Osaa tehdä SQL-kielellä yhteenvetokyselyitä. Osaa luoda yhtä tietokantataulua käyttävän ja muokkaavan web-sovelluksen, jota voi käyttää selaimella. Tuntee sekvenssikaaviot.
Yhteenvetokyselyt SQL-kielellä
Harjoittelemamme SQL-kyselyt ovat tähän mennessä tuottaneet listauksia tietokantataulujen sisällöistä. Listauksia tuottavat kyselyt ovat erittäin hyödyllisiä, kun halutaan vastata esimerkiksi kysymyksiin kuten "Listaa kaikki opiskelijat, jotka ovat osallistuneet kurssille tietokantojen perusteet" tai "Listaa kaikki kurssit, joille annettu opiskelija on ilmoittautunut". Kysymykset kuten "Kuinka moni opiskelija on osallistunut kurssille tietokantojen perusteet" ovat kuitenkin vaatineet manuaalista työtä, sillä kyselyn tulosrivit on pitänyt laskea käsin tai jonkun toisen ohjelman avulla.
SQL-kieli tarjoaa välineitä yhteenvetokyselyiden tekemiseen. Tällaisia kyselyitä ovat esimerkiksi juurikin yllä mainittu "kuinka moni" -- eli tulosrivien määrä -- sekä esimerkiksi erilaiset summa- ja keskiarvokyselyt. Käytännössä yhteenvetokyselyt tehdään SQL-kielen tarjoamien funktioiden avulla, jotka muuntavat tulosrivit toiseen muotoon. Alla on listattuna muutamia tyypillisimpiä funktioita, joita tietokantakyselyissä käytetään.
| Tavoite | Funktio | Esimerkki |
|---|---|---|
| Rivien lukumäärän selvittäminen |
COUNT
|
|
| Numeerisen sarakkeen keskiarvon laskeminen |
AVG
|
|
| Numeerisen sarakkeen summan laskeminen |
SUM
|
|
| Numeerisen sarakkeen minimiarvon selvittäminen |
MIN
|
|
| Numeerisen sarakkeen maksimiarvon selvittäminen |
MAX
|
|
Tarkastellaan näitä kyselyitä hieman tarkemmin. Oletetaan, että käytössämme on seuraava lentomatkoja kuvaava tietokantataulu.
| Lentomatka(yhtio, lahtopaikka, maaranpaa, pituus) | |||
|---|---|---|---|
| Lentoyhtiö | Lähtöpaikka | Määränpää | Lennon pituus (minuuttia) |
| Air Berlin | Helsinki | Berliini | 205 |
| Finnair | Helsinki | Oulu | 70 |
| Finnair | Helsinki | Berliini | 200 |
| Finnair | Helsinki | Tukholma | 50 |
| Finnair | Helsinki | Mallorca | 230 |
| Norwegian | Helsinki | Mallorca | 240 |
Yhteenvetokyselyiden avulla saamme selville erilaisia tilastoja. Alla muutamia esimerkkejä:
-
Kuinka monta matkaa tietokantataulussa Lentomatka on yhteensä?
SELECT COUNT(*) FROM Lentomatka -
Kuinka monta lentoyhtiötä on tietokantataulussa lentomatka? (Huomaa avainsanan DISTINCT käyttö)
SELECT COUNT(DISTINCT yhtio) FROM Lentomatka -
Kuinka monta lentoa taulussa on Helsingistä Mallorcalle?
SELECT COUNT(*) FROM Lentomatka WHERE lahtopaikka = 'Helsinki' AND maaranpaa = 'Mallorca' -
Mikä on keskimääräinen Finnairin lennon pituus?
SELECT AVG(pituus) FROM Lentomatka WHERE yhtio = 'Finnair' -
Mikä on lyhin matkan kesto Helsingistä Berliiniin?
SELECT MIN(pituus) FROM Lentomatka WHERE lahtopaikka = 'Helsinki' AND maaranpaa = 'Berliini'
Yllä olevat esimerkit tuottavat tulokseksi aina yhden luvun. Entä jos haluaisimme saada selville yhtiökohtaisia tietoja kuten vaikkapa jokaisen yhtiön lyhimmän lennon? Tarkastellaan tätä seuraavaksi.
Tulosten ryhmittely
Tulosten ryhmittely tietyn sarakkeen perusteella tapahtuu komennon GROUP BY perustella. Komento GROUP BY lisätään taulujen listauksen ja mahdollisten kyselyn rajausehtojen jälkeen. Komentoa GROUP BY seuraa sarake, jonka perusteella tulokset ryhmitellään. Jotta ryhmittelystä tulee mielekäs, asetetaan ryhmittelyn peruste tyypillisesti myös SELECT-komentoa seuraavaan sarakelistaukseen.
SELECT ryhmittelysarake, FUNKTIO(sarake) FROM Taulu
GROUP BY ryhmittelysarake
Alla muutamia esimerkkejä:
-
Kuinka monta matkaa kullakin lentoyhtiöllä on tarjolla?
SELECT yhtio, COUNT(*) FROM Lentomatka GROUP BY yhtio -
Kuinka monta alle 100 minuutin pituista lentomatkaa eri kaupungeista lähtee?
SELECT lahtopaikka, COUNT(*) FROM Lentomatka WHERE pituus < 100 GROUP BY lahtopaikka -
Kuinka pitkiä kunkin lentoyhtiön matkat ovat keskimäärin?
SELECT yhtio, AVG(pituus) FROM Lentomatka GROUP BY yhtio
Taulujen yhdistäminen toimii kuten ennen. Valittavat taulut kerrotaan joko FROM -avainsanan jälkeen tai JOIN -avainsanan jälkeen, riippuen tavasta, jolla yhdistäminen tehdään. Ryhmittelykomento tulee mahdollisten WHERE-ehtojen jälkeen.
Oletetaan seuraavat taulut Kurssi ja Kurssitehtävä.
- Kurssi((pk) id, nimi, opintopisteet)
- Kurssitehtava((pk) id, (fk) kurssi_id -> Kurssi, tehtava)
Kurssikohtaisten tehtävien lukumäärän laskeminen onnistuu seuraavasti. Avainsana AS muuntaa tuloksena saatavassa taulussa olevan sarakkeen nimen.
SELECT Kurssi.nimi AS kurssi, COUNT(*) AS tehtäviä FROM Kurssi, Kurssitehtävä
WHERE Kurssi.id = Kurssitehtava.kurssi_id
GROUP BY Kurssi.nimi
Edellä kuvatun kyselyn tuloksia tarkastellessa huomaamme, että tuloksissa ei ole yhtäkään tehtävätöntä kurssia. Tämä selittyy kyselyillämme -- olemme valinneet mukaan vain rivit, joilla hakuehdot täyttyvät. Kirjoitetaan edellinen kysely siten, että otamme huomioon kurssit vaikka niihin ei liittyisikään yhtäkään toisen taulun riviä -- käytämme siis LEFT JOIN-liitosoperaatiota.
SELECT Kurssi.nimi AS kurssi, COUNT(*) AS tehtäviä FROM Kurssi
LEFT JOIN Kurssitehtävä ON Kurssi.id = Kurssitehtava.kurssi_id
GROUP BY Kurssi.nimi
Ryhmittely useamman sarakkeen perusteella
Komennolle GROUP BY voi antaa myös useampia sarakkeita, jolloin ryhmittely tapahtuu sarakeryhmittäin. Esimerkiksi ryhmittely GROUP BY kurssi, arvosana ryhmittelisi taulussa olevat rivit ensin kurssin perusteella, jonka jälkeen kurssikohtaiset ryhmät ryhmiteltäisiin vielä arvosanan perusteella. Tällöin jokaiselle kurssille tulisi erilliset arvosanaryhmät.
