Osaa käsitellä listassa olevaa tietoa virtana (stream-metodi) sekä tuntee muutamia virran perusoperaatioita (filter, map, collect). Tuntee käsitteen tiedosto. Osaa lukea tietoa erilaisista tietolähteistä (mm. tiedosto, verkko). Ymmärtää hajautustaulun periatteen. Osaa kirjoittaa hajautustaulua käyttäviä ohjelmia. Tutustuu sovelluksen pilkkomisen useampaan vastuualueeseen (tekstikäyttöliittymä, sovelluslogiikka).
Lista arvojen virtana
Tutustutaan listan läpikäyntiin arvojen virtana (stream). Virta on menetelmä tietoa sisältävän kokoelman läpikäyntiin siten, että ohjelmoija määrittelee kullekin listan arvolle suoritettavan toiminnallisuuden. Indeksistä tai kullakin hetkellä käsiteltävästä muuttujasta ei pidetä kirjaa.
Virran avulla ohjelmoija määrittelee funktioketjun, joita kutsutaan tietokokoelman arvoille. Virran avulla voi muuntaa tietoa muodosta toiseen, mutta virta ei muuta alkuperäisen tietokokoelman arvoja.
Tutustutaan virran käyttöön konkreettisen esimerkin kautta. Tarkastellaan seuraavaa ongelmaa:
Kirjoita ohjelma, joka lukee käyttäjältä syötteitä ja tulostaa niihin liittyen tilastoja. Kun käyttäjä syöttää merkkijonon "loppu", lukeminen lopetetaan. Muut syötteet ovat lukuja. Kun syötteiden lukeminen lopetetaan, ohjelma tulostaa kolmella jaollisten positiivisten lukujen lukumäärän sekä kaikkien lukujen keskiarvon.
// alustetaan lukija ja lista, johon syotteet luetaan
Scanner lukija = new Scanner(System.in);
ArrayList<String> syotteet = new ArrayList<>();
// luetaan syotteet
while (true) {
String rivi = lukija.nextLine();
if (rivi.equals("loppu")) {
break;
}
syotteet.add(rivi);
}
// selvitetään kolmella jaollisten lukumaara
long kolmellaJaollistenLukumaara = syotteet.stream()
.mapToInt(s -> Integer.parseInt(s))
.filter(luku -> luku % 3 == 0)
.count();
// selvitetään keskiarvo
double keskiarvo = syotteet.stream()
.mapToInt(s -> Integer.parseInt(s))
.average()
.getAsDouble();
// tulostetaan tilastot
System.out.println("Kolmella jaollisia: " + kolmellaJaollistenLukumaara);
System.out.println("Lukujen keskiarvo: " + keskiarvo);
Tarkastellaan tarkemmin yllä kuvatun ohjelman osaa, missä luettuja syötteitä käsitellään virtana.
// selvitetään kolmella jaollisten lukumaara
long kolmellaJaollistenLukumaara = syotteet.stream()
.mapToInt(s -> Integer.parseInt(s))
.filter(luku -> luku % 3 == 0)
.count();
Virta luodaan ArrayList-oliosta metodilla stream(). Tämän jälkeen merkkijonomuotoiset arvot muunnetaan kokonaislukumuotoon virran metodilla mapToInt(arvo -> muunnos) -- muunto toteutetaan Integer-luokan tarjoamalla parseInt-metodilla, jota olemme käyttäneet aiemminkin. Seuraavaksi rajaamme metodilla filter(arvo -> rajausehto) käsiteltäväksi vain ne luvut, jotka ovat kolmella jaollisia. Lopulta kutsumme virran metodia count(), joka laskee virran alkioiden lukumäärän ja palauttaa sen long-tyyppisenä muuttujana.
Tarkastellaan tämän jälkeen listan alkioiden keskiarvon laskemiseen tarkoitettua ohjelmaa.
// selvitetään keskiarvo
double keskiarvo = syotteet.stream()
.mapToInt(s -> Integer.parseInt(s))
.average()
.getAsDouble();
Keskiarvon laskeminen onnistuu virrasta, jolle on kutsuttu mapToInt-metodia. Kokonaislukuja sisältävällä virralla on metodi average(), joka palauttaa OptionalDouble-tyyppisen olion. Oliolla on metodi getAsDouble(), joka palauttaa listan arvojen keskiarvon double-tyyppisenä muuttujana.
Lyhyt yhteenveto tähän mennessä tutuiksi tulleista virtaan liittyvistä metodeista.
| Tarkoitus ja metodi | Oletukset |
|---|---|
Virran luominen: stream()
|
Metodia kutsutaan kokoelmalle kuten ArrayList-oliolle. Luotavalle virralle tehdään jotain. |
Virran muuntaminen kokonaislukuvirraksi: mapToInt(arvo -> toinen)
|
Virta muuntuu kokonaislukuja sisältäväksi virraksi. Merkkijonoja sisältävä muunnos voidaan tehdä esimerkiksi Integer-luokan parseInt-metodin avulla. Kokonaislukuja sisältävälle virralle tehdään jotain. |
Arvojen rajaaminen: filter(arvo -> hyvaksymisehto)
|
Virrasta rajataan pois ne arvot, jotka eivät täytä hyväksymisehtoa. "Nuolen" oikealla puolella on lauseke, joka palauttaa totuusarvon. Jos totuusarvo on true, arvo hyväksytään virtaan. Jos totuusarvo on false, arvoa ei hyväksytä virtaan. Rajatuille arvoille tehdään jotain.
|
Keskiarvon laskeminen: average()
|
Palauttaa OptionalDouble-tyyppisen olion, jolla on double tyyppisen arvon palauttava metodi getAsDouble(). Metodin average() kutsuminen onnistuu kokonaislukuja sisältävälle virralle (luominen onnistuu mapToInt-metodilla.
|
Virrassa olevien alkioiden lukumaara: count()
|
Palauttaa virrassa olevien alkioiden lukumäärän long-tyyppisenä arvona.
|
Harjoitellaan lukujen lukemista listalle sekä listan arvojen keskiarvon laskemista virran avulla.
Toteuta ohjelma, joka lukee käyttäjältä syötteitä. Jos käyttäjä syöttää merkkijonon "loppu", lukeminen lopetetaan. Muut syötteet ovat lukuja. Kun käyttäjä syöttää merkkijonon "loppu", ohjelman tulee tulostaa syötettyjen lukujen keskiarvo.
Kirjoita syötteitä, "loppu" lopettaa. 2 4 6 loppu Lukujen keskiarvo: 4.0
Kirjoita syötteitä, "loppu" lopettaa. -1 1 2 loppu Lukujen keskiarvo: 0.6666666666666666
Harjoitellaan lukujen lukemista listalle sekä listan arvojen rajaamista virran avulla.
