Tuntee käsitteet indeksi, transaktio ja tietokannan eheys. Osaa luoda useampaa tietokantataulua käyttävän ja muokkaavan web-sovelluksen. Osaa siirtää web-sovelluksen verkkoon, missä se on kaikkien nähtävillä.
Tietokantakyselyiden tehokkuudesta
Tietokantaan tehtävä SQL-kielinen kysely voidaan suorittaa useammalla eri tavalla. Kyselyn suoritus voi käydä läpi tietokantataulun jokaisen rivin, se voi tarkastella vain rajattua osaa tietokantataulun riveistä, tai suoritus voi olla useamman taulun tapauksessa jonkinlainen yhdistelmä edellisiä. Kyselystrategia perustuu tietokannanhallintajärjestelmän sisäisen kyselynoptimoijan sekä tietokantatauluihin määriteltyjen ominaisuuksien kuten indeksien perusteella.
Tietokantakyselyn tarkastelu
Tietokantakyselyiden suoritusstrategiaa voi tarkastella tietokannanhallintajärjestelmäkohtaisen apukyselyn avulla. SQLitessä kyselyn sisältöön pääsee kommennolla EXPLAIN QUERY PLAN, jota seuraa konkreettinen kysely. Suoritusstrategia sisältää tiedon läpikäytävistä tietokannoista sekä kyselyn muodosta. Kyselyn muoto on joko "SCAN" tai "SEARCH". Muoto SCAN käy koko tietokantataulun läpi ja SEARCH tarkastelee tietokantatauluun liittyvää indeksiä.
Tarkastellaan tätä konkreettisen esimerkin kautta. Oletetaan, että käytössämme on tietokanta, jossa on seuraavat tietokantataulut.
CREATE TABLE Asiakas (
id integer PRIMARY KEY,
nimi varchar(200),
puhelinnumero varchar(20),
katuosoite varcar(50),
postinumero integer,
postitoimipaikka varchar(20)
);
CREATE TABLE Tilaus (
id integer PRIMARY KEY,
asiakas_id integer,
aika date,
kuljetustapa varchar(40),
vastaanotettu boolean,
toimitettu boolean,
FOREIGN KEY (asiakas_id) REFERENCES Asiakas(id)
);
Jos haluamme listata asiakkaiden nimet ja puhelinnumerot, teemme kyselyn "SELECT nimi, puhelinnumero FROM Asiakas". Strategia on selvä -- käydään koko tietokantataulu läpi. Ensimmäisessä esimerkissä kytketään lisäksi SQLiten otsikot päälle ja vaihdetaan tulostusmuotoa kolumnimuotoon. Alla olevissa esimerkeissä on lisäksi käytetty .width -komentoa tulostuksen leveyden sovittamiseksi.
sqlite> .headers on sqlite> .mode column sqlite> EXPLAIN QUERY PLAN SELECT nimi, puhelinnumero FROM Asiakas; selectid order from detail -------- ----- ---- ------------------ 0 0 0 SCAN TABLE Asiakas
Vastaava strategia liittyy myös tietyn nimisen asiakkaan etsimiseen. Alla kuvatussa esimerkissä tarkastellaan kyselyä, missä etsitään Cobb-nimistä asiakasta.
sqlite> EXPLAIN QUERY PLAN SELECT nimi, puhelinnumero
FROM Asiakas WHERE nimi = 'Cobb';
selectid order from detail
-------- ----- ---- ------------------
0 0 0 SCAN TABLE Asiakas
Myös Tilaus-taulun tietojen listaaminen vaatii koko tietokantataulun läpikäynnin. Alla listataan tilaukset, jotka on jo toimitettu.
sqlite> EXPLAIN QUERY PLAN SELECT * FROM Tilaus
WHERE toimitettu = 1;
selectid order from detail
-------- ----- ---- -----------------
0 0 0 SCAN TABLE Tilaus
Tarkastellaan seuraavaksi hieman monimutkaisempaa kyselyä, missä tulostetaan niiden asiakkaiden nimet, jotka ovat tehneet vähintään yhden tilauksen.
sqlite> EXPLAIN QUERY PLAN SELECT nimi, puhelinnumero
FROM Asiakas JOIN Tilaus
ON Asiakas.id = Tilaus.asiakas_id;
selectid order from detail
-------- ----- ---- --------------------------------------------------------
0 0 1 SCAN TABLE Tilaus
0 1 0 SEARCH TABLE Asiakas USING INTEGER PRIMARY KEY (rowid=?)
Kysely onkin nyt erilainen. Kyselyssä käydään ensin läpi koko taulu Tilaus, jonka jälkeen etsitään tietokantataulusta Asiakas rivejä asiakas-taulun pääavaimen perusteella. Entä jos tietokantataulu Asiakas olisikin määritelty siten, että kenttä id ei olisi pääavain?
CREATE TABLE Asiakas (
id integer,
nimi varchar(200),
puhelinnumero varchar(20),
katuosoite varcar(50),
postinumero integer,
postitoimipaikka varchar(20)
);
sqlite> EXPLAIN QUERY PLAN SELECT nimi, puhelinnumero
FROM Asiakas JOIN Tilaus
ON Asiakas.id = Tilaus.asiakas_id;
selectid order from detail
-------- ----- ---- -----------------------------------------------------------------
0 0 0 SCAN TABLE Asiakas
0 1 1 SEARCH TABLE Tilaus USING AUTOMATIC COVERING INDEX (asiakas_id=?)
Tietokannanhallintajärjestelmä vaihtaa läpikäytävien taulujen järjestystyä. Nyt kysely käy ensin läpi koko Asiakas-taulun, ja etsii tämän jälkeen Tilaus-taulusta tietoa automaattisesti luodun indeksin perusteella.
Indeksit eli hakua nopeuttavat tietorakenteet
Indeksit ovat tietokantatauluista erillisiä yhden tai useamman sarakkeen tiedoista koostuvia tietorakenteita, jotka viittaavat tietokantataulun riveihin. Indeksirakenteita on useita erilaisia, mm. hajautustaulut ja puurakenteet. Indeksien tavoite on käytännössä -- tietokantojen yhteydessä -- tietokantakyselyiden nopeuttaminen.
Indeksiä voi ajatella perinteikkään kirjaston korttiluettelona. Kirjaston tiskille mentäessä ja tiettyä kirjaa kysyttäessä, kirjastovirkailija käy läpi kirjan nimen perusteella aakkostettuja kortteja. Koska nimet ovat aakkosjärjestyksessä, jokaista korttia ei tarvitse tarkastella tiettyä kirjaa etsittäessä. Kortissa on tieto kirjan konkreettisesta paikasta kirjastossa -- kun kortti löytyy, kirjan voi hakea. Jos kirjan nimen sijaan kirjaa etsitään kirjoittajan perusteella, tulee käyttää toista korttipakkaa, joka sisältää kirjoittajien nimet sekä mahdollisesti myös tiedon kirjojen nimistä. Jos kirjaa etsitään sisällön perusteella joudutaan huonolla tuurilla käymään jokainen fyysinen kirjaston kirja läpi.
Pohditaan tilannetta, missä miljardi riviä sisältävän taulun tiettyyn sarakkeeseen on määritelty indeksi. Oletetaan, että indeksi sisältää arvot järjestettynä. Tällöin, tiettyä arvoa haettaessa, voimme aloittaa keskimmäisestä arvosta -- jos haettava arvo on pienempi, tutkitaan "vasemmalla" olevaa puolikasta. Jos taas haettava arvo on suurempi, tutkitaan "oikealla" olevaa puolikasta. Alueen rajaaminen jatkuu niin pitkään, kunnes haettava arvo löytyy, tai rajaus päätyy tilanteeseen, missä tutkittavia arvoja ei enää ole. Tämä menetelmä -- puolitushaku tai binäärihaku lienee tuttu ohjelmointikursseilta.
Jos rivejä on yhteensä miljardi, voidaan ne jakaa kahteen osaan noin log2 1 000 000 000 kertaa, eli noin 30 kertaa. Jos oletamme, että arvoa ei löydy taulusta, tulee yhteensä tarkastella siis noin 30 riviä miljardin sijaan.