Oletetaan edellä kuvatun taulun lisäksi taulut Kurssisuoritus ja Opiskelija:
- Kurssisuoritus((pk) id, (fk) kurssi_id -> Kurssi, opiskelija_id -> Opiskelija, arvosana, paivamaara)
- Opiskelija((pk) id, opiskelijanumero, nimi, syntymävuosi)
Kurssikohtaiset arvosanaryhmät saa selville seuraavalla kyselyllä.
SELECT Kurssi.nimi AS kurssi, Kurssisuoritus.arvosana AS arvosana, COUNT (*) AS lukumäärä
FROM Kurssi, Kurssisuoritus
WHERE Kurssi.id = Kurssisuoritus.kurssi_id
GROUP BY Kurssi.nimi, Kurssisuoritus.arvosana
Tulosten järjestäminen
Kyselyn tulokset voi järjestää komennolla ORDER BY, jota seuraa järjestettävät sarakkeet. Sarakkeelle voi antaa myös lisämääreen ASC (ascending), joka kertoo että tulokset tulee järjestää nousevaan järjestykseen, ja DESC (descending), joka kertoo että tulokset tulee järjestää laskevaan järjestykseen. Oletuksena järjestys on nouseva.
Komento ORDER BY tulee kyselyn loppuun. Edellisen kurssiarvosanatilaston tulokset saisi kurssin nimen perusteella järjestykseen seuraavasti.
SELECT Kurssi.nimi AS kurssi, Kurssisuoritus.arvosana AS arvosana, COUNT (*) AS lukumäärä
FROM Kurssi, Kurssisuoritus
WHERE Kurssi.id = Kurssisuoritus.kurssi_id
GROUP BY Kurssi.nimi, Kurssisuoritus.arvosana
ORDER BY Kurssi.nimi
Hakutulosten rajaaminen yhteenvetokyselyissä
Yhteenvetokyselyissä laskettavat tulokset kuten summa, rivien lukumäärä ja keskiarvo muodostetaan vasta, kun kaikki kyselyn rivit on selvillä. Kyselyiden tuloksen rajaamiseen käytetty WHERE toimii siten, että se tarkastelee tuloksia riveittäin -- se ei osaa odottaa summan laskemisen lopputulosta.
Jos yhteenvetokyselyn tuloksen perusteella halutaan rajata tuloksia, tulee käyttää HAVING-ehtoa. HAVING ehto tarkastetaan vasta, kun yhteenvetokyselyn tulokset ovat selvillä. Ehto HAVING lisätään ryhmittelykyselyn jälkeen esimerkiksi seuraavalla tavalla.
SELECT Kurssi.nimi AS kurssi, AVG(Kurssisuoritus.arvosana) keskiarvo
FROM Kurssi, Kurssisuoritus
WHERE Kurssi.id = Kurssisuoritus.kurssi_id
GROUP BY Kurssi.nimi
HAVING keskiarvo < 2
ORDER BY Kurssi.nimi
Yllä olevalla kyselyllä saadaan selville ne kurssit, joihin liittyvien kurssisuoritusten keskiarvo on alle 2.
Kuten esimerkissä näkyy, samassa kyselyssä voi olla sekä WHERE-ehto että HAVING-ehto.
Tehtäväpohjan kansiossa db tulee tiedosto nimeltä Chinook_Sqlite.sqlite. Käytimme samaa tiedostoa osan 3 tehtävässä 2. Tietokannassa on seuraavat taulut:
sqlite> .tables Album Employee InvoiceLine PlaylistTrack Artist Genre MediaType Track Customer Invoice Playlist
Tietokanta kuvaa digitaalisen musiikin myyntipalvelua. Tietokannan relaatiokaavio löytyy osoitteesta http://chinookdatabase.codeplex.com/wikipage?title=Chinook_Schema&referringTitle=Documentation. Kirjoita SQLiten avulla kyselyt, joilla saa selville seuraavat tiedot.
- Kysely 1: Kuinka monta kappaletta kuhunkin genreen liittyy?
- Kysely 2: Kuinka monta kappaletta kustakin genrestä on ostettu? Voit olettaa, että kappale on ostettu jos lasku on olemassa.
- Kysely 3: Mitkä artistit esiintyvät useimmilla levyillä? Järjestäkä artistit levymäärän mukaan ja tulosta niistä 5 yleisimmin esiintyvää -- 5 yleisimmän artistin tulostamiseen auttaa avainsana "LIMIT".
Kun olet saanut kyselyt toimimaan, kopioi ne tehtäväpohjassa olevan luokan Kyselyja metodeihin kysely1, kysely2 ja kysely3. Metodeihin tulee siis kopioida SQL-kieliset kyselyt, joilla em. kysymyksiin saa vastaukset.
Alikyselyt
Alikyselyt ovat nimensä mukaan kyselyn osana suoritettavia alikyselyitä, joiden tuloksia käytetään osana pääkyselyä. Pohditaan kysymystä Miten haen opiskelijat, jotka eivät ole vielä osallistuneet yhdellekään kurssille?, ja käytetään siihen ensin aiemmin tutuksi tullutta tapaa, eli LEFT JOIN -kyselyä. Yhdistetään opiskelijaa ja kurssisuoritusta kuvaavat taulut LEFT JOIN-kyselyllä siten, että myös opiskelijat, joilla ei ole suorituksia tulevat mukaan vastaukseen. Tämän jälkeen, jätetään vastaukseen vain ne rivit, joilla kurssisuoritukseen liittyvät tiedot ovat tyhjiä -- tämä onnistuu katsomalla mitä tahansa kurssisuoritus-taulun saraketta, ja tarkistamalla onko se tyhjä, eli null. Tämä onnistuu seuraavasti:
SELECT opiskelijanumero FROM Opiskelija
LEFT JOIN Kurssisuoritus
ON Opiskelija.id = Kurssisuoritus.opiskelija_id
WHERE Kurssisuoritus.kurssi_id IS null
Toinen vaihtoehto edellisen kyselyn toteuttamiseen on luoda kysely, joka hakee kaikki ne opiskelijat, jotka eivät ole kurssisuorituksia saaneiden opiskelijoiden joukossa. Tässä on oleellisesti kaksi kyselyä: (1) hae niiden opiskelijoiden tunnus, joilla on kurssisuoritus, ja (2) hae opiskelijat, jotka eivät ole edellisen kyselyn palauttamassa joukossa.
Ensimmäinen kysely on suoraviivainen.
SELECT opiskelija_id FROM Kurssisuoritus
Toinenkin kysely on melko suoraviivainen -- avainsanalla NOT IN voidaan rajata joukkoa.
SELECT * FROM Opiskelija
WHERE id NOT IN (ensimmainen kysely)
Yhdessä kyselyt ovat siis muotoa:
SELECT * FROM Opiskelija
WHERE id NOT IN (
SELECT opiskelija_id FROM Kurssisuoritus
)
Käytännössä alikyselyt tuottavat kyselyn tuloksena taulun, josta pääkyselyssä tehtävä kysely tehdään. Ylläolevassa esimerkissä alikyselyn tuottamassa taulussa on vain yksi sarake, jossa on kurssisuorituksen saaneiden opiskelijoiden opiskelijanumerot.