Toteuta ohjelma, joka lukee käyttäjältä syötteitä. Jos käyttäjä syöttää merkkijonon "loppu", lukeminen lopetetaan. Muut syötteet ovat lukuja. Kun käyttäjä syöttää merkkijonon "loppu", syötteiden lukeminen lopetetaan.
Tämän jälkeen käyttäjältä kysytään tulostetaanko negatiivisten vai positiivisten lukujen keskiarvo (n vai p). Jos käyttäjä syöttää merkkijonon "n", tulostetaan negatiivisten lukujen keskiarvo, muulloin tulostetaan positiivisten lukujen keskiarvo.
Kirjoita syötteitä, "loppu" lopettaa.
-1
1
2
loppu
Tulostetaanko negatiivisten vai positiivisten lukujen keskiarvo? (n/p)
n
Negatiivisten lukujen keskiarvo: -1.0
Kirjoita syötteitä, "loppu" lopettaa.
-1
1
2
loppu
Tulostetaanko negatiivisten vai positiivisten lukujen keskiarvo? (n/p)
p
Positiivisten lukujen keskiarvo: 1.5
x -> ???
Virran arvoja käsitellään virtaan liittyvillä metodeilla. Arvoja käsittelevät metodit saavat parametrinaan funktion, joka kertoo mitä kullekin arvolle tulee tehdä. Funktion toiminnallisuus on metodikohtaista: rajaamiseen käytetylle metodille filter annetaan funktio, joka palauttaa totuusarvoisen muuttujan arvon true tai false, riippuen halutaanko arvo säilyttää virrassa; muuntamiseen käytetylle metodille mapToInt annetaan funktio, joka muuntaa arvon kokonaisluvuksi, jne.
Miksi funktiot kirjoitetaan muodossa luku -> luku > 5?
Kyseinen kirjoitusmuoto on Javan tarjoama lyhenne. Saman funktion voi kirjoittaa useammalla eri tavalla -- funktio sisältää sekä funktion parametrien määrittelyn että funktion rungon. Saman voi kirjoittaa useammassa muodossa, kts. alla.
// alkuperäinen
.filter(luku -> luku > 5)
// on sama kuin
.filter((Integer luku) ->
if (luku > 5) {
return true;
}
return false;
})
Käytännössä kyseessä on ns. anonyymi funktio. Saman voi kirjoittaa myös eksplisiittisesti niin, että ohjelmaan määrittelee staattisen metodin, jota kutsutaan virran metodista. Tämä tapahtuisi seuraavasti.
public class Rajaajat {
public static boolean vitostaSuurempi(int luku) {
return luku > 5;
}
}
// alkuperäinen
.filter(luku -> luku > 5)
// on sama kuin
.filter(luku -> Rajaajat.vitostaSuurempi(luku))
// on sama kuin
.filter(Rajaajat::vitostaSuurempi);
Virran arvoja käsittelevät funktiot eivät voi muuttaa funktion ulkopuolisten muuttujien arvoja. Kyse on käytännössä lähes samasta kuin metodeja kutsuessa -- metodia kutsuttaessa metodin ulkopuolisiin muuttujiin ei pääse käsiksi. Funktioiden tilanteessa funktion ulkopuolisten muuttujien arvoja voi lukea olettaen, että luettavien muuttujien arvot eivät muutu lainkaan ohjelmassa.
Virran metodit
Virran metodit voi jakaa karkeasti kahteen eri ryhmään: virran (1) arvojen käsittelyyn tarkoitettuihin välioperaatioihin sekä (2) käsittelyn lopettaviin pääteoperaatiohin. Edellisessä esimerkissä nähdyt metodit filter ja mapToInt ovat välioperaatioita. Välioperaatiot palauttavat arvonaan virran, jonka käsittelyä voi jatkaa -- käytännössä välioperaatioita voi olla käytännössä ääretön määrä ketjutettuna peräkkäin (pisteellä eroteltuna). Toisaalta edellisessä esimerkissä nähty metodi average on pääteoperaatio. Pääteoperaatio palauttaa käsiteltävän arvon, joka luodaan esimerkiksi virran arvoista.
Alla olevassa kuvassa on kuvattu virran toimintaa. Lähtötilanteena (1) on lista, jossa on arvoja. Kun listalle kutsutaan stream()-metodia, (2) luodaan virta listan arvoista. Arvoja käsitellään tämän jälkeen yksitellen. Virran arvoja voidaan (3) rajata metodilla filter. Tämä poistaa virrasta ne arvot, jotka ovat rajauksen ulkopuolella. Virran metodilla map voidaan (4) muuntaa virrassa olevia arvoja muodosta toiseen. Metodi collect (5) kerää virrassa olevat arvot arvot sille annettuun kokoelmaan, esim. listalle.
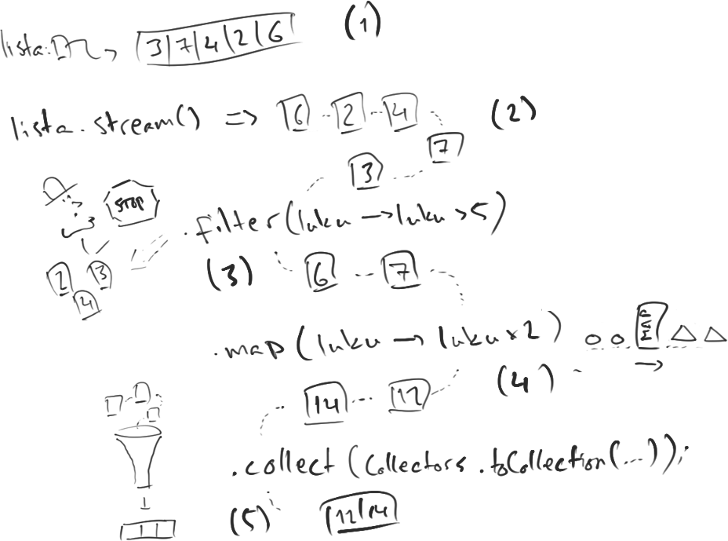
Alla vielä yllä olevan kuvan kuvaama esimerkki ohjelmakoodina.
ArrayList<Integer> lista = new ArrayList<>();
lista.add(3);
lista.add(7);
lista.add(4);
lista.add(2);
lista.add(6);
ArrayList<Integer> luvut = lista.stream()
.filter(luku -> luku > 5)
.map(luku -> luku * 2)
.collect(Collectors.toCollection(ArrayList::new));
Pääteoperaatiot
Tarkastellaan tässä kolmea pääteoperaatiota: listan arvojen lukumäärän selvittämistä count-metodin avulla, listan arvojen läpikäyntiä forEach-metodin avulla sekä listan arvojen keräämistä tietorakenteeseen collect-metodin avulla.
