let's jump to our first technical topic: search and problem-solving.
Search and Problem-Solving
Many problems can be phrased as search problems. Formulating the search space and choosing an appropriate search algorithm often requires careful thinking and is an important skill for an AI developer.
Basic tree and network traversal algorithms belong to the course prerequisites, and you should already be familiar with breadth-first, depth-first, and best-first search (including its special case, the A* algorithm). If you forgot the details right after taking the exam, no need to worry: we will revisit them below.
Breadth-First and Depth-First Search
To set the scene for discussing more advanced search algorithms, such as A*, we begin by defining a generic templace for search algorithms.
1: search(start_node):
2: node_list = list() # empty list (queue/stack/...)
3: visited = set() # empty set
4: add start_node to node_list
5: while list is not empty:
6: node = node_list.first() # pick the next node to visit
7: remove node from node_list
8: if node not in visited:
9: visited.add(node)
10: if goal_node(node):
11: return node # goal found
12: add node.neighbors() to node_list
13: end if
14: end while
15: return None # no goal found
In the above pseudo-code, node_list holds the nodes to
be visited. The order in which nodes are taken from the list
by node_list.first() determines the behavior of the
search: a queue (first-in, first-out) results in breadth-first
search (BFS) and a stack (last-in, first-out) results
in depth-first search (DFS).
In case of BFS, the operation of adding a node to the list (queue) is enqueue and the operation of removing the node that was added first is dequeue.
In the case of DFS, the operation of adding a node to the list (stack) is push, and the operation of removing the node that was added last is pop.
The test goal_node tests whether the goal or target node
of the search is found. Sometimes the problem is simply to traverse the
network (or tree) completely in a particular order, and there is no
goal node. In that case, goal_node simply always returns
False.
You may have seen different versions of search algorithms and wonder why this isn't exactly like them. In particular, many students have been taught the recursive version of DFS, which indeed is very simple and elegant.
You need not worry about the difference too much. Here we simply wanted to use the same template for all search methods. The behavior is always the same: for example, the recursive version of DFS actually uses a stack to store the state of the search and pops the next state from the stack just like our non-recursive version above.
It is quite straighforward to see that BFS will always return the path with the fewest transitions to a goal node: if node A is nearer to the starting node than node B, the search is expanded to node A earlier than to B. You can think of the BFS search as a frontier of nodes that gradually progresses outwards from the starting node, so that all nodes at a certain number of steps away are expanded before moving one step ahead.
DFS doesn't guarantee that the shortest path be found, but in some cases it doesn't matter. See the lecture slides for an example of solving Sudoku puzzles using DFS. Can you think of a reason by DFS is a better choice in that problem that BFS?
Here's a simple exercise to make sure BFS and DFS are clear enough.
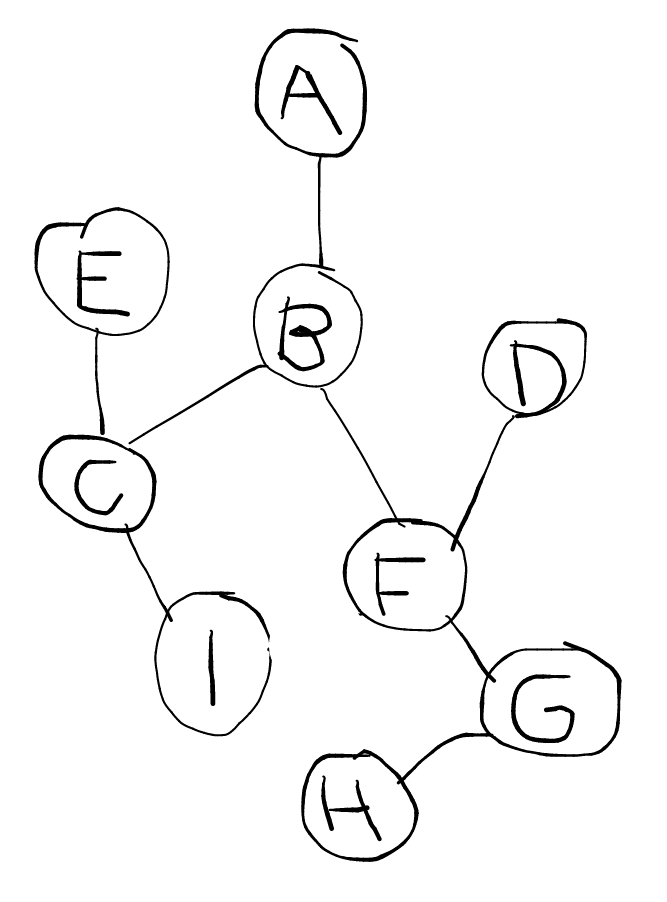 Consider the (cute) network on the right.
Consider the (cute) network on the right.
- Simulate (on pencil-and-paper) breadth-first search starting from node A when the goal node is H.
- Do the same with depth-first search.
As we discussed above while drinking red wine, search algorithms don't necessarily feel like being very cool AI methods. However, as the next two exercises demonstrate, they can actually be used to solve tasks that -- most of us would admit -- require intelligence.
Let's play. Solve the well-known puzzle Towers of Hanoi. The puzzle involves three pegs, and three discs: one large, one medium-sized, and one small. (Actually, there can be any number of discs but for the pencil-and-paper exercise, three is plenty.)
In the initial state, all three discs are stacked in the first (leftmost) peg. The goal is to move the discs to the third peg. You can only move one disc at a time, and it is not allowed to put a larger disc on top of a smaller disc.