Määreen NOT IN, joka tarkastaa että valitut arvot eivät ole alikyselyn tuottamassa taulussa, lisäksi käytössä on määre IN. Määreen IN avulla voidaan luoda ehto, jolla tarkastetaan, että valitut arvot ovat annetussa joukossa tai taulussa. Esimerkiksi alla haetaan kaikki kurssisuoritukset, joissa arvosana on kolme tai viisi.
SELECT * FROM Kurssisuoritus WHERE arvosana IN (3, 5)
Määreiden IN ja NOT IN lisäksi alikyselyissä voidaan käyttää määreitä EXISTS ja NOT EXISTS, joiden avulla voidaan rajata hakujoukkoa alikyselyssä olevan ehdon perusteella. Voimme esimerkiksi kirjoittaa aiemmin kirjoitetun kursseja suorittamattomia opiskelijoita etsivän kyselyn siten, että jokaisen Opiskelija-taulussa olevan opiskelijanumeron kohdalla tarkistetaan, että sitä ei löydy taulusta Kurssisuoritus.
SELECT opiskelijanumero FROM Opiskelija
WHERE NOT EXISTS
(SELECT opiskelija_id FROM Kurssisuoritus
WHERE Kurssisuoritus.opiskelija_id = Opiskelija.id)
Edellä oleva kysely tarkistaa jokaisen Opiskelija-taulussa olevan opiskelijanumeron kohdalla ettei sitä löydy Kurssisuoritus-taulun opiskelija-sarakkeesta. Käytännössä -- jos tietokantamoottori ei optimoi kyselyä -- jokainen opiskelija-taulun rivi aiheuttaa uuden kyselyn kurssisuoritus-tauluun, mikä tekee kyselystä tehottoman.
Jokainen SQL-kysely tuottaa tuloksena taulun. Taulussa voi olla tasan yksi sarake ja rivi, tai vaikkapa tuhansia rivejä ja kymmeniä sarakkeita. Silloinkin, kun suoritamme yksinkertaisen haun, kuten vaikkapa "Hae kaikki kurssilla 'Tietokantojen perusteet' olevat opiskelijat", on haun tuloksena taulu.
Kaikki tekemämme SQL-kyselyt ovat liittyneet tauluihin. Emmekö siis voisi tehdä kyselyjä myös vastauksiin? Vastaus on kyllä.
Esimerkiksi vanhimman (tai vanhimmat, jos tämä ei ole yksikäsitteistä) opiskelijan löytää -- muunmuassa -- etsimällä kaikista pienimmän mahdollisimman syntymävuoden (kyselyn tulos on taulu), jonka jälkeen vastaustaulussa olevaa tulosta verrataan kaikkien opiskelijoiden syntymävuosiin.
SELECT * FROM Opiskelija
WHERE syntymävuosi
IN (SELECT MIN(syntymävuosi) FROM Opiskelija)
Tietokantaa käyttävien web-sovellusten rakentaminen
Selaimen -- ja nykyään kännykän -- kautta käytettävät sovellukset ovat lähes poikkeuksetta syrjäyttäneet perinteiset työpöytäsovellukset. Tietokannan käyttö sovelluksen osana ei kuitenkaan ole muuttuneet. Työpöytäsovellusten aikana työpöytäsovellus käytti joko paikallisella koneella olevaa tietokannanhallintajärjestelmää, tai otti etäyhteyden toisella koneella käynnissä olevaan tietokannanhallintajärjestelmään. Selaimessa toimivia sovelluksia käytettäessä tietokannanhallintajärjestelmä toimii palvelinohjelmiston -- eli sovelluksen, johon selain ottaa yhteyttä -- kanssa samalla koneella, tai erillisellä koneella, johon palvelinohjelmisto ottaa yhteyden tarvittaessa.
Tutustumme seuraavaksi tietokantaa käyttävän palvelinohjelmiston toimintaan ja toteutukseen.
Projektinhallintatyökalu Maven
Jotta Javalla ja NetBeansilla tehtävään projektiin saa tietokannan käyttöön, tulee ohjelmoijan noutaa tietokanta-ajuri. Ajurien noutaminen kannattaa hoitaa ns. riippuvuuksia hallinnoivan projektinhallintatyökalun, kuten Mavenin, avulla.
Maven-projektin luominen NetBeansissa
Uuden Mavenia käyttävän projektin luominen NetBeansissa tapahtuu valitsemalla File -> New Project -> Kategoriaksi Maven ja projektiksi Java Application. Tämän jälkeen valitaan Next, ja täytetään projektin tiedot. Alla on esimerkki projektin tiedoista, projektin sijainti (Project location) on konekohtainen.
Tämän jälkeen painetaan Finish, ja projekti ilmestyy NetBeansin vasemmassa laidassa olevalle listalle. Etsi nyt projektin Project Files sisältä pom.xml-tiedosto -- se näyttää esimerkiksi seuraavalta:
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>tikape</groupId>
<artifactId>tikape</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
</project>
Koska käytössämme on Java 8, vaihdetaan sekä maven.compiler.source että maven.compiler.target -arvot muotoon 1.8.
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>tikape</groupId>
<artifactId>tikape</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
</project>
Kirjastojen lisääminen projekteihin Mavenin avulla
Kirjastot kuten tietokanta-ajurit ja web-sovelluksen luomiseen tarvittavat apukirjastot ladataan Maven-työkalun avulla. Mavenin termein kirjastoja kutsutaan riippuvuuksiksi (dependency). Lisätään esimerkiksi SQLite-ajuri projektin käyttöön.
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>tikape</groupId>
<artifactId>tikape</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.xerial</groupId>
<artifactId>sqlite-jdbc</artifactId>
<version>3.20.0</version>
</dependency>
</dependencies>
</project>
Kun NetBeans-projektista valitsee oikealla hiirennapilla Dependencies ja klikkaa Download Declared Dependencies, latautuu JDBC-ajuri projektin käyttöön.
Tietokantaa käyttävä ohjelma
Avaa projektiin liittyvä Source Packages, ja klikkaa tikape-pakkausta oikealle hiirennapilla. Valitse tämän jälkeen New -> Java Class, jonka jälkeen avautuu valikko, missä voit antaa luokalle nimen. Anna luokan nimeksi Main.
Avaa tiedosto tuplaklikkaamalla sitä. Muokkaa tiedostoa vielä siten, että se on seuraavan näköinen:
package tikape;
public class Main {
public static void main(String[] args) throws Exception {
}
}
Lisää projektiin import-komento import java.sql.*;, joka hakee kaikki SQL-kyselyihin liittyvät Javan kirjastot.
package tikape;
import java.sql.*;
public class Main {
public static void main(String[] args) throws Exception {
}
}
Avataan seuraavaksi tietokantayhteys tietokantaan testi.db, ja tehdään siellä kysely "SELECT 1", jolla pyydetään tietokantaa palauttamaan luku 1 -- käytämme tätä yhteyden testaamiseksi. Jos yhteyden luominen onnistuu, tulostetaan "Hei tietokantamaailma!", muulloin "Yhteyden muodostaminen epäonnistui".
package tikape;
import java.sql.*;
public class Main {
public static void main(String[] args) throws Exception {
Connection connection = DriverManager.getConnection("jdbc:sqlite:testi.db");
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("SELECT 1");
if(resultSet.next()) {
System.out.println("Hei tietokantamaailma!");
} else {
System.out.println("Yhteyden muodostaminen epäonnistui.");
}
}
}
Hei tietokantamaailma!