Metodi count kertoo virran alkioiden lukumäärän long-tyyppisenä muuttujana.
ArrayList<Integer> luvut = new ArrayList<>();
luvut.add(3);
luvut.add(2);
luvut.add(17);
luvut.add(6);
luvut.add(8);
System.out.println("Lukuja: " + luvut.stream().count());
Lukuja: 5
Metodi forEach kertoo mitä kullekin listan arvolle tulee tehdä ja samalla päättää virran käsittelyn. Alla olevassa esimerkissä luodaan ensin numeroita sisältävä lista, jonka jälkeen tulostetaan vain kahdella jaolliset luvut.
ArrayList<Integer> luvut = new ArrayList<>();
luvut.add(3);
luvut.add(2);
luvut.add(17);
luvut.add(6);
luvut.add(8);
luvut.stream()
.filter(luku -> luku % 2 == 0)
.forEach(luku -> System.out.println(luku));
2 6 8
Virran arvojen kerääminen toiseen kokoelmaan onnistuu metodin collect avulla. Alla olevassa esimerkissä luodaan uusi lista annetun positiivisista arvoista.
ArrayList<Integer> luvut = new ArrayList<>();
luvut.add(3);
luvut.add(2);
luvut.add(-17);
luvut.add(-6);
luvut.add(8);
ArrayList<Integer> positiiviset = luvut.stream()
.filter(luku -> luku > 0)
.collect(Collectors.toCollection(ArrayList::new));
positiiviset.stream()
.forEach(luku -> System.out.println(luku));
3 2 8
Tehtävässä harjoitellaan virran filter ja collect-metodien käyttöä.
Tehtäväpohjassa on annettuna metodirunko public static ArrayList<Integer> jaolliset(ArrayList<Integer> luvut). Toteuta metodirunkoon toiminnallisuus, kerää parametrina saadulta listalta kahdella, kolmella tai viidellä jaolliset luvut, ja palauttaa ne uudessa listassa. Metodille parametrina annetun listan ei tule muuttua.
ArrayList<Integer> luvut = new ArrayList<>();
luvut.add(3);
luvut.add(2);
luvut.add(-17);
luvut.add(-5);
luvut.add(7);
ArrayList<Integer> jaolliset = jaolliset(luvut);
jaolliset.stream()
.forEach(luku -> System.out.println(luku));
3 2 -5
Välioperaatiot
Virran välioperaatiot ovat metodeja, jotka palauttavat arvonaan virran. Koska palautettava arvo on virta, voidaan välioperaatioita kutsua peräkkäin. Tyypillisiä välioperaatioita ovat arvon muuntaminen muodosta toiseen map sekä sen erityistapaus mapToInt, arvojen rajaaminen filter, uniikkien arvojen tunnistaminen distinct sekä arvojen järjestäminen sorted (mikäli mahdollista).
Tarkastellaan näitä metodeja muutaman ongelman avulla. Oletetaan, että käytössämme on seuraava luokka Henkilo.
public class Henkilo {
private String etunimi;
private String sukunimi;
private int syntymavuosi;
public Henkilo(String etunimi, String sukunimi, int syntymavuosi) {
this.etunimi = etunimi;
this.sukunimi = sukunimi;
this.syntymavuosi = syntymavuosi;
}
public String getEtunimi() {
return this.etunimi;
}
public String getSukunimi() {
return this.sukunimi;
}
public int getSyntymavuosi() {
return this.syntymavuosi;
}
}
Ongelma 1: Saat käyttöösi listan henkilöitä. Tulosta ennen vuotta 1970 syntyneiden henkilöiden lukumäärä.
Käytetään filter-metodia henkilöiden rajaamiseen niihin, jotka ovat syntyneet ennen vuotta 1970. Lasketaan tämän jälkeen henkilöiden lukumäärä metodilla count.
// oletetaan, että käytössämme on lista henkiloita
// ArrayList<Henkilo> henkilot = new ArrayList<>();
long lkm = henkilot.stream()
.filter(henkilo -> henkilo.getSyntymavuosi() < 1970)
.count();
System.out.println("Lukumäärä: " + lkm);
Ongelma 2: Saat käyttöösi listan henkilöitä. Kuinka monen henkilön etunimi alkaa kirjaimella "A"?
Käytetään filter-metodia henkilöiden rajaamiseen niihin, joiden etunimi alkaa kirjaimella "A". Lasketaan tämän jälkeen henkilöiden lukumäärä metodilla count.
// oletetaan, että käytössämme on lista henkiloita
// ArrayList<Henkilo> henkilot = new ArrayList<>();
long lkm = henkilot.stream()
.filter(henkilo -> henkilo.getEtunimi().startsWith("A"))
.count();
System.out.println("Lukumäärä: " + lkm);
Ongelma 3: Saat käyttöösi listan henkilöitä. Tulosta henkilöiden uniikit etunimet aakkosjärjestyksessä.
Käytetään ensin map-metodia, jonka avulla henkilö-olioita sisältävä virta muunnetaan etunimiä sisältäväksi virraksi. Tämän jälkeen kutsutaan metodia distinct, joka palauttaa virran, jossa on uniikit arvot. Seuraavaksi kutsutaan metodia sorted, joka järjestää merkkijonot. Lopulta kutsutaan metodia forEach, jonka avulla tulostetaan merkkijonot.
// oletetaan, että käytössämme on lista henkiloita
// ArrayList<Henkilo> henkilot = new ArrayList<>();
henkilot.stream()
.map(henkilo -> henkilo.getEtunimi())
.distinct()
.sorted()
.forEach(nimi -> System.out.println(nimi));
Kirjoita ohjelma, joka lukee käyttäjältä merkkijonoja. Lukeminen tulee lopettaa kun käyttäjä syöttää tyhjän merkkijonon. Tulosta tämän jälkeen käyttäjän syöttämät merkkijonot.
eka toka kolmas eka toka kolmas
Kirjoita ohjelma, joka lukee käyttäjältä lukuja. Kun käyttäjä syöttää negatiivisen luvun, lukeminen lopetetaan. Tulosta tämän jälkeen ne luvut, jotka ovat välillä 1-5.
7 14 4 5 4 -1 4 5 4
Tehtäväpohjaan on hahmoteltu ohjelmaa, joka lukee käyttäjältä syötteenä henkilötietoja. Täydennä ohjelmaa siten, että tietojen lukemisen jälkeen ohjelma tulostaa henkilöiden uniikit sukunimet aakkosjärjestyksessä.