Indeksin määrittely tietokantataulun sarakkeelle tapahtuu tietokantataulun luomisen jälkeen komennolla CREATE INDEX, jota seuraa uuden indeksin nimi, avainsana ON, sekä taulu ja taulun sarakkeet, joille indeksi luodaan. Tietokannanhallintajärjestelmä luo tietokantataulun pääavaimelle ja viiteavaimille indeksit tyypillisesti automaattisesti.
Oletetaan, että sovelluksessamme asiakkaita haetaan usein nimen perusteella. Luodaan edellä kuvattuun Asiakas-taulun sarakkeelle nimi indeksi.
sqlite> CREATE INDEX idx_asiakas_nimi ON Asiakas (nimi);
Tarkastellaan aiemmin tehtyä Cobb-nimisen henkilön hakua uudelleen.
sqlite> EXPLAIN QUERY PLAN SELECT nimi, puhelinnumero FROM Asiakas
WHERE nimi = 'Cobb';
selectid order from detail
-------- ----- ---- ----------------------------------------------------------
0 0 0 SEARCH TABLE Asiakas USING INDEX idx_asiakas_nimi (nimi=?)
Strategia muuttuu edellisestä. Aiemmin tietokannanhallintajärjestelmän strategia on ollut koko tietokantataulun Asiakas läpikäynti, nyt tietoa haetaan indeksistä. Jos käytössä oleva indeksi olisi esimerkiksi hajautustaulu, tapahtuisi haku vakioajassa -- eli "tarkasteluja" tehtäisiin "yksi" riippumatta tietomäärästä -- tietorakenteisiin, niihin tehtäviin hakuihin sekä niiden tehokkuuksiin tutustutaan tarkemmin kurssilla tietorakenteet ja algoritmit.
Taulut ja sarakkeet, joihin indeksejä kannattaa harkita, liittyvät paljon suoritettuihin (ja hitaahkoihin) tietokantakyselyihin. Ensimmäiset askeleet liittyvät (1) tietokantataulujen pää- ja viiteavainten indeksien luomiseen, (2) hakuehtoihin liittyvien sarakkeiden indeksien luomiseen sekä (3) järjestysehtoihin liittyvien sarakkeiden indeksien lumiseen. Alla on kuvattuna eräs suoraviivainen prosessi tietokantataulun indeksien päättämiselle: lähtökohtana on kysely.
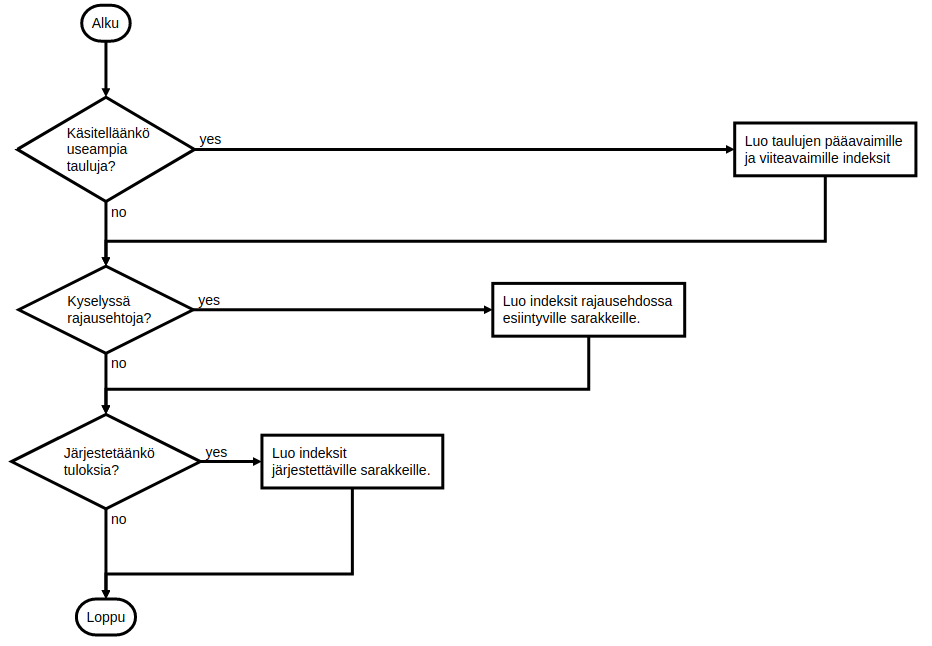
Indeksin luominen tietokantataululle luo tietorakenteen, jota käytetään tiedon hakemiseen. Jokaista indeksiä tulee päivittää myös tietokantaa muokkaavien operaatioiden yhteydessä, jotta indeksin tiedot ovat ajan tasalla. Käytännössä liiallinen indeksien luominen saattaa myös hidastaa sovelluksen toimintaa.
Välimuistit sovelluksissa
Kun tietokantaa käytetään osana annettua sovellusta (esimerkiksi web-sovellusta), sovelluksen vastuulla on tietokantakyselyiden tekeminen tietokannanhallintajärjestelmään. Jos sovellus on ainoa tietokannan käyttäjä (tietokantaa ei muokata muista järjestelmistä), ja jos merkittävä osa kyselyistä on toistuvia hakukyselyjä, voi sovellukseen rakentaa tietokannan toimintaa abstrahoiva välimuisti.
Välimuistissa on käytännössä kyse käsiteltävän tiedon tuomisesta lähemmäksi käyttäjää. Tietokantaa käyttävien sovellusten tapauksessa usein haettava tieto tuodaan sovelluksen muistiin, jolloin sovelluksen ei tarvitse hakea tietoa erikseen tietokannasta. Välimuisti tyhjennetään aina tietokannan päivityksen yhteydessä, jolloin käyttäjälle päätyvä tieto on aina ajan tasalla.
Yksinkertaisimmillaan välimuistitoteutus voi olla olemassaolevan Dao-toteutuksen kapselointi erilliseen Dao-toteutukseen. Oletetaan, että käytössämme on kolmannelta viikolta tuttu vaillinainen AsiakasDao-toteutus. Välimuistillisen toteutuksen luominen on melko suoraviivaista -- alla toteutuksessa muistetaan vain yksittäiset asiakkaat.
import java.util.*;
import java.sql.*;
public class CachedAsiakasDao extends AsiakasDao implements Dao<Asiakas, Integer> {
private HashMap<Integer, Asiakas> asiakkaatAvaimilla;
public CachedAsiakasDao(Database database) {
super(database);
this.asiakkaatAvaimilla = new HashMap<>();
}
@Override
public Asiakas findOne(Integer key) throws SQLException {
if (!asiakkaatAvaimilla.containsKey(key)) {
Asiakas asiakas = super.findOne(key);
asiakkaatAvaimilla.put(key, asiakas);
}
return asiakkaatAvaimilla.get(key);
}
@Override
public Asiakas saveOrUpdate(Asiakas object) throws SQLException {
Asiakas asiakas = super.saveOrUpdate(object);
asiakkaatAvaimilla.put(asiakas.getId(), asiakas);
return asiakas;
}
@Override
public void delete(Integer key) throws SQLException {
this.asiakkaatAvaimilla.removeKey(key);
return super.delete(key);
}
}
Jos asiakkaiden tietohin liittyvistä tietokantakyselyistä 99% on hakuoperaatioita, on merkittävässä osassa tapauksia tieto valmiiksi sovelluksen käytössä, jolloin tietokantaan ei tarvitse ottaa yhteyttä. Toisaalta, jos sovellus on sellainen, että merkittävä osa käsittelystä sisältää myös tietokannassa olevan tiedon muokkausoperaatioita, ei edellä kuvatusta välimuistista ole juurikaan hyötyä.
Tietokannan eheys ja transaktiot
Eheydellä viitataan tallennetun tiedon oikeellisuuteen. Tietokannanhallintajärjestelmä ylläpitää tietokannan eheyttä jatkuvasti. Esimerkiksi sarakkeen, joka on määritelty sisältämään vain numeerista tietoa, ei pitäisi sisältää tekstimuotoista tietoa. Vastaavasti viiteavainten tulee viitata aina olemassaolevaan tietoon.