Kun suoritamme ohjelman ensimmäistä kertaa valitsemalla Run -> Run Project, SQLite luo puuttuvan tietokannan paikalle uuden tietokannan. Projektin kansiossa on nyt tiedosto testi.db, joka on tietokantamme.
Tietokantakyselyiden tekeminen
Oletetaan, että tietokannassa on tietokantataulu Pyora, jolla on sarakkeet rekisterinumero ja merkki. Jokaisen pyörän rekisterinumeron ja merkin tulostaminen tapahtuu seuraavasti.
Connection connection = DriverManager.getConnection("jdbc:sqlite:vuokraamo.db");
Statement stmt = connection.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM Pyora;");
while (rs.next()) {
String rekisterinumero = rs.getString("rekisterinumero");
String merkki = rs.getString("merkki");
System.out.println(rekisterinumero + " " + merkki);
}
stmt.close();
rs.close();
connection.close();
Käydään ylläoleva ohjelmakoodi läpi askeleittain.
-
Luomme ensin JDBC-yhteyden tietokantaan vuokraamo.db.
Connection connection = DriverManager.getConnection("jdbc:sqlite:vuokraamo.db"); -
Kyselyn tekeminen tapahtuu pyytämällä yhteydeltä Statement-oliota, jota käytetään kyselyn tekemiseen ja tulosten pyytämiseen. Metodi executeQuery suorittaa parametrina annettavan SQL-kyselyn, ja palauttaa tulokset sisältävän ResultSet-olion.
Statement statement = connection.createStatement(); ResultSet resultSet = statement.executeQuery("SELECT * FROM Pyora;"); -
Tämän jälkeen ResultSet-oliossa olevat tulokset käydään läpi. Metodia next() kutsumalla siirrytään kyselyn palauttamissa tulosriveissä eteenpäin. Kultakin riviltä voi kysyä sarakeotsikon perusteella solun arvoa. Esimerkiksi kutsu getString("rekisterinumero") palauttaa kyseisellä rivillä olevan sarakkeen "rekisterinumero" arvon String-tyyppisenä.
while(resultSet.next()) { String rekisterinumero = rs.getString("rekisterinumero"); String merkki = rs.getString("merkki"); System.out.println(rekisterinumero + " " + merkki); } -
Kun kyselyn vastauksena saadut rivit on käyty läpi, eikä niitä enää tarvita, vapautetaan niihin liittyvät resurssit.
stmt.close(); rs.close(); -
Lopulta tietokantayhteys suljetaan.
Huomaathan, että jos tietokantayhteyksiä ei sulje, jäävät ne odottamaan uusia kyselyitä. Tällöin ennemmin tai myöhemmin yhteyksiä on niin paljon auki, ettei tietokannanhallintajärjestelmä suostu uusien yhteyksien avaamiseen.connection.close();
Tietokantaa käyttävien web-sovellusten rakentaminen
Selain kommunikoi palvelimen kanssa tekemällä pyyntöjä joihin palvelin vastaa. Selain tekee pyynnön esimerkiksi kun käyttäjä kirjoittaa osoitekenttään sivun osoitteen -- esimerkiksi https://materiaalit.github.io/tikape-s17/ -- ja painaa enter. Tällöin tehdään hakupyyntö (GET) osoitteessa materiaalit.github.io olevalle palvelimelle. Palvelin vastaanottaa pyynnön, käsittelee sen -- esimerkiksi hakee haluttavan dokumentin tiedostojärjestelmästä -- ja luo käyttäjälle näytettävän sivun. Sivu palautetaan vastauksena pyynnölle tekstimuodossa. Selain päättelee vastauksen sisällön perusteella miten sivu tulee näyttää käyttäjälle ja näyttää sivun käyttäjälle.
Sivun näyttämisen yhteydessä selain hakee myös sisältöä, joihin sivu viittaa. Esimerkiksi jokainen tällä sivulla oleva kuva haetaan erikseen, aivan kuten erilaiset dynaamista toiminnallisuutta lisäävät Javascript -tiedostot sekä sivun ulkoasun tyylittelyyn liittyvät tyylitiedostot.
Käyttäjän näkökulmasta selain tekee käytännössä kahdenlaisia pyyntöjä. Hakupyynnöt (GET) liittyvät tietyssä osoitteessa olevan resurssin hakemiseen, kun taas lähestyspyynnöt (POST) liittyvät tiedon lähettämiseen tiettyyn osoitteeseen.
Tutustutaan tähän käytännössä Javalla toteutetun Spark-nimisen web-sovelluskehyksen avulla.
Spark ja ensimmäinen web-sovellus
Spark-sovelluskehyksen käyttöönotto toimii luvun 8.2 osassa "Maven-projektin luominen NetBeansissa" esitetyllä tavalla. Toisin kuin oppaassa, Maven-projektin riippuvuudeksi halutaan lisätä Spark. Tiedosto pom.xml näyttää lopuksi esimerkiksi seuraavalta:
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>tikape</groupId>
<artifactId>tikape-web-sample</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>com.sparkjava</groupId>
<artifactId>spark-core</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>
</project>
Oleellista edellä on se, että Javan versioksi on määritelty 1.8, ja sparkin versioksi 2.6.0.
Nyt voimme luoda uuden pääohjelmaluokan. Lisätään Main.java-tiedostoon rivi import spark.Spark;, jolloin käyttöömme tulee oleellisimmat Sparkin tarjoamat toiminnallisuudet. Kutsutaan tämän jälkeen Sparkin get-metodia, ja määritellään sen avulla osoite, jota palvelinohjelmistomme tulee kuuntelemaan, sekä teksti, joka palautetaan, kun selaimella tehdään pyyntö annettuun osoitteeseen.
package tikape;
import spark.Spark;
public class Main {
public static void main(String[] args) {
Spark.get("/hei", (req, res) -> {
return "Hei maailma!";
});
}
}
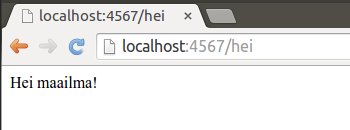
Yllä olevassa esimerkissä palvelimelle määritellään osoite /hei. Jos selaimella tehdään osoitteeseen pyyntö, pyyntöön vastataan tekstillä Hei maailma!.
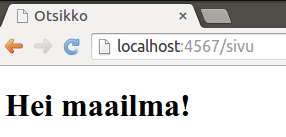
Kun ylläolevan sovelluksen käynnistää, Spark käynnistää web-palvelimen osoitteeseen http://localhost:4567, eli paikallisen koneen porttiin 4567. Palvelin on tämän jälkeen käynnissä, ja odottaa siihen tehtäviä pyyntöjä. Kun haemme web-selaimella sivua osoitteesta http://localhost:4567, palauttaa palvelin selaimelle tekstimuotoista tietoa, ja selain näyttää käyttäjälle seuraavanlaisen sivun:
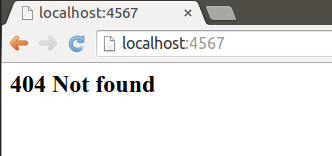
Kun teemme pyynnön osoitteeseen http://localhost:4567/hei, eli palvelinohjelmiston osoitteeseen /hei, saammekin vastaukseksi ohjelmakoodissa määrittelemämme Hei maailma!-tekstin.