Syötetäänkö henkilöiden tietoja, "loppu" lopettaa:
Syötä etunimi: Ada
Syötä sukunimi: Lovelace
Syötä syntymävuosi: 1815
Syötetäänkö henkilöiden tietoja, "loppu" lopettaa:
Syötä etunimi: Grace
Syötä sukunimi: Hopper
Syötä syntymävuosi: 1906
Syötetäänkö henkilöiden tietoja, "loppu" lopettaa:
Syötä etunimi: Alan
Syötä sukunimi: Turing
Syötä syntymävuosi: 1912
Syötetäänkö henkilöiden tietoja, "loppu" lopettaa: loppu
Uniikit sukunimet aakkosjärjestyksessä:
Hopper
Lovelace
Turing
Ohjelmassa ei ole valmiita automaattisia testejä. Voit kirjoittaa automaattisia testejä testiluokkaan UniikitSukunimetTest -- tässä tapauksessa olisi näppärää tehdä esimerkiksi erillinen listan palauttava metodi uniikkien sukunimien tunnistamiseen sille parametrina annetusta henkilölistasta.
Oliot ja virta
Olioiden käsittely virran metodien avulla on luontevaa. Kukin virran metodi, missä käsitellään virran arvoja, mahdollistaa myös arvoihin liittyvän metodin kutsumisen. Tarkastellaan vielä esimerkkiä, missä käytössämme on Kirjoja, joilla on kirjailijoita. Oletetaan, että kirjailijat ovat edellä kuvattuja Henkilo-olioita. Oletetaan lisäksi, että käytössämme on alla kuvattu luokka Kirja.
public class Kirja {
private Henkilo kirjailija;
private String nimi;
private int sivujenLukumaara;
public Kirja(Henkilo kirjailija, String nimi, int sivuja) {
this.kirjailija = kirjailija;
this.nimi = nimi;
this.sivujenLukumaara = sivuja;
}
public Henkilo getKirjailija() {
return this.kirjailija;
}
public String getNimi() {
return this.nimi;
}
public int getSivujenLukumaara() {
return this.sivujenLukumaara;
}
}
Oletetaan, että käytössämme on lista kirjoja. Virran metodien avulla esimerkiksi kirjailijoiden syntymävuosien keskiarvon selvittäminen onnistuu luontevasti. Ensin muunnamme kirjoja sisältävän virran henkilöitä sisältäväksi virraksi, tämän jälkeen muunnamme henkilöitä sisältävän virran syntymävuosia sisältäväksi virraksi, ja lopulta pyydämme (kokonaislukuja sisältävältä) virralta keskiarvoa.
// oletetaan, että käytössämme on lista kirjoja
// ArrayList<Kirja> kirjat = new ArrayList<>();
double keskiarvo = kirjat.stream()
.map(kirja -> kirja.getKirjailija())
.mapToInt(kirjailija -> kirjailija.getSyntymavuosi())
.average()
.getAsDouble();
System.out.println("Kirjailijoiden syntymävuosien keskiarvo: " + keskiarvo);
Vastaavasti kirjojen, joiden nimessä esiintyy sana "Potter", kirjailijoiden nimet saa selville seuraavasti.
// oletetaan, että käytössämme on lista kirjoja
// ArrayList<Kirja> kirjat = new ArrayList<>();
kirjat.stream()
.filter(kirja -> kirja.getNimi().contains("Potter"))
.map(kirja -> kirja.getKirjailija())
.forEach(kirjailija -> System.out.println(kirjailija.getEtunimi() + " " + kirjailija.getSukunimi()));
Myös monimutkaisempien merkkijonoesitysten rakentaminen on virran avulla mahdollista. Alla olevassa esimerkissä tulostamme "Kirjailijan sukunimi: Kirja" -parit aakkosjärjestyksessä.
// oletetaan, että käytössämme on lista kirjoja
// ArrayList<Kirja> kirjat = new ArrayList<>();
kirjat.stream()
.map(kirja -> kirja.getKirjailija().getSukunimi() + ": " + kirja.getNimi())
.sorted()
.forEach(nimi -> System.out.println(nimi));
Tehtäväpohjassa on edellisen osan tehtävä "Tavara, Matkalaukku ja Lastiruuma". Tässä tehtävässä tarkoituksenasi on muuttaa toistolausetta käyttävät metodit virtaa käyttäviksi metodeiksi niiltä osin, kuin tämä on mahdollista. Ohjelman toiminnallisuuden tulee säilyä samana.
Tässä tehtävässä ei ole erillisiä virran käyttämistä testaavista testejä. Kun toistolausetta hyödyntävät osiot on muunnettu virtaa käyttäviksi, palauta tehtävä. Tehtävä on kokonaisuudessaan kahden pisteen arvoinen.
Tässä tehtävässä toteutetaan ohjelma kurssipistetilastojen tulostamiseen. Ohjelmalle syötetään pisteitä (kokonaislukuja nollasta sataan), ja ohjelma tulostaa niiden perusteella arvosanoihin liittyviä tilastoja. Syötteiden lukeminen lopetetaan kun käyttäjä syöttää luvun -1. Lukuja, jotka eivät ole välillä [0-100] ei tule ottaa huomioon tilastojen laskemisessa.
Pisteiden keskiarvot
Kirjoita ohjelma, joka lukee käyttäjältä kurssin yhteispisteitä kuvaavia kokonaislukuja. Luvut väliltä [0-100] ovat hyväksyttäviä ja luku -1 lopettaa syötteen. Muut luvut ovat virhesyötteitä, jotka tulee jättää huomiotta. Kun käyttäjä syöttää luvun -1, tulostetaan (1) syötettyjen yhteispisteiden keskiarvo ja (2) hyväksyttyyn arvosanaan riittävien yhteispisteiden keskiarvo.
Hyväksytyn arvosanan saa vähintään 70 kurssipisteellä. Voit olettaa, että käyttäjä kirjoittaa aina vähintään yhden välillä [0-100] olevan kokonaisluvun. Jos hyväksyttyyn arvosanaan osuvia lukuja ei ole lainkaan, tulostetaan viiva hyväksyttyjen keskiarvon kohdalle "-".
Syötä yhteispisteet, -1 lopettaa: -42 24 42 72 80 52 -1 Pisteiden keskiarvo (kaikki): 54.0 Pisteiden keskiarvo (hyväksytyt): 76.0
Syötä yhteispisteet, -1 lopettaa: 50 51 52 -1 Pisteiden keskiarvo (kaikki): 51.0 Pisteiden keskiarvo (hyväksytyt): -
Hyväksyttyjen prosenttiosuus
Täydennä edellisessä osassa toteuttamaasi ohjelmaa siten, että ohjelma tulostaa myös hyväksymisprosentin. Hyväksymisprosentti lasketaan kaavalla 100 * hyväksytyt / osallistujat.