Eheyden ylläpitämisen sekä kohta tutuksi tulevien tietokantatransaktioiden ymmärtämiseksi on hyvä tuntea tietokannan toimintaa sovellustasolla. Kurssin ensimmäisessä osassa tarkasteltiin tiedon käsittelyä tiedostoissa -- tietokanta käyttää kiintolevyä tiedon tallentamiseen, mutta rivien käsittely tapahtuu (keskus)muistissa. Kun riviä halutaan päivittää, se haetaan ensin kovalevyltä muistiin, päivitetään ja viedään takaisin levylle.
Keskusmuistin ongelma on se, että sen sisältö häviää esimerkiksi sähkökatkoksen sattuessa tai palvelimen kaatuessa. Havainnollistetaan ongelmallisuutta esimerkeillä:
- Annetaan kaikille yrityksen 1000000 kuukausipalkkaiselle työntekijälle 5% palkan korotus.
UPDATE Palkat SET kkpalkka = kkpalkka * 1,05Mitä jos tietokantapalvelin kaatuu, kun vasta 10000 muutettua riviä on tallennettu levylle? 990000 vihaista työntekijää jää ilman palkankorotusta? Tarvitaan jokin keino varmistaa, että päivitys tehdään kokonaan tai ei lainkaan. - Entä jos palkkojen maksuun liittyvä prosessi lukee palkkatietoja juuri samalla kun niitä ollaan päivittämässä? Lukuoperaatio voi lukea esimerkiksi vain tietyn toimipaikan työntekijöiden palkat - 100 riviä. Jos päivitys on yhtäaikaa kesken, voi käydä niin, että osaan luetuista riveistä on ehditty jo tehdä päivitys ja osaan ei. Nyt osa työntekijöistä saa syyskuun palkkansa korotettuna ja osa ei? Tarvitaan jokin keino hallita yhtäaikaisia prosesseja.
Tietokantatransaktiot
Tietokantatransaktiot ratkaisevat edellä mainitut ongelmat. Ongelmat voidaan jakaa kahteen kategoriaan:
- Operaatioden keskeytymiset järjestelmän kaatuessa, häiriötilanteissa tai hallituissa keskeytyksissä
- Samanaikaset prosessit
Tietokantatransaktio sisältää yhden tai useamman tietokantaan kohdistuvan operaation, jotka suoritetaan (järjestyksessä) kokonaisuutena. Jos yksikin operaatio epäonnistuu, kaikki operaatiot perutaan, ja tietokanta palautetaan tilaan, missä se oli ennen transaktion aloitusta. Klassinen esimerkki tietokantatransaktiosta on tilisiirto, missä nostetaan rahaa yhdeltä tililtä, ja siirretään rahaa toiselle tilille. Jos tilisiirron suoritus ei onnistu -- esimerkiksi rahan lisääminen toiselle tilille epäonnistuu -- tulee myös rahan nostaminen toiselta tililtä perua.
Jokainen tietokantakysely suoritetaan omassa transaktiossaan, mutta, käyttäjä voi myös määritellä useamman kyselyn saman transaktion sisälle. Transaktio aloitetaan komennolla BEGIN TRANSACTION, jota seuraa kyselyt, ja lopulta komento COMMIT. Oletetaan, että käytössämme on taulu Tili(id, saldo).
CREATE TABLE Tili (
id integer PRIMARY KEY,
saldo NOT NULL
);
Tilisiirto kahden tilin välillä toteutetaan yhtenä transaktiona seuraavasti.
BEGIN TRANSACTION;
UPDATE Tili SET saldo = saldo - 10 WHERE id = 1;
UPDATE Tili SET saldo = saldo + 10 WHERE id = 2;
COMMIT;
Ylläolevassa transaktiossa suoritetaan kaksi kyselyä, mutta tietokannan näkökulmasta toiminto on atominen, eli sitä ei voi pilkkoa osiin. Komennon COMMIT yhteydessä muutokset joko tallennetaan kokonaisuudessaan tietokantaan, tai tietokantaan ei tehdä minkäänlaisia muutoksia.
Tietokantatransaktiota kirjoittaessa, ohjelmoija voi huomata tehneensä virheen. Tällöin suoritetaan komento ROLLBACK, joka peruu aloitetun transaktion aikana tehdyt muutokset. Suoritettua (COMMIT) tietokantatransaktiota ei voi perua.
Alla esimerkki kahdesta tietokantatransaktiosta. Ensimmäinen perutaan, sillä siinä yritettiin vahingossa siirtää rahaa väärälle tilille. Toinen suoritetaan. Kokonaisuudessaan allaolevan kyselyn lopputulos on se, että tililtä 1 on otettu 10 rahayksikköä, ja tilille 2 on lisätty 10 rahayksikköä.
BEGIN TRANSACTION;
UPDATE Tili SET saldo = saldo - 10 WHERE id = 1;
UPDATE Tili SET saldo = saldo + 10 WHERE id = 3;
ROLLBACK;
BEGIN TRANSACTION;
UPDATE Tili SET saldo = saldo - 10 WHERE id = 1;
UPDATE Tili SET saldo = saldo + 10 WHERE id = 2;
COMMIT;
Jokainen tietokantakysely -- myös "yhden rivin kyselyt" -- suoritetaan transaktion sisällä. Tietokannanhallintajärjestelmän vastuulla on vahtia, että transaktiot suoritetaan peräkkäin siten, että samaa tietoa ei voida käsitellä useammasta transaktiosta saman aikaan.
Tietokantatransaktiot ja rajoitteet
Koska tietokannanhallintajärjestelmä näkee transaktioiden sisällä suoritettavat käskyt atomisina, eli yksittäisenä kokonaisuutena, voivat tietokantatauluun määritellyt rajoitteet olla hetkellisesti rikki, kunhan ne transaktion suorituksen jälkeen ovat kunnossa.
Esimerkiksi suomen kirjanpitosääntöjen mukaan jokaisessa yrityksessä tulee olla kaksinkertainen kirjanpito. Tässä jokaisen tilitapahtuman yhteydessä tulee merkitä sekä mistä raha on otettu (debit), että mihin raha on laitettu (credit). Tällaisessa järjestelmässä tulee olla (esimerkiksi) tietokantataulu Kirjanpitotapahtuma, johon muutokset merkitään.
CREATE TABLE Kirjanpitotapahtuma
(
id integer PRIMARY KEY,
paivamaara date NOT NULL,
kirjanpitotili integer NOT NULL,
kuvaus text NOT NULL,
debit integer NOT NULL,
credit integer NOT NULL,
FOREIGN KEY(kirjanpitotili) REFERENCES Tili(id),
CONSTRAINT kirjaus_tasmaa CHECK (SUM(debit) = SUM(credit))
)
Nyt yhden transaktion sisällä voi tehdä useamman kirjanpitotapahtuman, kunhan transaktion suorituksen yhteydessä kirjanpitotapahtumien debit- ja credit-sarakkeiden summa täsmää. Yllä tietokantataulun luomiskomentoon on lisätty rajoite (CONSTRAINT), jonka avulla tietokantatauluun voidaan lisätä sääntöjä, joiden tulee olla aina transaktion jälkeen voimassa.
Tietokannanhallintajärjestelmän ominaisuuksia
ACID (Atomicity, Consistency, Isolation, Durability) on joukko tietokannanhallintajärjestelmän ominaisuuksia:
- Atomisuudella (
Atomicity) varmistetaan, että tietokantatransaktio suoritetaan joko kokonaisuudessaan tai ei lainkaan. Jos tietokannanhallintajärjestelmään tehtävät transaktiot eivät olisi atomisia, voisi esimerkiksi päivityskyselyistä päätyä tietokantaan asti vain osa -- tilisiirtoesimerkissä vain rahan ottaminen yhdeltä tililtä, mutta ei sen lisäämistä toiselle. - Eheydellä (
Consistency) varmistetaan, että tietokantaan määritellyt rajoitteet, kuten viiteavaimet, pätevät jokaisen transaktion jälkeen. Jos tietokanta ei mahdollistaisi eheystarkistusta, voisi esimerkiksi kirjanpito olla virheellinen. - Eristyvyydellä (
Isolation) varmistetaan, että transaktio (A) ei voi lukea toisen transaktion (B) muokkaamaa tietoa ennenkuin toinen transaktio (B) on suoritettu loppuun. Tällä varmistetaan se, että jos transaktioita suoritetaan rinnakkaisesti, kumpikin näkee tietokannan eheässä tilassa. - Pysyvyydellä (
Durability) varmistetaan, että transaktion suorituksessa tapahtuvat muutokset ovat pysyviä. Kun käyttäjä lisää tietoa tietokantaan, tietokannanhallintajärjestelmän tulee varmistaa että tieto säilyy myös virhetilanteissa (jos transaktion suoritus onnistuu).