Palvelimen sammuttaminen tapahtuu NetBeansissa punaista neliötä klikkaamalla. Joissakin käyttöjärjestelmissä tämä ei kuitenkaan toimi oikein, jolloin palvelin tulee sammuttaa komentoriviltä.
Saat portissa 4567 käynnissä olevan prosessin tunnuksen tietoon terminaalissa komennolla lsof -i :4567. Etsi komennon palauttamasta tulosteesta prosessin tunnus, jonka jälkeen voit sammuttaa prosessin komennolla kill -9 prosessin-tunnus.
Esimerkiksi:
> lsof -i :4567 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 9916 kayttaja 51u IPv6 0x65802ef6be5c6f29 0t0 TCP *:tram (LISTEN) >
Yllä prosessin tunnus (PID) on 9916. Tämän jälkeen prosessi sammutetaan komennolla kill -9 9916.
> lsof -i :4567 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 9916 kayttaja 51u IPv6 0x65802ef6be5c6f29 0t0 TCP *:tram (LISTEN) > kill -9 9916
Useamman osoitteen kuunteleminen
Spark-palvelimelle määritellään get-metodin avulla palvelimen kuuntelemia osoitteita. Metodikutsun yhteydessä määritellään myös palvelimen palauttama data. Palautettava data on tekstiä, mutta selain päättelee palautetun tekstin sisällön perusteella, mitä tekstille tulee tehdä. Alla olevassa ohjelmakoodissa määritellään kaksi osoitetta, joista palautetaan dataa. Toinen palauttaa aiemmin nähdyn tekstin Hei maailma!, ja toinen palauttaa tekstin Moi maailma!.
package tikape;
import spark.Spark;
public class Main {
public static void main(String[] args) {
Spark.get("/hei", (req, res) -> {
return "Hei maailma!";
});
Spark.get("/testi", (req, res) -> {
return "Moi maailma!";
});
}
}
Tiedon esittäminen selaimessa
Selain näyttää käyttäjälle palvelimelta saamansa tekstimuotoisen vastauksen. Jos vastaus on HTML-muodossa, tulkitsee selain vastauksen, ja luo sen perusteella näkymän käyttäjälle. Periaatteessa palvelimelta voisi palauttaa suoraan HTML-koodia tekstimuodossa esimerkiksi seuraavalla tavalla.
Spark.get("/testi", (req, res) -> {
return "<h1>Iso Viesti!</>";
});
HTML-koodin palauttaminen suoraan palvelinohjelmistosta on kuitenkin hyvin epätyypillistä. Käytännössä html-sivut luodaan lähes aina ensin erilliseen tiedostoon, jonka palvelin palauttaa käyttäjälle. Voimme tehdä näin myös Sparkin kautta.
Thymeleaf ja HTML-sivujen luominen
Thymeleaf on eräs väline HTML-sivujen palauttamiseen suoraan palvelinohjelmistolta. Thymeleaf tarjoaa käyttäjälle lisäksi mahdollisuuden palvelimelta saatavan datan lisäämiseksi suoraan HTML-sivulle.
Lisätään projektiin riippuvuudeksi spark-template-thymeleaf-projekti, joka tuo käyttöön Thymeleaf-kirjaston. Projektin konfiguraatio on nyt kokonaisuudessaan seuraavanlainen:
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>tikape</groupId>
<artifactId>tikape-web-sample</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>com.sparkjava</groupId>
<artifactId>spark-core</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>com.sparkjava</groupId>
<artifactId>spark-template-thymeleaf</artifactId>
<version>2.5.5</version>
</dependency>
</dependencies>
</project>
Tehdään seuraavaksi resurssikansio (resources) projektin kansioon src/main/, jos sitä ei vielä ole. Uuden kansion saa luotua NetBeansin Files-välilehdellä klikkaamalla kansiota oikealla hiirennapilla, ja valitsemalla New -> Folder. Kun kansio on luotu, pitäisi käytössä olla kansio src/main/resources. Tämän jälkeen resources-kansioon tulee vielä luoda kansio templates, johon HTML-tiedostot tullaan laittamaan.
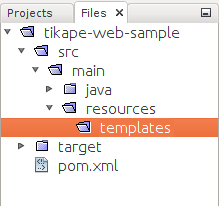
src allaolevassa kansiossa main on nyt kansio resources, jossa on taas kansio templates.
Lisätään kansioon templates uusi html-dokumentti (New -> HTML File), ja asetetaan tiedoston nimeksi index.html.
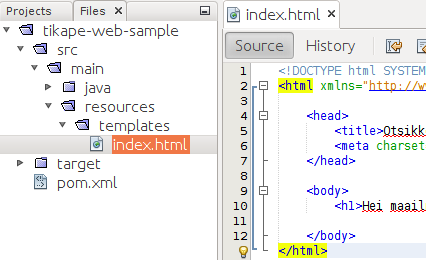
src/main/resources/templates on tiedosto index.html.Käyttämämme Thymeleaf-kirjasto olettaa, että HTML-tiedostot ovat tietyn muotoisia -- palataan tähän myöhemmin. Tässä välissä riittää, että html-sivun sisällöksi kopioi seuraavan aloitussisällön.
<!DOCTYPE html SYSTEM "http://www.thymeleaf.org/dtd/xhtml1-strict-thymeleaf-4.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org">
<head>
<title>Otsikko</title>
<meta charset="utf-8" />
</head>
<body>
<h1>Hei maailma!</h1>
</body>
</html>
Huom! Jos näet virheen 500 Internal Server Error! sekä NetBeansin lokeihin tulee viestiä "Parse errorista", tarkista, että sivun sisältö on aluksi täsmälleen ylläoleva.
Thymeleafin avulla luodun sivun palauttaminen käyttäjälle
Voimme palauttaa kansiossa src/main/java/resources/templates olevia .html-päätteisiä tiedostoja Sparkin avulla seuraavasti. Allaolevassa metodikutsussa määritellään kuunneltavaksi osoitteeksi /sivu, jonka jälkeen käyttäjälle palautetaan index-niminen sivu. Sivun nimen perusteella päätellään palautettava html-tiedosto -- nimi index muunnetaan muotoon src/main/java/resources/templates/index.html.
package tikape;
import java.util.HashMap;
import spark.ModelAndView;
import spark.Spark;
import spark.template.thymeleaf.ThymeleafTemplateEngine;
public class Main {
public static void main(String[] args) {
Spark.get("/sivu", (req, res) -> {
HashMap map = new HashMap<>();
return new ModelAndView(map, "index");
}, new ThymeleafTemplateEngine());
}
}
Kun yllä määritelty sovellus käynnistetään, ja kansiossa src/main/java/resources/templates on tiedosto index.html, näytetään tiedoston sisältö käyttäjälle. Huomaathan, että tiedoston sisällön tulee olla kuten edellisessä kappaleessa näytetty. Näkymä on käyttäjälle esimerkiksi seuraavanlainen:
Mitä tässä oikein tapahtuu? Tutkitaan sivun palauttamista vielä tarkemmin.
Spark.get("/sivu", (req, res) -> {
HashMap map = new HashMap<>();
return new ModelAndView(map, "index");
}, new ThymeleafTemplateEngine());
Metodikutsun ensimmäinen rivi lienee tuttu. Kerromme, että ohjelman tulee kuunnella osoitteeseen /sivu tehtäviä hakupyyntöjä. Tämän jälkeen tulee pyynnön käsittelyyn liittyvä lohko, josta tällä kertaa palautetaan olio, joka sisältää HashMap-olion sekä tiedon näytettävästä html-sivusta. Tämän jälkeen pyynnön käsittelyyn lisätään vielä erillinen olio, ThymeleafTemplateEngine, joka käsittelee html-sivun ennen sen palautusta.