Syötä yhteispisteet, -1 lopettaa: 50 51 52 -1 Pisteiden keskiarvo (kaikki): 51.0 Pisteiden keskiarvo (hyväksytyt): - Hyväksymisprosentti: 0.0
Syötä yhteispisteet, -1 lopettaa: 102 -4 33 77 99 1 -1 Pisteiden keskiarvo (kaikki): 52.5 Pisteiden keskiarvo (hyväksytyt): 88.0 Hyväksymisprosentti: 50.0
Arvosanajakauma
Täydennä ohjelmaa siten, että ohjelma tulostaa myös arvosanajakauman. Arvosananajakauma muodostetaan seuraavasti.
| pistemäärä | arvosana |
|---|---|
| < 70 | hylätty eli 0 |
| < 76 | 1 |
| < 81 | 2 |
| < 86 | 3 |
| < 91 | 4 |
| >= 91 | 5 |
Jokainen koepistemäärä muutetaan arvosanaksi yllä olevan taulukon perusteella. Jos syötetty pistemäärä ei ole välillä [0-100], jätetään se huomiotta.
Arvosanajakauma tulostetaan tähtinä. Esim jos arvosanaan 5 oikeuttavia koepistemääriä on 1 kappale, tulostuu rivi 5: *. Jos johonkin arvosanaan oikeuttavia pistemääriä ei ole, ei yhtään tähteä tulostu, alla olevassa esimerkissä näin on mm. nelosten kohdalla.
Syötä yhteispisteet, -1 lopettaa: 102 -2 1 33 77 99 -1 Pisteiden keskiarvo (kaikki): 52.5 Pisteiden keskiarvo (hyväksytyt): 88.0 Hyväksymisprosentti: 50.0 Arvosanajakauma: 5: * 4: 3: 2: * 1: 0: **
Tiedostot ja tiedon lukeminen
Merkittävä osa ohjelmistoista perustuu tavalla tai toisella tiedon käsittelyyn. Musiikin toistoon tarkoitetut ohjelmistot käsittelevät musiikkitiedostoja, kuvankäsittelyohjelmat käsittelevät kuvatiedostoja. Verkossa ja mobiililaitteissa toimivat sovellukset kuten Facebook ja WhatsApp taas käsittelevät muunmuassa tietokantoihin tallennettuja henkilötietoja. Kaikissa näistä sovelluksista on yhteistä tiedon lukeminen, tiedon käsitteleminen tavalla tai toisella sekä se, että käsiteltävä tieto on loppujenlopulta tallennettu jonkinlaisessa muodossa yhteen tai useampaan tiedostoon.
Tutustutaan seuraavaksi tiedostoihin sekä erilaisiin tapoihin tiedon lukemiseen. Ensin käsite tiedosto tulee ehkäpä hieman tutummaksi. Tämän jälkeen käsittelemme jo tutuksi tullutta näppäimistöltä lukemista osana tekstikäyttöliittymää, jonka jälkeen tutustumme tiedon lukemiseen tiedostosta. Tämän jälkeen käsittelemme lyhyesti myös tiedon hakemista verkkoyhteyden yli. Tiedon lukeminen tietokannoista sekä tiedon lukeminen ja käsittely osana graafista käyttöliittymää tulee tutuksi ohjelmoinnin jatkokurssilla.
Voit käydä tarkastelemassa NetBeansissa kaikkia projektiin liittyviä tiedostoja valitsemalla Files-välilehden. Jos tiedosto on projektin juuressa, saa sen auki File-olion avulla vain nimen perusteella. Jos taas tiedosto on jossain muualla, tulee myös sen polku kertoa.
Tässä tehtävässä ei ohjelmoida, vaan tutustutaan tiedoston luomiseen.
Luo tehtäväpohjan juurikansioon (samassa kansiossa mm. kansiot src ja test) tiedosto nimeltä tiedosto.txt. Muokkaa tiedostoa, ja kirjoita tiedoston ensimmäisen rivin alkuun viesti Hei maailma.
Lukeminen näppäimistöltä
Olemme käyttäneet Scanner-luokkaa näppäimistöllä kirjoitetun syötteen lukemiseen kurssin alusta lähtien. Tyypillinen tiedon lukemiseen käytetty runko on ollut while-true -toistolause, missä lukeminen lopetetaan tiettyyn käyttäjän kirjoittamaan merkkiin tai merkkijonoon.
// luodaan Scanner-olio, joka lukee näppäimistösyötettä
Scanner lukija = new Scanner(System.in);
// jatketaan syötteen lukemista kunnes käyttäjä syöttää
// rivin "loppu"
while (true) {
String rivi = lukija.nextLine();
if (rivi.equals("loppu")) {
break;
}
// lisää luettu rivi myöhempää käsittelyä varten
// tai käsittele rivi
}
// käsittele myöhempää käsittelyä varten lisätyt rivit
Yllä Scanner-luokan konstruktorille annetaan parametrina järjestelmän syöte (System.in). Tekstikäyttöliittymissä käyttäjän kirjoittama tieto ohjataan syötevirtaan rivi kerrallaan, eli tieto lähetetään käsiteltäväksi aina kun käyttäjä painaa rivinvaihtoa.
Lukeminen tiedostosta
Tiedostot ovat tietokoneella sijaitsevia tietokokoelmia, jotka voivat sisältää vaikkapa tekstiä, kuvia, musiikkia tai niiden yhdistelmiä. Tiedoston tallennusmuoto määrittelee tiedoston sisällön sekä tavan tiedon lukemiseen. Esimerkiksi PDF-tiedostoja luetaan PDF-tiedostojen lukemiseen soveltuvalla ohjelmalla ja musiikkitiedostoja luetaan musiikkitiedostojen lukemiseen soveltuvalla ohjelmalla. Jokainen näistä ohjelmista on ihmisen luoma, ja ohjelman luoja tai luojat -- eli ohjelmoijat -- ovat osana työtään myös määritelleet tiedoston tallennusmuodon.
Tiedoston lukeminen tapahtuu Javan valmiin Files-apukirjaston avulla. Apukirjaston tarjoaman metodin lines avulla tiedostosta voidaan luoda syötevirta, jonka käsittely onnistuu edellä tutuiksi tulleilla menetelmillä. Metodi lines saa patametrikseen polun, joka luodaan apukirjaston Paths tarjoamalla metodilla get, jolle annetaan parametrina tiedostopolkua kuvaava merkkijono.
Alla olevassa esimerkissä luetaan tiedoston "tiedosto.txt" kaikki rivit, jotka lisätään ArrayList-listaan. Tiedostoja lukiessa voidaan kohdata virhetilanne, joten tiedoston lukeminen vaatii erillisen "yrittämisen" (try) sekä mahdollisen virheen kiinnioton (catch). Palaamme virhetilanteiden käsittelyyn ohjelmoinnin jatkokurssilla.