Perinteiset tietokannanhallintajärjestelmät tarvitsevat atomisuuden ja pysyvyyden toteuttamiseen write-ahead-lokia (WAL). Se tarkoittaa sitä, että suoritettavaksi tuleva tietokantaoperaatio tallennetaan tekstimuotoisena lokina levylle ennen rivien varsinaista päivitystä. Tällöin operaatiot voidaan suorittaa uudelleen, jos tietokantapalvelin kaatuu ennen kuin muistissa päivitetyt rivit ehditään tallentaa levylle. Tämä nopeuttaa tietokannan toimintaa merkittävästi, sillä pitkien operaatioiden kirjoittamista levylle ei tarvitse odottaa ennen kuin sovellukselle voidaan vastata operaation onnistuneen. Eristyvyyden toteuttamiseen käytetään mm. erilaisia taulu- ja rivilukitusmekanismeja. Kurssilla Transaktioiden hallinta tutustutaan tarkemmin transaktioiden toimintaan.
Useampaa tietokantataulua käyttävä web-sovellus
Rakennetaan seuraavaksi useampaa tietokantataulua käyttävä web-sovellus. Tarve on seuraava:
Haluaisin käyttööni tehtävien hallintaan tarkoitetun englanninkielisen sovelluksen. Jokaisella tehtävällä on nimi sekä tieto siitä, että onko tehtävä tehty. Tehtäviin voi määritellä aihepiirejä, joiden perusteella tehtäviä pitäisi myös pystyä hakemaan. Tämän lisäksi sovelluksessa tulee olla käyttäjiä, joiden tulee pystyä ottamaan tehtäviä työn alle. Vain työn alle otettu tehtävä voidaan merkitä tehdyksi.
Kuvauksesta tunnistetaan käsitteet tehtävä, aihepiiri ja käyttäjä. Tämän lisäksi tehtävä voi kuulua yhteen tai useampaan aihepiiriin, ja jokaiseen aihepiiriin voi liittyä useampi tehtävä. Käyttäjällä voi olla useampia tehtäviä työn alla. Aihealueen kuvaus ei ota kantaa siihen, voiko sama tehtävä olla useammalla käyttäjällä samaan aikaan työn alla -- suunnitellaan tietokanta siten, että samaa tehtävää voi periaatteessa tehdä useampi käyttäjä.
Tekstimuodossa kuvattuna tietokantataulut ovat seuraavat. Koska sovellus haluttiin englanninkielisenä, myös tietokannan termistö on englanniksi.
Task((pk) id, name)
User((pk) id, name)
TaskAssignment((pk) id, (fk) task_id -> Task, (fk) user_id -> User, boolean completed)
Category((pk) id, name)
TaskCategory((pk) id, (fk) task_id -> Task, (fk) category_id -> Category)
Sovellus rakennetaan askeleittain. Toteutetaan ensin tehtävien lisääminen ja listaaminen. Tämän jälkeen lisätään mahdollisuus käyttäjien lisäämiseen ja listaamiseen. Tätä seuraa tehtävien lisääminen käyttäjälle, jonka jälkeen toteutetaan tehtävien suorittaminen.
Alustava sovelluksen kansiorakenne eriyttää aihealuetta kuvaavat käsitteet, tietokannan käsittelyyn tarvittavat luokat sekä html-sivut. Alla kansiorakenne puuna kuvattuna.
kayttaja@kone:~/kansio$ tree . ├── pom.xml ├── src │ ├── main │ │ ├── java │ │ │ └── tikape │ │ │ └── tasks │ │ │ ├── dao │ │ │ │ ├── Dao.java │ │ │ │ └── TaskDao.java │ │ │ ├── database │ │ │ │ └── Database.java │ │ │ ├── domain │ │ │ │ └── Task.java │ │ │ └── TaskApplication.java │ │ └── resources │ │ └── templates │ │ └── tasks.html │ └── test │ └── java └── tasks.db
Sovelluksen pom.xml-tiedoston sisältö on seuraava. Riippuvuus slf4j-simple lisää sovellukseen muiden kirjastojen debug-viestien tulostamisen.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>tikape</groupId>
<artifactId>tasks</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>com.sparkjava</groupId>
<artifactId>spark-core</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>com.sparkjava</groupId>
<artifactId>spark-template-thymeleaf</artifactId>
<version>2.5.5</version>
</dependency>
<dependency>
<groupId>org.xerial</groupId>
<artifactId>sqlite-jdbc</artifactId>
<version>3.20.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.25</version>
</dependency>
</dependencies>
</project>
Tehtävän lisääminen sovellukseen
Toteutetaan ensin tehtävien listaaminen ja lisääminen.
Yleisesti ottaen, laajempaa sovellusta rakennettaessa sovelluksen polut kannattaa toteuttaa kuvaamaan käsiteltäviä asioita. Luodaan tehtäviä varten web-sovellukseen polku /tasks, mistä tehtävät löytyvät. Sovelluksen tehtävien käsittelyyn liittyvä "rajapinta" tulee olemaan seuraavanlainen.
- Tiedon hakeminen palvelimen osoitteesta
/taskslistaa kaikki tehtävät. - Tiedon lähettäminen palvelimen osoitteeseen
/tasksluo uuden tehtävän.
Luodaan näkymää varten sivu tasks.html, jonka avulla käyttäjälle listataan tehtävät sekä mahdollistetaan tehtävien lisääminen. Sivu tulee projektin kansioon src/main/resources/templates. Sivulla on sekä lista tehtäviä että lomake.
<!DOCTYPE html SYSTEM "http://www.thymeleaf.org/dtd/xhtml1-strict-thymeleaf-4.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org">
<head>
<title>Tasks</title>
<meta charset="utf-8" />
</head>
<body>
<h1>Tasks</h1>
<ul>
<li th:each="task : ${tasks}">
<span th:text="${task.name}">Task</span>
</li>
</ul>
<h2>Add new task</h2>
<form method="POST" action="/tasks">
<input type="text" name="name"/><br/>
<input type="submit" value="Add!"/>
</form>
</body>
</html>
Luodaan tämän jälkeen ongelma-aluetta kuvaava luokka Task. Ongelma-aluetta tai aihealuetta (domain) kuvaavat luokat kannattaa sovelluksen rakenteen asetetaan pakkaukseen domain. Esimerkissämme sovellus rakentuu pakkaukseen tikape.tasks, jolloin käsitteistöä kuvaavat luokat asetetaan pakkaukseen tikape.tasks.domain.
package tikape.tasks.domain;
public class Task {
private Integer id;
private String name;
public Task(Integer id, String name) {
this.id = id;
this.name = name;
}
public Integer getId() {
return id;
}
public String getName() {
return name;
}
}
Materiaalin kolmannessa osassa loimme tietokanta-abstraktion sekä harjoittelimme data access object-luokkien toteuttamista. Luodaan käyttöömme tarvittavat luokat tietokannassa olevien tehtävien käsittelyyn.
package tikape.tasks.database;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class Database {
private String databaseAddress;
public Database(String databaseAddress) throws ClassNotFoundException {
this.databaseAddress = databaseAddress;
}
public Connection getConnection() throws SQLException {
return DriverManager.getConnection(databaseAddress);
}
}
package tikape.tasks.dao;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import tikape.tasks.database.Database;
import tikape.tasks.domain.Task;
public class TaskDao implements Dao<Task, Integer> {
private Database database;
public TaskDao(Database database) {
this.database = database;
}
@Override
public Task findOne(Integer key) throws SQLException {
throw new UnsupportedOperationException("Not supported yet.");
}
@Override
public List<Task> findAll() throws SQLException {
List<Task> tasks = new ArrayList<>();
try (Connection conn = database.getConnection();
ResultSet result = conn.prepareStatement("SELECT id, name FROM Task").executeQuery()) {
while (result.next()) {
tasks.add(new Task(result.getInt("id"), result.getString("name")));
}
}
return tasks;
}
@Override
public Task saveOrUpdate(Task object) throws SQLException {
// simply support saving -- disallow saving if task with
// same name exists
Task byName = findByName(object.getName());
if (byName != null) {
return byName;
}
try (Connection conn = database.getConnection()) {
PreparedStatement stmt = conn.prepareStatement("INSERT INTO TASK (name) VALUES (?)");
stmt.setString(1, object.getName());
stmt.executeUpdate();
}
return findByName(object.getName());
}
private Task findByName(String name) throws SQLException {
try (Connection conn = database.getConnection()) {
PreparedStatement stmt = conn.prepareStatement("SELECT id, name FROM Task WHERE name = ?");
stmt.setString(1, name);
ResultSet result = stmt.executeQuery();
if (!result.next()) {
return null;
}
return new Task(result.getInt("id"), result.getString("name"));
}
}
@Override
public void delete(Integer key) throws SQLException {
throw new UnsupportedOperationException("Not supported yet.");
}
}
Luodaan vielä tietokanta sekä tietokantaan tehtävää kuvaava taulu. Luodaan nämä sovelluksen juureen tiedostoon nimeltä tasks.db.