Palvelimelta saadun tiedon näyttäminen käyttäjälle
Thymeleaf-komponentin avulla voimme lisätä html-sivulle tietoa. Tämä tapahtuu lisäämällä HashMap-olioon put-metodilla arvo, esimerkiksi map.put("teksti", "Hei mualima!");.
Spark.get("/sivu", (req, res) -> {
HashMap map = new HashMap<>();
map.put("teksti", "Hei mualima!");
return new ModelAndView(map, "index");
}, new ThymeleafTemplateEngine());
Tämän jälkeen html-sivua index.html muokataan siten, että sinne lisätään "paikka" tiedolle. Tiedon lisääminen tapahtuu lisäämällä sivulle html-elementti, jossa on attribuutti th:text, jolle annetaan HashMap-olioon lisätyn arvon nimi aaltosulkujen sisällä siten, että aaltosulkuja edeltää dollarimerkki -- eli th:text="${teksti}". Elementti voi olla vaikka h2-elementti, jolloin kokonaisuus voisi olla vaikkapa seuraava <h2 th:text="${teksti}">testi</h2>.
<!DOCTYPE html SYSTEM "http://www.thymeleaf.org/dtd/xhtml1-strict-thymeleaf-4.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org">
<head>
<title>Otsikko</title>
<meta charset="utf-8" />
</head>
<body>
<h1>Hei maailma!</h1>
<h2 th:text="${teksti}">testi</h2>
</body>
</html>
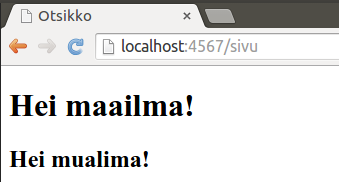
Kun käynnistämme palvelimen, ja avaamme osoitteen http://localhost:4567/sivu, näemme seuraavanlaisen näkymän.
HashMap on ohjelmoinnissa käytettävä lokerikko, missä jokaisella lokerolla on nimi, mihin arvon voi asettaa. Alla olevassa esimerkissä luomme ensin HashMap-olion, jonka jälkeen asetamme lokeroon nimeltä teksti arvon "Hei mualima!".
HashMap map = new HashMap<>();
map.put("teksti", "Hei mualima!");
Kun HashMap-olio palautetaan pyynnön käsittelyn jälkeen -- return new ModelAndView(map, "index"); -- annetaan lokerikko Thymeleafin käyttöön.
Thymeleaf etsii annetusta HashMap-oliosta lokeroita th:text-attribuutille annetulla nimellä. Esimerkiksi kun Thymeleaf käsittelee edellä näkemämme <h2 th:text="${teksti}">testi</h2>-rivin, etsii se HashMap-oliosta lokeron nimeltä teksti, ja asettaa siinä olevan arvon elementin tekstiarvoksi. Tässä tapauksessa teksti testi korvataan HashMap-olion lokerosta teksti löytyvällä arvolla, eli tekstillä Hei mualima!.
Listojen lisääminen sivulle
Tutustutaan vielä olioiden ja listojen käsittelyyn Thymeleafin avulla. Oletetaan, että käytössämme on seuraava Opiskelija-luokka.
package tikape;
public class Opiskelija {
private Integer id;
private String nimi;
public Opiskelija() {
}
public Opiskelija(Integer id, String nimi) {
this.id = id;
this.nimi = nimi;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getNimi() {
return nimi;
}
public void setNimi(String nimi) {
this.nimi = nimi;
}
}
Jokaisella opiskelijalla on siis tunnus sekä nimi. Tämän lisäksi, jokaiselle opiskelijalle kuuluu get- ja set-metodit, joiden avulla opiskelijaan liittyviä tietoja voidaan hakea ja muokata. Muokataan aiempaa ohjelmaamme siten, että käytössämme on listallinen opiskelijoita, jotka palautetaan sivun mukana thymeleafin käsiteltäväksi.
package tikape;
import java.util.ArrayList;
import java.util.HashMap;
import spark.ModelAndView;
import spark.Spark;
import spark.template.thymeleaf.ThymeleafTemplateEngine;
public class Main {
public static void main(String[] args) {
ArrayList<Opiskelija> opiskelijat = new ArrayList<>();
opiskelijat.add(new Opiskelija(1, "Ada Lovelace"));
opiskelijat.add(new Opiskelija(2, "Charles Babbage"));
Spark.get("/opiskelijat", (req, res) -> {
HashMap map = new HashMap<>();
map.put("teksti", "Hei mualima!");
map.put("opiskelijat", opiskelijat);
return new ModelAndView(map, "index");
}, new ThymeleafTemplateEngine());
}
}
Lisätään vielä opiskelijat html-sivulle.
<!DOCTYPE html SYSTEM "http://www.thymeleaf.org/dtd/xhtml1-strict-thymeleaf-4.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org">
<head>
<title>Otsikko</title>
<meta charset="utf-8" />
</head>
<body>
<h1>Hei maailma!</h1>
<h2 th:text="${teksti}">testi</h2>
<h2 th:text="${opiskelijat}">opiskelijatesti</h2>
</body>
</html>
Kun nyt haemme sivua, saamme (esimerkiksi) seuraavanlaisen näkymän.
![Osoite http://localhost:4567/opiskelijat avattuna. Sivulla näkyy teksti Hei maailma!
Hei mualima!
[tikape.Opiskelija@4f4a43a5, tikape.Opiskelija@41ce9964]](../img/viikko6/spark-index-opiskelijat-c5158e68.png)
Listan tulostaminen ja läpikäynti Thymeleafin avulla
Ohjelmointikursseilla listan läpikäymiseen käytetään muunmuassa while ja for-lausetta. Voisimme esimerkiksi tulostaa opiskelijoihin liittyvät tiedot seuraavasti Java-koodissa:
ArrayList<Opiskelija> opiskelijat = new ArrayList<>();
opiskelijat.add(new Opiskelija(1, "Ada Lovelace"));
opiskelijat.add(new Opiskelija(2, "Charles Babbage"));
for (int i = 0; i < opiskelijat.size(); i++) {
Opiskelija opiskelija = opiskelijat.get(i);
System.out.println("id: " + opiskelija.getId());
System.out.println("nimi: " + opiskelija.getNimi());
System.out.println();
}
id: 1 nimi: Ada Lovelace id: 2 nimi: Charles Babbage
Vastaavanlainen toiminnallisuus löytyy myös Thymeleafista. Voimme käydä listan elementit läpi attribuutilla th:each, jolle annetaan sekä läpikäytävän listan nimi -- taas aaltosulkujen sisällä siten, että aaltosulkuja ennen on dollarimerkki -- sekä yksittäisen listaelementin nimi, jota käytetään listaa läpikäydessä. Alla olevassa esimerkissä aloitetaan lista ul-elementin avulla. Jokaiselle opiskelijalle luodaan oma li-elementti (<li th:each="opiskelija: ${opiskelijat}">...</li>), jonka sisälle haetaan käsiteltävään opiskelijaan liittyvät tiedot.