ArrayList<String> rivit = new ArrayList<>();
try {
Files.lines(Paths.get("tiedosto.txt")).forEach(rivi -> rivit.add(rivi));
} catch (Exception e) {
System.out.println("Virhe: " + e.getMessage());
}
// tee jotain luetuilla riveillä
Jos tiedosto löytyy ja sen lukeminen onnistuu, tulee ohjelman suorituksen lopussa tiedoston "tiedosto.txt" rivit olemaan listamuuttujassa rivit. Jos taas tiedostoa ei löydy, tai sen lukeminen epäonnistuu, ilmoitetaan tästä virheviestillä. Alla eräs mahdollisuus:
Virhe: tiedosto.txt (No such file or directory)
Edellä mainitun lähestymistavan lisäksi tiedoston lukemiseen voi käyttää myös tutuksi tullutta Scanner-luokkaa. Scanner-luokan konstruktorille voi antaa parametrina myös tiedosto-olion, jolloin Scanner-oliota käytetään kyseisen tiedoston sisällön lukemiseen. Lukeminen tapahtuu while-toistolauseella, jota jatketaan niin pitkään kuin Scanner-olion käsittelemässä tiedostossa on vielä lukemattomia rivejä jäljellä.
ArrayList<String> rivit = new ArrayList<>();
// luodaan lukija tiedoston lukemista varten
try (Scanner lukija = new Scanner(new File("tiedosto.txt"))) {
// luetaan kaikki tiedoston rivit
while (lukija.hasNextLine()) {
rivit.add(lukija.nextLine());
}
} catch (Exception e) {
System.out.println("Virhe: " + e.getMessage());
}
// tee jotain luetuilla riveillä
Tehtäväpohjassa tulee kaksi tekstitiedostoa: nimet.txt ja toiset-nimet.txt. Kirjoita ohjelma, joka kysyy ensin käyttäjältä luettavan tiedoston nimeä, jonka jälkeen käyttäjältä kysytään etsittävää merkkijonoa. Tämän jälkeen ohjelma lukee tiedoston ja etsii tiedostosta haluttua merkkijonoa.
Jos merkkijono löytyy, ohjelman tulee tulostaa "Löytyi!". Jos merkkijonoa ei löydy, ohjelman tulee tulostaa "Ei löytynyt.". Jos tiedoston lukeminen epäonnistuu (lukeminen päätyy virhetilanteeseen), ohjelman tulee tulostaa viesti "Tiedoston lukeminen epäonnistui.".
Minkä niminen tiedosto luetaan? nimet.txt Mitä etsitään? Antti Ei löytynyt.
Minkä niminen tiedosto luetaan? nimet.txt Mitä etsitään? ada Löytyi!
Minkä niminen tiedosto luetaan? olematon.txt Mitä etsitään? testi Tiedoston olematon.txt lukeminen epäonnistui.
Tehtäväpohjassa on valmiina toiminnallisuus vieraslistaohjelmaan, missä käyttäjän syöttämien nimien olemassaolo tarkistetaan vieraslistalta.
Ohjelmasta puuttuu kuitenkin toiminnallisuus vieraslistan lukemiseen. Muokkaa ohjelmaa siten, että vieraslistan nimet luetaan tiedostosta.
Minkä niminen tiedosto luetaan? vieraslista.txt Syötä nimiä, tyhjä rivi lopettaa. Chuck Norris Nimi ei ole listalla. Jack Baluer Nimi ei ole listalla. Jack Bauer Nimi on listalla. Jack Bower Nimi on listalla. Kiitos!
Huom! Tehtäväpohjassa on mukana kaksi tiedostoa, nimet.txt ja toiset-nimet.txt, joiden sisällöt ovat seuravat. Älä muuta näiden tiedostojen sisältöä!
nimet.txt:
ada arto leena testi
toiset-nimet.txt:
leo jarmo alicia
Toteuta ohjelma, joka lukee käyttäjältä tiedoston nimen sekä hyväksyttävien lukujen ala- ja ylärajan. Tämän jälkeen ohjelma lukee tiedoston sisältämät luvut (jokainen luku on omalla rivillään) ja ottaa huomioon vain ne luvut, jotka ovat annetulla lukuvälillä. Lopulta ohjelma tulostaa annetulla lukuvälillä olleiden lukujen lukumäärän.
Tiedosto? mittaukset-1.txt Alaraja? 15 Yläraja? 20 Lukuja: 2
Tiedosto? mittaukset-1.txt Alaraja? 0 Yläraja? 300 Lukuja: 4
Huom! Tehtäväpohjassa on mukana kaksi tiedostoa, mittaukset-1.txt ja mittaukset-2.txt, joiden sisällöt ovat seuravat. Älä muuta näiden tiedostojen sisältöä.
mittaukset-1.txt:
300 9 20 15
mittaukset-2.txt:
123 -5 12 67 -300 1902
Lukeminen verkkoyhteyden yli
Lähes kaikki verkkosivut, kuten tämäkin oppimateriaali, voidaan lukea tekstimuodossa ohjelmallista käsittelyä varten. Scanner-oliolle voi antaa konstruktorin parametrina lähes minkälaisen syötevirran tahansa. Alla olevassa esimerkissä luodaan URL-olio annetusta web-osoitteesta, pyydetään siihen liittyvää tietovirtaa, ja annetaan se uudelle Scanner-oliolle luettavaksi.
ArrayList<String> rivit = new ArrayList<>();
// luodaan lukija web-osoitteen lukemista varten
try (Scanner lukija = new Scanner(new URL("http://www.cs.helsinki.fi/home/").openStream())) {
// luetaan osoitteesta http://www.cs.helsinki.fi/home/
// saatava vastaus
while (lukija.hasNextLine()) {
rivit.add(lukija.nextLine());
}
} catch (Exception e) {
System.out.println("Virhe: " + e.getMessage());
}
// tehdään jotain vastauksella
Web-selain on oikeastaan ohjelma siinä missä muutkin ohjelmat. Toisin kuin yllä toteutettu sivun sisällön lataaja, web-selaimeen on toteutettu toiminnallisuus vastauksena tulevan HTML-muotoisen lähdekoodin tulkisemiseen ja graafisessa käyttöliittymässä näyttämiseen.
Osoitteessa http://www.icndb.com/api/ sijaitsee web-sovellus, joka tarjoaa Chuck Norris -vitsejä kaikkien vapaaseen käyttöön.
Sovellus tarjoaa muunmuassa mahdollisuuden satunnaisten vitsien hakemiseen (osoite http://api.icndb.com/jokes/random) sekä vitsien hakemiseen niihin liittyvillä numeerisilla tunnuksilla (osoite http://api.icndb.com/jokes/tunnus, missä tunnus on kokonaisluku).