CREATE TABLE Task (
id integer PRIMARY KEY,
name varchar(255)
);
Nyt palat ovat paikallaan. Käytössämme ovat (1) html-sivu, (2) käsitettä kuvaava luokka, (3) tietokanta-abstraktio ja dao-toteutus, ja (4) tietokantataulu. Luodaan lopulta web-sovelluksen käynnistävä luokka TaskApplication. Sovellus käsittelee pyyntöjä osoitteeseen /tasks.
package tikape.tasks;
import java.util.HashMap;
import spark.ModelAndView;
import spark.Spark;
import spark.template.thymeleaf.ThymeleafTemplateEngine;
import tikape.tasks.dao.TaskDao;
import tikape.tasks.database.Database;
import tikape.tasks.domain.Task;
public class TaskApplication {
public static void main(String[] args) throws Exception {
Database database = new Database("jdbc:sqlite:tasks.db");
TaskDao tasks = new TaskDao(database);
Spark.get("/tasks", (req, res) -> {
HashMap map = new HashMap<>();
map.put("tasks", tasks.findAll());
return new ModelAndView(map, "tasks");
}, new ThymeleafTemplateEngine());
Spark.post("/tasks", (req, res) -> {
Task task = new Task(-1, req.queryParams("name"));
tasks.saveOrUpdate(task);
res.redirect("/tasks");
return "";
});
}
}
Sovellus tukee nyt tehtävien lisäämistä ja listaamista.
Käyttäjien lisääminen sovellukseen
Lisätään seuraavaksi käyttäjät sovellukseen. Käyttäjien käsittelyyn liittyvä rajapinta tulee olemaan seuraavanlainen web-sovelluksen käyttäjän näkökulmasta.
- Tiedon hakeminen palvelimen osoitteesta
/userslistaa kaikki käyttäjät. - Tiedon lähettäminen palvelimen osoitteeseen
/usersluo uuden käyttäjän.
Käyttäjien toiminnallisuus ja niihin liittyvä ohjelmakoodi vastaa hyvin pitkälti tehtävien lisäämiseen ja listaamiseen liittyvää ohjelmakoodia. Voimme käytännössä copy-pasteta edellisen osan askeleet -- noudatetaan tässä Three Strikes And You Refactor-periaatetta. Kopioimme siis seuraavat tiedostot sekä muokkaamme niitä sopivasti:
- tasks.html sivun muotoon users.html
- Task.java-luokan luokaksi User.java
- TaskDao.java-luokan luokaksi UserDao.java
Käyttäjää kuvaavan tietokantataulun nimeksi tulee User -- tietokantataulun luomiskomento on seuraava.
CREATE TABLE User (
id integer PRIMARY KEY,
name varchar(255)
);
Lisätään tämän jälkeen luokan TaskApplication main-metodiin käyttäjien käsittelyyn tarvittavat rivit.
public static void main(String[] args) throws Exception {
Database database = new Database("jdbc:sqlite:tasks.db");
TaskDao tasks = new TaskDao(database);
UserDao users = new UserDao(database);
Spark.get("/tasks", (req, res) -> {
HashMap map = new HashMap<>();
map.put("tasks", tasks.findAll());
return new ModelAndView(map, "tasks");
}, new ThymeleafTemplateEngine());
Spark.post("/tasks", (req, res) -> {
Task task = new Task(-1, req.queryParams("name"));
tasks.saveOrUpdate(task);
res.redirect("/tasks");
return "";
});
Spark.get("/users", (req, res) -> {
HashMap map = new HashMap<>();
map.put("users", users.findAll());
return new ModelAndView(map, "users");
}, new ThymeleafTemplateEngine());
Spark.post("/users", (req, res) -> {
User user = new User(-1, req.queryParams("name"));
users.saveOrUpdate(user);
res.redirect("/users");
return "";
});
}
Tehtävien lisääminen käyttäjille
Lisätään seuraavaksi sovellukseen mahdollisuus tehtävien lisäämiseen käyttäjille. Toteutetaan toiminnallisuus siten, että tehtävä näkyy tehtävälistauksessa vain jos tehtävää ei ole lisätty käyttäjälle. Lisätään tämän jälkeen käyttäjille henkilökohtainen sivu, missä näkyy käyttäjälle määritellyt tehtävät.
Luodaan erillinen taulu TaskAssignment tehtävien käyttäjille lisäämistä varten. Taulu TaskAssignment on liitostaulu tehtävän ja käyttäjän välillä, jonka lisäksi taulu pitää kirjaa siitä, onko tehtävä tehty.
CREATE TABLE TaskAssignment (
id integer PRIMARY KEY,
task_id integer,
user_id integer,
completed boolean,
FOREIGN KEY (task_id) REFERENCES Task(id),
FOREIGN KEY (user_id) REFERENCES User(id)
);
Tietokannan koko rakenne on tällä hetkellä seuraava:
sqlite> .schema
CREATE TABLE Task (
id integer PRIMARY KEY,
name varchar(255)
);
CREATE TABLE User (
id integer PRIMARY KEY,
name varchar (255)
);
CREATE TABLE TaskAssignment (
id integer PRIMARY KEY,
task_id integer,
user_id integer,
completed boolean,
FOREIGN KEY (task_id) REFERENCES Task(id),
FOREIGN KEY (user_id) REFERENCES User(id)
);
Määritellään polku tehtävän lisäämiseen käyttäjälle muotoon /tasks/taskId, missä taskId viittaa tietyn tehtävän avaimeen. Polkuun tulee lähettää kenttä userId, jonka arvon tulee olla tehtävään määrättävän käyttäjän tunnus.
Luodaan ensin luokat TaskAssignment ja TaskAssignmentDao. Jälkimmäinen mahdollistaa vain yksittäisen TaskAssignment-olion tallentamisen.
package tikape.tasks.domain;
public class TaskAssignment {
private Integer id;
private Integer taskId;
private Integer userId;
private Boolean completed;
public TaskAssignment(Integer id, Integer taskId, Integer userId, Boolean completed) {
this.id = id;
this.taskId = taskId;
this.userId = userId;
this.completed = completed;
}
public Integer getId() {
return this.id;
}
public Integer getTaskId() {
return taskId;
}
public Integer getUserId() {
return userId;
}
public Boolean getCompleted() {
return completed;
}
}
package tikape.tasks.dao;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.List;
import tikape.tasks.database.Database;
import tikape.tasks.domain.TaskAssignment;
public class TaskAssignmentDao implements Dao<TaskAssignment, Integer> {
private Database database;
public TaskAssignmentDao(Database database) {
this.database = database;
}
@Override
public TaskAssignment findOne(Integer key) throws SQLException {
throw new UnsupportedOperationException("Not supported yet.");
}
@Override
public List<TaskAssignment> findAll() throws SQLException {
throw new UnsupportedOperationException("Not supported yet.");
}
@Override
public TaskAssignment saveOrUpdate(TaskAssignment object) throws SQLException {
try (Connection conn = database.getConnection()) {
PreparedStatement stmt = conn.prepareStatement(
"INSERT INTO TaskAssignment (task_id, user_id, completed) VALUES (?, ?, 0)");
stmt.setInt(1, object.getTaskId());
stmt.setInt(2, object.getUserId());
stmt.executeUpdate();
}
return null;
}
@Override
public void delete(Integer key) throws SQLException {
throw new UnsupportedOperationException("Not supported yet.");
}
}
Toteutetaan näkymä muokkaamalla sivua tasks.html siten, että jokaisen listattavan tehtävän kohdalla on lista käyttäjistä. Jos listasta valitsee käyttäjän ja valitsee "Assign task!", tehtävä tulee lisätä kyseiselle käyttäjälle.