<!DOCTYPE html SYSTEM "http://www.thymeleaf.org/dtd/xhtml1-strict-thymeleaf-4.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org">
<head>
<title>Otsikko</title>
<meta charset="utf-8" />
</head>
<body>
<h1>Hei maailma!</h1>
<h2 th:text="${teksti}">testi</h2>
<ul>
<li th:each="opiskelija: ${opiskelijat}">
<span th:text="${opiskelija.id}">1</span> <span th:text="${opiskelija.nimi}">Essi esimerkki</span>
</li>
</ul>
</body>
</html>
Kun sivua tarkastelee selaimesta, näyttää se seuraavalta:
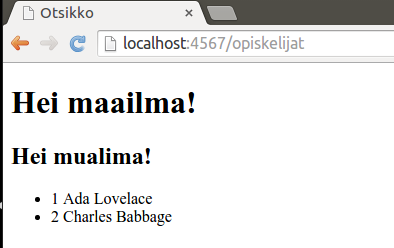
Edelläolevassa esimerkissä käydään listalla olevat opiskelijat läpi, ja luodaan niiden perusteella sivulle dataa. Mielenkiintoista esimerkissä on se, että yksittäisen opiskelijan id-kenttään pääsee käsiksi sanomalla (esimerkiksi) <span th:text="${opiskelija.id}">1</span>. Tässä Thymeleaf päättelee opiskelija.id-kohdassa, että sen tulee etsiä opiskelija-oliolta getId()-metodia, kutsua sitä, ja asettaa tähän metodin palauttama arvo.
Tiedon lähettäminen palvelimelle
Tiedon lähettäminen (POST) palvelimelle tapahtuu HTML-sivuilla lomakkeen avulla.
Lomakkeen määrittely
Lomakkeelle (form) määritellään metodiksi (method) lähetys, eli POST, sekä osoite, johon lomakkeella oleva tieto tulee lähettää. Lomakkeen määrittely alkaa muodossa <form method="POST" action="/osoite">, missä /osoite on palvelimelle määritelty osoite. Tätä seuraa erilaiset lomakkeen kentät, esimerkiksi tekstikenttä (<input type="text" name="nimi"/>), johon syötettävälle arvolle tulee name-kentässä määritelty nimi. Lomakkeeseen tulee lisätä myös nappi (<input type="submit" value="Lähetä!"/>), jota painamalla lomake lähetetään. Lomake voi olla kokonaisuudessaan esimerkiksi seuraava:
<form method="POST" action="/opiskelijat">
Nimi:<br/>
<input type="text" name="nimi"/><br/>
<input type="submit" value="Lisää opiskelija"/>
</form>
Yllä määritelty lomake näyttää selaimessa (esimerkiksi) seuraavalta:
Nappia painamalla lomakkeeseen kirjoitettu tieto yritetään tämän materiaalin osoitteessa olevaan polkuun /opiskelijat. Ei taida onnistua..
Tiedon lähetyksen vastaanotto
Palvelimelle määritellään tietoa vastaanottava osoite metodilla post, jolle annetaan parametrina kuunneltava osoite, sekä koodi, joka suoritetaan kun osoitteeseen lähetetään tietoa. Pyynnön mukana lähetettävään tietoon -- esimerkiksi ylläolevalla lomakkeella voidaan lähettää nimi-niminen arvo palvelimelle -- pääsee käsiksi req-nimisen parametrin metodilla queryParams.
Spark.post("/opiskelijat", (req, res) -> {
String nimi = req.queryParams("nimi");
System.out.println("Vastaanotettiin " + nimi);
return "Kerrotaan siitä tiedon lähettäjälle: " + nimi;
});
Samaa osoitetta voi käsitellä sekä get, että post-metodilla. Palvelin voi siis palauttaa selaimen tekemiin hakupyyntöihin tiettyä dataa -- esimerkiksi vaikkapa lomakkeen -- ja käsitellä lähetetyn tiedon erikseen. Alla on määritelty kaksi /opiskelijat-osoitetta kuuntelevaa toiminnallisuutta. Toinen palauttaa merkkijonona muotoillun lomakkeen (tämä kannattaisi tehdä erilliselle HTML-sivulle!), toinen taas palauttaa tekstin, jonka osana on lomakkeella lähetetty nimi.
package tikape;
import spark.Spark;
public class Main {
public static void main(String[] args) {
Spark.get("/opiskelijat", (req, res) -> {
return "<form method=\"POST\" action=\"/opiskelijat\">\n"
+ "Nimi:<br/>\n"
+ "<input type=\"text\" name=\"nimi\"/><br/>\n"
+ "<input type=\"submit\" value=\"Lisää opiskelija\"/>\n"
+ "</form>";
});
Spark.post("/opiskelijat", (req, res) -> {
String nimi = req.queryParams("nimi");
return "Kerrotaan siitä tiedon lähettäjälle: " + nimi;
});
}
}
Kun palvelin käynnistetään ylläolevalla ohjelmalla, löytyy osoitteesta http://localhost:4567/opiskelijat seuraavanlainen sivu:
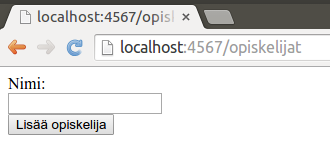
Täytetään lomake -- vaikkapa nimellä Edgar F. Codd.
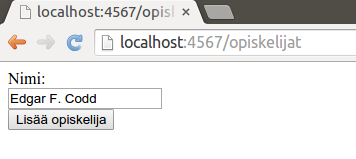
Kun painamme nyt nappia Lisää opiskelija, tekstikentän sisältö lähetetään palvelimelle lomakkeen action-kentän määrittelemään osoitteeseen. Jos lomakkeessa määritelty metodiksi (method) post, tehdään lähetyspyyntö. Jos action kenttä on /opiskelijat ja metodi POST, lähetettävä tieto vastaanotetaan ja suoritetaan rivillä post("/opiskelijat", (req, res) -> { alkavalla ohjelmakoodilla. Aiemmin määritellyllä ohjelmalla käyttäjälle näytetään seuraavanlainen sivu:

Tiedon säilöminen palvelimelle hetkellisesti
Voimme tallentaa vastaanotetun tiedon palvelimelle palvelimen käynnissäoloajaksi säilömällä sen esimerkiksi ArrayList-tyyppiseen listaan. Muokataan ylläolevaa aiempaa koodia siten, että hakupyyntö osoitteeseen /opiskelijat palauttaa sekä lomakkeen että tallennetut opiskelijat. Tämän lisäksi, lisätään osoitteeseen /opiskelijat tehtävän lähetyspyynnön käsittelyyn lomakkeelta saatavan nimi-kentän lisääminen ohjelmassa olevaan listaan.
package tikape;
import java.util.ArrayList;
import spark.Spark;
public class Main {
public static void main(String[] args) {
ArrayList<String> nimet = new ArrayList<>();
Spark.get("/opiskelijat", (req, res) -> {
String opiskelijat = "";
for (String nimi : nimet) {
opiskelijat += nimi + "<br/>";
}
return opiskelijat
+ "<form method=\"POST\" action=\"/opiskelijat\">\n"
+ "Nimi:<br/>\n"
+ "<input type=\"text\" name=\"nimi\"/><br/>\n"
+ "<input type=\"submit\" value=\"Lisää opiskelija\"/>\n"
+ "</form>";
});
Spark.post("/opiskelijat", (req, res) -> {
String nimi = req.queryParams("nimi");
nimet.add(nimi);
return "Kerrotaan siitä tiedon lähettäjälle: " + nimi;
});
}
}
Nyt kun osoitteessa /opiskelijat olevalla lomakkeella tehdään useampia pyyntöjä, tulee lomakesivulle lisää näytettäviä opiskelijoita.