Toteuta sovellus, joka tarjoaa kolme toimintoa. Jos käyttäjä kirjoittaa "lopeta", ohjelman suoritus lopetetaan. Jos käyttäjä kirjoittaa "satunnainen", ohjelma tulostaa icndb-palvelusta noudetun satunnaisen chuck norris vitsin. Jos käyttäjä kirjoittaa "vitsi numero", missä numero on kokonaisluku, ohjelma tulostaa icndb-palvelusta noudetun tietyn vitsin.
Huom! Tässä tehtävässä riittää tulostaa palvelun palauttama merkkijono kokonaisuudessaan. Merkkijono voi olla esimerkiksi muotoa { "type": "success", "value": { "id": 341, "joke": "Chuck Norris sleeps with a pillow under his gun.", "categories": [] } }.
Ohjelmassa ei ole testejä, eli testit eivät ota kantaa sovelluksen rakenteeseen tai tulostuksen ulkoasuun. Palauta sovellus kun se toimii koneellasi toivotulla tavalla.
Hajautustaulu (HashMap)
Hajautustaulu on eräs ohjelmoinnissa paljon käytetyistä tietorakenteista. Hajautustaulua käytetään kun halutaan käsitellä tietoa avain-arvo -pareina, missä avaimen perusteella voidaan lisätä, hakea ja poistaa avaimeen liittyvä arvo.
Alla olevassa esimerkissä on luotu HashMap-olio kaupunkien hakemiseen postinumeron perusteella, jonka jälkeen HashMap-olioon on lisätty neljä postinumero-kaupunki -paria. Sekä postinumero että kaupunki on esitetty merkkijonona.
HashMap<String, String> postinumerot = new HashMap<>();
postinumerot.put("00710", "Helsinki");
postinumerot.put("90014", "Oulu");
postinumerot.put("33720", "Tampere");
postinumerot.put("33014", "Tampere");
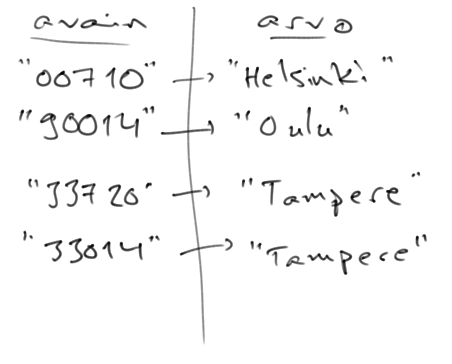
Hajautustaulua luodessa tarvitaan kaksi tyyppiparametria, avainmuuttujan tyyppi ja lisättävän arvon tyyppi. Kuten yllä, myös seuraavassa esimerkissä sekä avainmuuttujan että lisättävän arvon tyyppi on String.
HashMap<String, String> numerot = new HashMap<>();
numerot.put("Yksi", "Uno");
numerot.put("Kaksi", "Dos");
String kaannos = numerot.get("Yksi");
System.out.println(kaannos);
System.out.println(numerot.get("Kaksi"));
System.out.println(numerot.get("Kolme"));
System.out.println(numerot.get("Uno"));
Uno Dos null null
Yllä olevassa esimerkissä luodaan hajatustaulu, jonka avaimena ja tallennettavana oliona on merkkijono. Hajautustauluun lisätään tietoa kaksiparametrisella metodilla put, jolle annetaan parametrina sekä avain- että arvomuuttuja.
Yksiparametrinen metodi get palauttaa parametrina annettuun avaimeen liittyvän viitteen tai null-viitteen jos avaimella ei löydy viitettä.
Hajautustaulussa on jokaista avainta kohden korkeintaan yksi arvo. Jos hajautustauluun lisätään uusi avain-arvo -pari, missä avain on jo aiemmin liittynyt toiseen hajautustauluun tallennettuun arvoon, vanha arvo katoaa hajautustaulusta.
HashMap<String, String> numerot = new HashMap<>();
numerot.put("Uno", "Yksi");
numerot.put("Dos", "Zwei");
numerot.put("Uno", "Ein");
String kaannos = numerot.get("Uno");
System.out.println(kaannos);
System.out.println(numerot.get("Dos"));
System.out.println(numerot.get("Tres"));
System.out.println(numerot.get("Uno"));
Ein Zwei null Ein
Luo main-metodissa uusi HashMap<String,String>-olio. Tallenna luomaasi olioon seuraavien henkilöiden nimet ja lempinimet niin, että nimi on avain ja lempinimi on arvo. Käytä pelkkiä pieniä kirjaimia.
- matin lempinimi on mage
- mikaelin lempinimi on mixu
- arton lempinimi on arppa
Tämän jälkeen hae HashMapistä mikaelin lempinimi ja tulosta se.
Testit edellyttävät että kirjoitat nimet pienellä alkukirjaimella.
Viittaustyyppinen muuttuja hajautustaulussa
Tutkitaan hajautustaulun toimintaa kirjastoesimerkin avulla. Kirjastosta voi hakea kirjoja kirjan nimen perusteella. Jos haetulla nimellä löytyy kirja, palauttaa kirjasto kirjan viitteen. Luodaan ensin esimerkkiluokka Kirja, jolla on oliomuuttujina nimi, kirjaan liittyvä sisältö sekä kirjan julkaisuvuosi.
public class Kirja {
private String nimi;
private String sisalto;
private int julkaisuvuosi;
public Kirja(String nimi, int julkaisuvuosi, String sisalto) {
this.nimi = nimi;
this.julkaisuvuosi = julkaisuvuosi;
this.sisalto = sisalto;
}
public String getNimi() {
return this.nimi;
}
public void setNimi(String nimi) {
this.nimi = nimi;
}
public int getJulkaisuvuosi() {
return this.julkaisuvuosi;
}
public void setJulkaisuvuosi(int julkaisuvuosi) {
this.julkaisuvuosi = julkaisuvuosi;
}
public String getSisalto() {
return this.sisalto;
}
public void setSisalto(String sisalto) {
this.sisalto = sisalto;
}
public String toString() {
return "Nimi: " + this.nimi + " (" + this.julkaisuvuosi + ")\n"
+ "Sisältö: " + this.sisalto;
}
}
Luodaan seuraavaksi hajautustaulu, joka käyttää avaimena kirjan nimeä eli String-tyyppistä oliota, ja arvona edellä luomaamme kirjaa.
HashMap<String, Kirja> hakemisto = new HashMap<>();
Yllä oleva hajautustaulu käyttää avaimena String-oliota. Laajennetaan esimerkkiä siten, että hakemistoon lisätään kaksi kirjaa, "Järki ja tunteet" ja "Ylpeys ja ennakkoluulo".