<!DOCTYPE html SYSTEM "http://www.thymeleaf.org/dtd/xhtml1-strict-thymeleaf-4.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org">
<head>
<title>Tasks</title>
<meta charset="utf-8" />
</head>
<body>
<h1>Tasks</h1>
<ul>
<li th:each="task : ${tasks}">
<span th:text="${task.name}">Task</span>
<form th:action="@{~/tasks/{id}(id=${task.id})}" method="post">
<select name="userId">
<option th:each="user: ${users}" th:value="${user.id}" th:text="${user.name}">
user
</option>
</select>
<input type="submit" value="Assign task!"/>
</form>
</li>
</ul>
<h2>Add new task</h2>
<form method="POST" action="/tasks">
<input type="text" name="name"/><br/>
<input type="submit" value="Add!"/>
</form>
</body>
</html>
Lomakkeen määrittely siten, että jokaisella tehtävällä on oma tunnuksensa ja lomakkeensa onnistuu Thymeleafin syntaksin avulla. Syntaksista lisää Thymeleafin dokumentaatiossa osoitteessa http://www.thymeleaf.org/doc/articles/standardurlsyntax.html.
Tehtävien listaamiseen käytettävää metodia tulee nyt muokata siten, että se antaa käyttäjät Thymeleafin käyttöön.
Spark.get("/tasks", (req, res) -> {
HashMap map = new HashMap<>();
map.put("tasks", tasks.findAll());
map.put("users", users.findAll());
return new ModelAndView(map, "tasks");
}, new ThymeleafTemplateEngine());
Luodaan seuraavaksi uusi metodi käyttäjien lisäämiseen. Metodi käsittelee pyyntöjä polkuun, jossa on muuttuva osa. Muuttuvan osan arvoon pääsee käsiksi Sparkin avulla. Metodissa otetaan käyttöön sekä muuttuva polun osa (eli tehtävän pääavain) että pyynnössä tuleva käyttäjän tunnus. Näiden perusteella luodaan uusi rivi tietokantatauluun TaskAssignment.
// polkuun määriteltävä parametri merkitään kaksoispisteellä ja
// parametrin nimellä. Parametrin arvoon pääsee käsiksi kutsulla
// req.params
Spark.post("/tasks/:id", (req, res) -> {
Integer taskId = Integer.parseInt(req.params(":id"));
Integer userId = Integer.parseInt(req.queryParams("userId"));
TaskAssignment ta = new TaskAssignment(-1, taskId, userId, Boolean.FALSE);
taskAssignments.saveOrUpdate(ta);
res.redirect("/tasks");
return "";
});
Muokataan lopulta vielä tehtävien listaamiseen käytettävää metodia siten, että se näyttää listauksessa vain ne tehtävät, joita ei ole vielä asetettu kenenkään käyttöön. Luodaan tätä varten luokkaan TaskDao uusi metodi, joka hakee ne tehtävät, joiden pääavain ei esiinny taulussa TaskAssignment.
public List<Task> findAllNotAssigned() throws SQLException {
List<Task> tasks = new ArrayList<>();
try (Connection conn = database.getConnection();
ResultSet result = conn.prepareStatement(
"SELECT id, name FROM Task WHERE id NOT IN (SELECT task_id FROM TaskAssignment)"
).executeQuery()) {
while (result.next()) {
tasks.add(new Task(result.getInt("id"), result.getString("name")));
}
}
return tasks;
}
Polkuun /tasks tehtävän pyynnön käsittelyä muokataan siten, että kaikki tehtävät hakevan metodin sijaan kutsutaan yllä kuvattua metodia.
Spark.get("/tasks", (req, res) -> {
HashMap map = new HashMap<>();
map.put("tasks", tasks.findAllNotAssigned());
map.put("users", users.findAll());
return new ModelAndView(map, "tasks");
}, new ThymeleafTemplateEngine());
Nyt tehtävät poistuvat tehtävälistauksesta sitä mukaa kun niitä määrätään käyttäjälle.
Henkilökohtainen tehtäväsivu
Toteutetaan seuraavaksi käyttäjille henkilökohtaiset tehtävät listaava sivu. Sivu tulee toimimaan osoitteessa /users/id, missä id on käyttäjän pääavain. Tehdään tätä varten ensin sivu, mikä sisältää käyttäjän nimen sekä käyttäjälle määrätyt tehtävät.
<!DOCTYPE html SYSTEM "http://www.thymeleaf.org/dtd/xhtml1-strict-thymeleaf-4.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org">
<head>
<title>User's tasks</title>
<meta charset="utf-8" />
</head>
<body>
<h1 th:text="${user.name}">Name of the user</h1>
<h2>Current tasks</h2>
<ul>
<li th:each="task : ${tasks}">
<span th:text="${task.name}">Task</span>
</li>
</ul>
</body>
</html>
Luodaan TaskDao-luokalle metodi, joka hakee käyttäjään liittyvät tehtävät. Haetaan vain ne käyttäjälle kuuluvat tehtävät, joita ei ole vielä tehty. Kyselyä kannattaa hahmotella ensin komentorivin kautta -- alla kuvattu mahdollinen kyselyn rakennusprosessi.
sqlite> SELECT name FROM Task, TaskAssignment
WHERE Task.id = TaskAssignment.task_id AND TaskAssignment.user_id = 1;
Write
sqlite> SELECT id, name FROM Task, TaskAssignment
WHERE Task.id = TaskAssignment.task_id AND TaskAssignment.user_id = 1;
Error: ambiguous column name: id
sqlite> SELECT Task.id, Task.name FROM Task, TaskAssignment
WHERE Task.id = TaskAssignment.task_id AND TaskAssignment.user_id = 1;
1|Write
sqlite> SELECT Task.id, Task.name FROM Task, TaskAssignment
WHERE Task.id = TaskAssignment.task_id AND TaskAssignment.user_id = 1
AND TaskAssignment.completed = false;
Error: no such column: false
sqlite> SELECT Task.id, Task.name FROM Task, TaskAssignment
WHERE Task.id = TaskAssignment.task_id AND TaskAssignment.user_id = 1
AND TaskAssignment.completed = 0;
1|Write
sqlite>
TaskDao-luokalle luotava uusi metodi on seuraavanlainen.
public List<Task> findNonCompletedForUser(Integer userId) throws SQLException {
String query = "SELECT Task.id, Task.name FROM Task, TaskAssignment\n"
+ " WHERE Task.id = TaskAssignment.task_id "
+ " AND TaskAssignment.user_id = ?\n"
+ " AND TaskAssignment.completed = 0";
List<Task> tasks = new ArrayList<>();
try (Connection conn = database.getConnection()) {
PreparedStatement stmt = conn.prepareStatement(query);
stmt.setInt(1, userId);
ResultSet result = stmt.executeQuery();
while (result.next()) {
tasks.add(new Task(result.getInt("id"), result.getString("name")));
}
}
return tasks;
}
Käyttäjäkohtaiseen osoitteeseen tulevat pyynnöt käsittelevä metodi ottaa pyynnön polusta tarkasteltavan käyttäjän tunnuksen. Tämän jälkeen käyttäjän tiedot haetaan tietokannasta, mitä seuraa yllä kuvatun metodin kutsuminen. Lopulta käyttäjän tiedot annetaan Thymeleafille sekä yllä kuvatulle user.html-sivulle.
Spark.get("/users/:id", (req, res) -> {
HashMap map = new HashMap<>();
Integer userId = Integer.parseInt(req.params(":id"));
map.put("user", users.findOne(userId));
map.put("tasks", tasks.findNonCompletedForUser(userId));
return new ModelAndView(map, "user");
}, new ThymeleafTemplateEngine());
Luokan UserDao metodi findOne tulee täydentää sopivasti. Alkuperäisessä versiossamme jätimme metodin toteuttamatta.