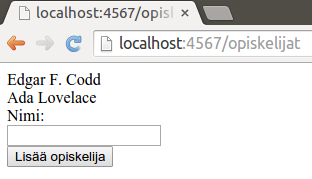
Tiedon lisääminen edellisellä tavalla johtaa tilanteeseen, missä käyttäjä näkee lisäyksen yhteydessä vain listasivun. Hyvä käytäntö on lisätä lisäystoiminnallisuuden loppuun uudelleenohjauskutsu, jonka perusteella selain pyydetään tekemään uusi kutsu osoitteeseen, joka sisältää tietojen listaamisen. Tämä onnistuu esimerkiksi seuraavasti.
Spark.post("/opiskelijat", (req, res) -> {
String nimi = req.queryParams("nimi");
nimet.add(nimi);
res.redirect("/opiskelijat");
return "";
});
Useamman kentän lähettäminen
HTML-lomakkeelle voidaan määritellä useampia kenttiä. Jokaisella kentällä tulee olla eri nimi, jotta palvelimella voidaan ottaa lomakkeen tiedon vastaan. Esimerkiksi nimeä ja osoitetta voisi kerätä vaikkapa seuraavanlaisella lomakkeella.
<form method="POST" action="/opiskelijat">
Nimi:<br/>
<input type="text" name="nimi"/><br/>
Osoite:<br/>
<input type="text" name="osoite"/><br/>
<input type="submit" value="Lisää opiskelija"/>
</form>
Lomake näyttää selaimessa (esimerkiksi) seuraavalta:
Tehtäväpohjassa on valmiina web-sovellus, joka näyttää käyttäjälle tehtäviä.
Lisää sovellukseen toiminnallisuus, jonka avulla käyttäjälle voi lisätä tehtäviä. Toiminnallisuuden lisääminen kannattanee aloittaa seuraavilla askeleilla: (1) lisää sovellukseen lomake tehtävien lisäämistä varten, (2) lisää sovellukseen osoite, joka kuuntelee lomakkeen lähetystä -- lisää tallennustoiminnallisuuden loppuun myös uudelleenohjaus, ja (3) tallenna lähetetty tieto listalle.
Huomaa, että joudut sammuttamaan palvelimen aina muutosten yhteydessä. Toisin sanoen, ohjelmointiympäristö ei automaattisesti päivitä muutoksia palvelimelle. Muistathan myös sammuttaa palvelimen kun tehtävä on valmis -- näin palvelin ei jää estämään muiden palvelinten käynnistymistä.
Kun sovellus toimii, palauta se TMC:lle.
Tietokannan käyttöönotto
Tietokannan käyttöönotto onnistuu kuten Java-ohjelmissa yleensä. Tällä kertaa tosin hyödynnämme tietokantaa osana web-sovellusta. Opiskelijoiden noutaminen tietokannasta tapahtuisi esimerkiksi seuraavasti:
package tikape;
import java.util.HashMap;
import spark.ModelAndView;
import spark.Spark;
import spark.template.thymeleaf.ThymeleafTemplateEngine;
import tikape.database.Database;
import tikape.database.OpiskelijaDao;
public class Main {
public static void main(String[] args) throws Exception {
Database database = new Database("jdbc:sqlite:opiskelijat.db");
database.setDebugMode(true);
OpiskelijaDao opiskelijaDao = new OpiskelijaDao(database);
Spark.get("/opiskelijat", (req, res) -> {
HashMap map = new HashMap<>();
map.put("opiskelijat", opiskelijaDao.findAll());
return new ModelAndView(map, "index");
}, new ThymeleafTemplateEngine());
}
}
Tehtäväpohjassa on valmiina sama web-sovellus kuin edellisessä tehtävässä, eli sovellus joka näyttää käyttäjälle tehtäviä. Tässä tehtävässä toteutetaan sekä edellisen tehtävän toiminnallisuus -- jos teit edellisen tehtävän, voit kopioida edellisen osan toiminnallisuuden tänne -- ja lisätään mukaan tietokanta.
Edellisen osan tehtävänannosta: Lisää sovellukseen toiminnallisuus, jonka avulla käyttäjälle voi lisätä tehtäviä. Toiminnallisuuden lisääminen kannattanee aloittaa seuraavilla askeleilla: (1) lisää sovellukseen lomake tehtävien lisäämistä varten, (2) lisää sovellukseen osoite, joka kuuntelee lomakkeen lähetystä -- lisää tallennustoiminnallisuuden loppuun myös uudelleenohjaus, ja (3) tallenna lähetetty tieto listalle.
Muokkaa tätä sovellusta siten, että tehtävät haetaan tietokannasta. Tämän onnistumiseen tarvitset seuraavat askeleet: (1) määrittele tehtäville tietokantataulut, (2) luo tarvittavat luokat ja toiminnallisuudet tietokantakyselyiden tekemiseen, ja (3) vaihda tehtäväpohjan lista tietokannasta haettavaan listaukseen.
Huomaa, että joudut sammuttamaan palvelimen aina muutosten yhteydessä. Toisin sanoen, ohjelmointiympäristö ei automaattisesti päivitä muutoksia palvelimelle. Muistathan myös sammuttaa palvelimen kun tehtävä on valmis -- näin palvelin ei jää estämään muiden palvelinten käynnistymistä.
Kun sovellus toimii, palauta se TMC:lle.
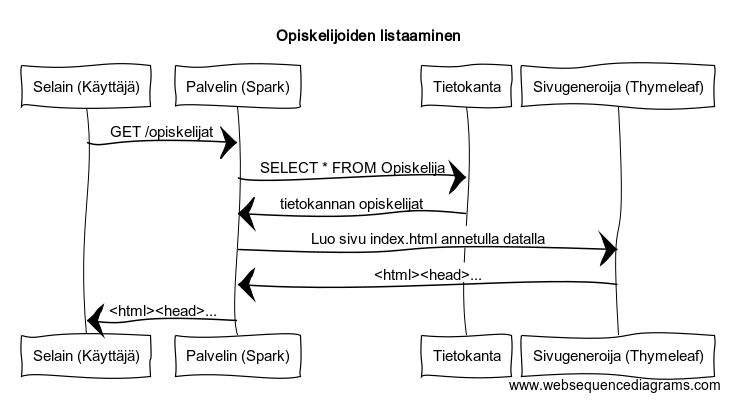
Sekvenssikaaviot
Sekvenssikaaviot ovat järjestelmien (ja olioiden) vuorovaikutuksen visualisointiin käytettävä menetelmä. Sekvenssikaaviossa järjestelmät kuvataan pystysuorina viivoina ja järjestelmien väliset kutsut vaakasuorina viivoina. Aika kulkee ylhäältä alas. Järjestelmät kuvataan laatikoina sekvenssikaavion ylälaidassa, joista pystysuorat viivat lähtevät. Järjestelmien kutsuihin merkitään oleellinen kuvaustieto, esimerkiksi olioiden yhteydessä metodin nimi tai korkeammalla tasolla järjestelmän toimintaa kuvattavaessa haluttu toiminto. Kutsun palauttama tieto piirretään palaavana katkoviivana.
Alla on kuvattuna tilanne, missä käyttäjä haluaa hakea palvelimelta kaikki opiskelijat (vastaa edellisen luvun lopussa olevan sovellusken tarjoamaa toiminnallisuutta.