This pretty picture shows the initial state and the goal state:
initial | | | goal | | |
state: --- | | state: | | ---
----- | | | | -----
===================== ====================
- Draw a network diagram where the nodes are all the states that can be achieved from the initial state, and the edges represent allowed transitions (moves) between them.
- Simulate breadth-first search in the state space. Note:You don't have to explicitly specify the contents of the queue at each step. It is enough to provide the traversal order.
- Do the same with depth-first search.
- Compare the search methods on two accounts: a) what is the length of the path that each algorithm finds, b) what is the number of states visited during the search. Note: It is important to note that these are two different things (the length of the path, and the number of visited states.)
- Does the result depend on the order in which the neighbors of each node are added into the list?
A bonus exercise: Try to see the symmetry in the state diagram, and generalize to n > 3 discs.
Now it's time for this week's highlight: implementing a real AI application. It will require some effort, and programming can often be slow and frustrating, but stay focused, don't hesitate to ask for help, and you'll be ok. Next week, we'll continue working on the same application, so your hard work now will make your life easier next week.
The task is to read Helsinki tram network -- outdated, we're afraid so it's not going to be super useful -- data from a file that we give. Implement a program that takes as input the starting point A and the destination B, and finds the route from A to B with the fewest stops between them. It is quite straightforward to show that such a route can be found by BFS.
We provide a Java template that includes a Stop class
which can retrieve the neighboring stops. These are the valid
transitions in the state space.
You can also start from scratch and implement your solution in
your favorite programming language. In that case, simply take the
network.json file, which is pretty self-explanatory.
A hint to python programmers: import json.
If using the Java template (others may find these instructions useful too):
- Download and open the Maven project in a suitable development environment (e.g., Netbeans).
-
Implement the search algorithm in
class
TravelPlanner. -
In order to be able to
extract the resulting route after the search ends, construct a
backward-linked list of
Stopobjects as the stops are added into the queue, each of which has a pointer to the previous stop from which the search arrived at the stop in question. This way, once you arrive at the destination, you can start backtracking along the shortest path until the beginning. - Test your solution on TMC to see that your TravelPlanner works as it should and doesn't send you on a detour.
If you don't use TMC, you can test by setting the starting stop as
1250429(Metsolantie) and the destination as
1121480(Urheilutalo). The path (listed backwards) with
the fewest stops is as follows:
1121480(Urheilutalo)[DESTINATION] -> 1121438(Brahenkatu) -> 1220414(Roineentie) -> 1220416(Hattulantie) -> 1220418(Rautalammintie) -> 1220420(Mäkelänrinne) -> 1220426(Uintikeskus) -> 1173416(Pyöräilystadion) -> 1173423(Koskelantie) -> 1250425(Kimmontie) -> 1250427(Käpylänaukio) ->1250429(Metsolantie)[START]
Alright. So far, we've refreshed BFS and DFS in our memory and applied them to solve some pretty cool applications. To go to the next level, we'll bring out the big guns, and talk about best-first search (which is not abbreviated in order to avoid confusing it with breadth-first search) and the A* algorithm.
Informed Search and A*
Often, different transitions in the state space are associated with different costs. For example, doing a task could take any time between a few seconds and several hours. Or the distance between any two tram stops could be between a hundred meters and half a kilometer. Thus, just counting the number of transitions is not enough.
To be able to take into account different costs, we can apply best-first search, where the node list is ordered by a given criterion. For instance, we can choose to always prefer to expand a path with the minimal incurred total cost counting from the starting node. This is known as Dijkstra's algorithm. In the special case where the cost of all transitions is constant, Dijkstra's algorithm is equivalent to BFS.
The generic search algorithm template above still applies, but in best-first search, the data structure that holds the nodes on the node list is a priority queue. When adding nodes to the priority queue on line 14, they are given a cost or a value that is then used to order the nodes in the queue. (Depending on the application and whether the aim is to minimize or maximize the value, the queue can be a min-priority queue or a max-priority queue.)
If you play around with the PathFinding applet for a while, using BFS or Dijkstra's algorithm, you will quickly notice a problem. The search spreads out to all directions symmetrically without any preference towards the goal.
This is understandable since the choice of the next node to expand has nothing to do with the goal. However, if we have some way of measuring, even approximately, which nodes are nearer to the goal, we can use it to guide the search and save a lot of effort by never having to explore unpromising paths. This is the idea behind informed search.
Informed search relies on having access to a heuristic that associates with each node an estimate of the remaining cost from the node to the goal. This can be, for example, the distance between the node and the goal measured as the crow flies (i.e., Euclidean or geodesic distance -- or in plain words, a straight-line distance).
Using the heuristic as the criterion for ordering the nodes in the (min-)priority queue will always expand nodes that appear to be nearer to the goal according to the heuristic. However, this may lead the search astray because the incurred cost of the path is not taken into account. A balanced search that takes both the incurred cost as well as the estimated remaining cost into account is obtained by ordering the (min-)priority queue by
f(node, cost) = cost + h(node),
where cost is the value associated with the node when
it is added to the priority queue, and h(node) is the
heuristic value, i.e., an estimate of the remaining cost
from node to the goal. This is the A* search.
If you try it on
the PathFinding
applet, you will immediately see that it wipes the floor with
other, uninformed search methods.
This is the end of Part 1. You should complete this part during the first week of the course. (The exercise sessions where the problems are discussed are held the following week.) In the next part, we will study two topics: Games, and Reasoning under Uncertainty (which we'll continue for some time). To get to Part 2, click here or use the navigation bar at the top of the page.