Tällä hetkellä käyttäjäkohtaiseen sivuun ei pääse vielä käsiksi. Muokataan käyttäjien listaussivua users.html siten, että jokainen sivulla esiintyvä käyttäjän nimi on samalla linkki käyttäjän sivuun.
<!DOCTYPE html SYSTEM "http://www.thymeleaf.org/dtd/xhtml1-strict-thymeleaf-4.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org">
<head>
<title>Users</title>
<meta charset="utf-8" />
</head>
<body>
<h1>Users</h1>
<ul>
<li th:each="user : ${users}">
<a th:href="@{~/users/{id}(id=${user.id})}">
<span th:text="${user.name}">User</span>
</a>
</li>
</ul>
<h2>Add new user</h2>
<form method="POST" action="/users">
<input type="text" name="name"/><br/>
<input type="submit" value="Add!"/>
</form>
</body>
</html>
Nyt sovelluksessa näkyvästä käyttäjien listauksesta pääsee käsiksi yksittäisen käyttäjän näkymään sekä hänelle määrättyihin tehtäviin.
Tehtävien lisääminen käyttäjälle toteutettiin edellä kuvatussa sovelluksessa tietokantaa käyttäville sovelluksille harmittavan yleisellä tavalla. Kun käyttäjälle lisätään tehtävä, kyseistä tehtävää ei enää näytetä sivulla, missä tehtäviä voi lisätä käyttäjille. Mikään ei kuitenkaan estä ilkeämielistä käyttäjää leikkimästä selainta ja tekemästä pyyntöjä palvelimelle.
Voit kokeilla tätä myös itse -- linux/unix/mac -komentorivillä seuraava komento lisää käyttäjälle, jonka pääavain on 2 tehtävän, jonka pääavain on 1.
kayttaja@kone:~/kansio$ curl --data "userId=2" http://localhost:4567/tasks/1
Yllä kuvatun komennon voi ajaa tällä hetkellä halutessaan vaikkapa miljoona kertaa, jolloin TaskAssignment-tauluun päätyy miljoona riviä.
Korjaa tilanne. Muokkaa sovellusta siten, että jokainen tehtävä voi olla määrättynä korkeintaan yhdelle käyttäjälle.
Tehtäväpohjan mukana tulee edellä kuvattu sovellus. Lisää tehtävään toiminnallisuus, minkä avulla käyttäjäkohtaisella sivulla voi merkitä tehtäviä tehdyksi.
Kategorioiden lisääminen
Lisätään seuraavaksi mahdollisuus kategorioiden lisäämiseen ja listaamiseen. Luodaan kategorioita varten ensin tietokantataulu Category.
CREATE TABLE Category (
id integer PRIMARY KEY,
name varchar(255)
);
Kategorioiden lisäämiseen ja listaamiseen tarvittava toiminnallisuus vastaa lähes täysin aiemmin toteutettuja tehtävien ja käyttäjien toiminnallisuuksia. Three Strikes And You Refactor -periaatteen mukaan kahdesti toistuva ohjelmakoodi ei ole ongelma, mutta jos sama koodi toistuu kolmessa eri paikassa tulee ohjelmaa refaktoroida selkeämmäksi. Otetaan tässä askeleita ohjelman selkeyttämiseksi.
Toisteisuuden vähentäminen samankaltaisista domain-luokista
Tarkastellaan ensin kategoriaa kuvaavan luokan luomista. Sekä kategorialla, tehtävällä että käyttäjällä on tunnus ja nimi. Luodaan abstrakti yliluokka AbstractNamedObject, joka sisältää nimen ja tunnuksen sekä niihin liittyvät getterit.
package tikape.tasks.domain;
public abstract class AbstractNamedObject {
private Integer id;
private String name;
public AbstractNamedObject(Integer id, String name) {
this.id = id;
this.name = name;
}
public Integer getId() {
return id;
}
public String getName() {
return name;
}
}
Nyt luokat kategoria, tehtävä ja käyttäjä voi toteuttaa perimällä luokan AbstractNamedObject. Alla kategoriaa kuvaava luokka.
package tikape.tasks.domain;
public class Category extends AbstractNamedObject {
public Category(Integer id, String name) {
super(id, name);
}
}
Käyttäjien ja tehtävien kuvaamiseen käytettävät luokat muutetaan vastaavaan muotoon.
Toisteisuuden vähentäminen samankaltaisista DAO-luokista
Toteutetaan seuraavaksi kategorioiden käsittelyyn tarvittava tietokanta-abstraktio CategoryDao. Tämäkin luokka olisi vahvasti copy-pastea edellisistä luokista.
Toteutetaan ensin luokka AbstractNamedObjectDao, joka toteuttaa rajapinnan Dao. Luokka kapseloi niiden tietokantataulujen käsittelyyn liittyvää toiminnallisuutta, joissa on id ja nimi. Toteutus tehdään niin, että abstrakti luokka saa konstruktorin parametrina tietokannan lisäksi käsiteltävän tietokantataulun nimen, jota voi käyttää kyselyiden muodostamisessa.
protected Database database;
protected String tableName;
public AbstractNamedObjectDao(Database database, String tableName) {
this.database = database;
this.tableName = tableName;
}
Tehdään luokasta sellainen, että sen voi toteuttaa vain niille luokille, jotka perivät luokan AbstractNamedObject. Luokan "otsake" on tällöin seuraavaa muotoa:
public abstract class AbstractNamedObjectDao<T extends AbstractNamedObject>
implements Dao<T, Integer> {
Luokka käsittelee geneeristä tyyppiä olevia olioita, joilla on id ja nimi. Tarvitsemme tavan olioiden luomiseen tietokannalta saaduista riveistä. Luodaan abstraktille luokalle abstrakti metodi createFromRow, joka palauttaa geneeristä tyyppiä olevan olion, ja joka saa parametrinaan resultSet-olion. Jokaisen luokan, joka perii luokan AbstractNamedObject tulee periä ja toteuttaa tämä metodi.
public abstract T createFromRow(ResultSet resultSet) throws SQLException;
Voimme nyt tehdä muista luokan metodeista yleiskäyttöisiä. Metodi findAll kysyy tietoa tietokantataulusta, jonka perivä luokka määrittelee. Kun tietokantakyselyn tuloksia käydään läpi, konkreettisten tulosten luomiseen käytetään luokkakohtaista metodia createFromRow. Metodin findAll rakenne on seuraavanlainen.
@Override
public List<T> findAll() throws SQLException {
List<T> tasks = new ArrayList<>();
try (Connection conn = database.getConnection();
ResultSet result = conn.prepareStatement("SELECT id, name FROM " + tableName).executeQuery()) {
while (result.next()) {
tasks.add(createFromRow(result));
}
}
return tasks;
}
Koko luokan AbstractNamedObjectDao toteutus on seuraava.
package tikape.tasks.dao;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import tikape.tasks.database.Database;
import tikape.tasks.domain.AbstractNamedObject;
public abstract class AbstractNamedObjectDao<T extends AbstractNamedObject>
implements Dao<T, Integer> {
protected Database database;
protected String tableName;
public AbstractNamedObjectDao(Database database, String tableName) {
this.database = database;
this.tableName = tableName;
}
@Override
public T findOne(Integer key) throws SQLException {
try (Connection conn = database.getConnection()) {
PreparedStatement stmt = conn.prepareStatement("SELECT id, name FROM " + tableName + " WHERE id = ?");
stmt.setInt(1, key);
try (ResultSet rs = stmt.executeQuery()) {
rs.next();
return createFromRow(rs);
}
} catch (SQLException e) {
System.err.println("Error when looking for a row in " + tableName + " with id " + key);
e.printStackTrace();
return null;
}
}
@Override
public List<T> findAll() throws SQLException {
List<T> tasks = new ArrayList<>();
try (Connection conn = database.getConnection();
ResultSet result = conn.prepareStatement("SELECT id, name FROM " + tableName).executeQuery()) {
while (result.next()) {
tasks.add(createFromRow(result));
}
}
return tasks;
}
@Override
public T saveOrUpdate(T object) throws SQLException {
// simply support saving -- disallow saving if task with
// same name exists
T byName = findByName(object.getName());
if (byName != null) {
return byName;
}
try (Connection conn = database.getConnection()) {
PreparedStatement stmt = conn.prepareStatement("INSERT INTO " + tableName + " (name) VALUES (?)");
stmt.setString(1, object.getName());
stmt.executeUpdate();
}
return findByName(object.getName());
}
private T findByName(String name) throws SQLException {
try (Connection conn = database.getConnection()) {
PreparedStatement stmt = conn.prepareStatement("SELECT id, name FROM " + tableName + " WHERE name = ?");
stmt.setString(1, name);
try (ResultSet result = stmt.executeQuery()) {
if (!result.next()) {
return null;
}
return createFromRow(result);
}
}
}
@Override
public void delete(Integer key) throws SQLException {
throw new UnsupportedOperationException("Not supported yet.");
}
public abstract T createFromRow(ResultSet resultSet) throws SQLException;
}
Nyt omien Dao-luokkiemme toteutukset ovat hieman suoraviivaisempia. Alla on kuvattuna luokka liittyvä tietokanta-abstraktio CategoryDao.
package tikape.tasks.dao;
import java.sql.ResultSet;
import java.sql.SQLException;
import tikape.tasks.database.Database;
import tikape.tasks.domain.Category;
public class CategoryDao extends AbstractNamedObjectDao<Category> {
public CategoryDao(Database database, String tableName) {
super(database, tableName);
}
@Override
public Category createFromRow(ResultSet resultSet) throws SQLException {
return new Category(resultSet.getInt("id"), resultSet.getString("name"));
}
}
Esimerkin jatkaminen jätetään omalle vastuulle. Seuraavana olisi näkymän kopiointi sekä TaskApplication-luokan muokkaaminen siten, että sovelluksessa pääsee käsiksi kategorioihin.
Tehtäväpohjassa tulee edellä kuvattu sovellus. Toteuta sovellukseen mahdollisuus kategorioiden määrittelyyn tehtäville. Kategorioiden määrittelyn tulee tapahtua tehtäväsivun kautta -- jokaisen tehtävän kohdalla tulee olla lista kategorioista. Kategorian lisääminen tehtävälle ei poista tehtävää tehtäväsivulta.
Muokkaa kategorioiden listaamissivua siten, että jokainen listan kategoria on linkki kategoriakohtaiselle sivulle. Kategoriakohtaisens sivun tulee näyttää ne tehtävät, joita ei ole vielä tehty. Mikäli mahdollista, tehtävät nimen vieressä tulee näkyä myös käyttäjä, kenelle tehtävä on merkitty tehtäväksi.
Web-sovelluksen siirtäminen verkkoon
Web-sovelluksemme on tähän mennessä toiminut vain paikallisella koneella, missä kehitystyötä on tehty. Tutustutaan tässä Heroku-nimisen pilvipalvelun käyttöön ja siirretään Web-sovellus verkkoon kaikkien nähtäväksi.
Herokulla on aiheeseen liittyen myös oma opas, johon kannattaa tutustua täällä.
Tarvitset sovelluksen siirtoon (1) tunnuksen Heroku-palveluun sekä (2) Heroku Toolbeltin.
Alkutoimet
Herokuun siirrettävät sovellukset tarvitsevat muutamia muutoksia:
-
Procfile-tiedoston lisääminen. Sovelluksen juuripolkuun tulee lisätä tiedosto
Procfile, jonka sisällä on sovelluksen käynnistämisessä käytettävä komento.web: java -cp target/classes:target/dependency/* tikape.MainKomennon osa
tikape.Mainkuvaa pääohjelmaluokkaa, jonka kautta sovellus tulee käynnistää. Jos pääohjelmaluokkasi on toisessa pakkauksessa (ei tikape) tai pääohjelmaluokan nimi on jotain muuta (ei Main), tulee tätä muokata. Heroku käyttää tätä komentoa sovelluksen käynnistykseen. -
Maven-liitännäiset ohjelman kääntöprosessin automatisointiin. Sovelluksen
pom.xml-tiedostoon tulee lisätä seuraavat rivit. Rivit lisätään esimerkiksi</properties>-rivin jälkeen.<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>2.5.1</version> <configuration> <source>1.8</source> <target>1.8</target> <optimize>true</optimize> <debug>true</debug> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-dependency-plugin</artifactId> <version>2.4</version> <executions> <execution> <id>copy-dependencies</id> <phase>package</phase> <goals> <goal>copy-dependencies</goal> </goals> </execution> </executions> </plugin> </plugins> </build> -
Sovelluksen käynnistäminen Herokun määräämässä portissa. Jokainen web-sovellus käynnistettään tiettyyn porttiin, jonka se varaa käyttöönsä. Heroku pyörittää useampia sovelluksia samalla palvelinkoneella, joten sille pitää antaa mahdollisuus portin asetukseen.
Portin asetus tapahtuu ympäristömuuttujan avulla, jonka Heroku antaa sovellukselle sovellusta käynnistettäessä. Käytännössä pääohjelmaluokkaan, joka käynnistää web-palvelimen, tulee lisätä seuraavat rivit -- lisää ne main-metodin alkuun.
// asetetaan portti jos heroku antaa PORT-ympäristömuuttujan if (System.getenv("PORT") != null) { port(Integer.valueOf(System.getenv("PORT"))); }
Ylläolevien muutosten avulla sovelluksen siirtäminen verkkoon onnistuu.
Heroku toolbeltin asennus
Asenna heroku toolbelt. Ohjeita löytyy esimerkiksi osoitteessa https://devcenter.heroku.com/articles/heroku-command.
Jos sinulla ei ole koneeseen pääkäyttäjän oikeuksia (root), asennuksen pitäisi silti olla mahdollista jos koneelle on ennestään asennettu muutama Herokun vaatima ohjelmapaketti. Joudut kuitenkin tekemään asennuksen hieman toisin.
Sovelluksen luominen Herokuun
Sovelluksen luomiseen Herokuun tarvitaan kaksi askelta. Ensimmäisessä askeleessa luodaan projektista git-repositorio (tätä ei tarvitse tehdä jos sovellus on jo git-versionhallinnassa), jonka jälkeen luodaan herokuun sijainti johon sovellus kopioidaan.
Projekti git-repositorioksi -- projektin luominen git-repositorioksi tapahtuu ajamalla komento
git initprojektin juurikansiossa (kansio, jossa löytyy tiedostopom.xml). Jos sovellus on jo esimerkiksi githubissa, ei tätä tarvitse tehdä.Heroku-projektin luominen -- suorita juurikansiossa komento
heroku create. Tämä luo sovellukselle sijainnin herokuun, johon sovelluksen voi lähettää.
Mahdollisissa ongelmatilanteissa kannattaa ensimmäiseksi katsoa mitä viestejä Herokun lokitiedostoon on päätynyt.
Sovelluksen lähetys Herokuun
Sovelluksen lähetys herokuun sisältää tyypillisesti neljä askelta. Ensin poistamme turhat käännetyt lähdekooditiedostot, jotta ne eivät häiritse herokun toimintaa. Tämän jälkeen lisäämme tiedostot versionhallintaan, sitoudumme niiden lähettämiseen, ja siirrämme ne herokuun.
-
Turhien lähdekooditiedostojen poistaminen -- suorita projektin juurikansiossa komento
mvn clean, joka poistaa projektista käännetyt lähdekooditiedostot (kansio target). -
Tiedostojen lisääminen versionhallintaan -- suorita projektin juurikansiossa komento
git add ., joka lisää kaikki projektin tiedostot versionhallintaan. Huom! Varmista, että target-kansio ei pääse lipsahtamaan versionhallintaan tai Herokuun. -
Tiedostojen lähettämiseen sitoutuminen -- suorita projektin juurikansiossa komento
git commit -m "viesti", joka sitouttaa lähetykseen juuri lisätyt tiedostot. -
Tiedostojen siirtäminen herokuun -- suorita projektin juurikansiossa komento
git push heroku master, joka lähettää tiedostot herokuun.
Nyt sovelluksesi on verkossa kaikkien nähtävillä.