Kirja jarkiJaTunteet = new Kirja("Järki ja tunteet", 1811, "...");
Kirja ylpeysJaEnnakkoluulo = new Kirja("Ylpeys ja ennakkoluulo", 1813, "....");
HashMap<String, Kirja> hakemisto = new HashMap<>();
hakemisto.put(jarkiJaTunteet.getNimi(), jarkiJaTunteet);
hakemisto.put(ylpeysJaEnnakkoluulo.getNimi(), ylpeysJaEnnakkoluulo);
Hakemistosta voi hakea kirjoja kirjan nimellä. Haku kirjalla "Viisasteleva sydän" ei tuota osumaa, jolloin hajautustaulu palauttaa null-viitteen. Kirja "Ylpeys ja ennakkoluulo" kuitenkin löytyy.
Kirja kirja = hakemisto.get("Viisasteleva sydän");
System.out.println(kirja);
System.out.println();
kirja = hakemisto.get("Ylpeys ja ennakkoluulo");
System.out.println(kirja);
null Nimi: Ylpeys ja ennakkoluulo (1813) Sisältö: ...
Hajautustauluun lisättäessä avain-arvo -parin arvo voi olla käytännössä mitä tahansa. Arvo voi olla kokonaisluku, lista, tai vaikkapa toinen hajautustaulu.
Hajautustaulu oliomuuttujana
Edellä kuvatun esimerkin ongelma on se, että kirjan kirjoitusmuoto tulee muistaa täsmälleen oikein. Joku saattaa etsiä kirjaa pienellä alkukirjaimella ja joku toinen saattaa vaikkapa painaa välilyöntiä nimen kirjoituksen aluksi. Tarkastellaan seuraavaksi erästä tapaa hieman sallivampaan kirjan nimen perusteella tapahtuvaan hakemiseen.
Hyödynnämme hakemisessa String-luokan tarjoamia välineitä merkkijonojen käsittelyyn. Metodi toLowerCase() luo merkkijonosta uuden merkkijonon, jonka kaikki kirjaimet on muunnettu pieniksi. Metodi trim() taas luo merkkijonosta uuden merkkijonon, jonka alusta ja lopusta on poistettu tyhjät merkit kuten välilyönnit.
String teksti = "Ylpeys ja ennakkoluulo ";
teksti = teksti.toLowerCase(); // teksti nyt "ylpeys ja ennakkoluulo "
teksti = teksti.trim() // teksti nyt "ylpeys ja ennakkoluulo"
Jos mietit "kuka kirjoittaisi välilyöntejä ja miksi?", etsi ja lue kirja Ender's Game (suom. Ender).
Luodaan luokka Kirjasto, joka kapseloi kirjat sisältävän hajautustaulun ja mahdollistaa kirjoitusasusta riippumattoman kirjojen haun. Lisätään luokalle Kirjasto metodit lisäämiseen, hakemiseen ja poistamiseen. Jokainen näistä tapahtuu siistityn nimen perusteella -- siistiminen sisältää nimen muuntamisen pienellä kirjoitetuksi sekä ylimääräisten alussa ja lopussa olevien välilyöntien poistamisen.
Huomaamme jo nyt että merkkijonon siistimiseen liittyvää koodia tarvitsisi jokaisessa kirjaa käsittelevässä metodissa, joten siitä on hyvä tehdä erillinen metodi.
public class Kirjasto {
private HashMap<String, Kirja> hakemisto;
public Kirjasto() {
this.hakemisto = new HashMap<>();
}
public void lisaaKirja(Kirja kirja) {
String nimi = siistiMerkkijono(kirja.getNimi());
if (this.hakemisto.containsKey(nimi)) {
System.out.println("Kirja on jo kirjastossa!");
} else {
hakemisto.put(nimi, kirja);
}
}
public Kirja haeKirja(String kirjanNimi) {
kirjanNimi = siistiMerkkijono(kirjanNimi);
return this.hakemisto.get(kirjanNimi);
}
public void poistaKirja(String kirjanNimi) {
kirjanNimi = siistiMerkkijono(kirjanNimi);
if (this.hakemisto.containsKey(kirjanNimi)) {
this.hakemisto.remove(kirjanNimi);
} else {
System.out.println("Kirjaa ei löydy, ei voida poistaa!");
}
}
public String siistiMerkkijono(String merkkijono) {
if (merkkijono == null) {
return "";
}
merkkijono = merkkijono.toLowerCase();
return merkkijono.trim();
}
}
Yllä käytetään hajautustaulun tarjoamaa metodia containsKey avaimen olemassaolon tarkastamiseen. Metodi palauttaa arvon true, jos hajautustauluun on lisätty haetulla avaimella mikä tahansa arvo, muulloin metodi palauttaa arvon false.
Edeltävässä esimerkissä noudatimme ns. DRY-periaatetta (Don't Repeat Yourself), jonka tarkoituksena on saman koodin toistumisen välttäminen. Merkkijonon siistiminen eli pienellä kirjoitetuksi muuttaminen sekä trimmaus, eli tyhjien merkkien poisto alusta ja lopusta, olisi toistunut useasti kirjastoluokassamme ilman metodia siistiMerkkijono. Toistuvaa koodia ei usein huomaa ennen kuin sitä on jo kirjoittanut, jolloin sitä päätyy koodiin lähes pakosti. Tässä ei ole mitään pahaa -- tärkeintä on että koodia siistitään sitä mukaa siistimistä vaativia tilanteita huomataan.
Hajautustaulun arvojen läpikäynti
Hajautustaulun avain-arvo -parien läpikäynti onnistuu metodin entrySet() avulla. Metodi entrySet() palauttaa hajautustaulussa olevat avain-arvo -parit tietokokoelmana, jonka voi käsitellä virtana. Yksittäinen arvo sisältää metodit getKey(), jolla saa avain-arvo -parin avaimen, ja getValue(), jolla saa avain-arvo -parin arvon.
Tarkastellaan tätä kirjastoesimerkin kautta.
Haluamme joskus etsiä kirjaa nimen osan perusteella. Hajautustaulun metodi get ei tähän sovellu, sillä sitä käytetään tietyllä avaimella etsimiseen. Kirjan nimen osan perusteella etsiminen onnistuu entrySet-metodin palauttamasta joukosta.
Alla olevassa esimerkissä haetaan kaikki ne kirjat, joiden nimessä esiintyy annettu merkkijono.
public ArrayList<Kirja> haeKirjaNimenOsalla(String nimenOsa) {
nimenOsa = siistiMerkkijono(nimenOsa);
// haetaan kaikki ne kirjan nimet, joissa esiintyy nimen osa,
// ja noudetaan niihin liittyvät kirjat
ArrayList<Kirja> kirjat = this.hakemisto.entrySet()
.stream()
.filter(entry -> entry.getKey().contains(nimenOsa))
.map(entry -> entry.getValue())
.collect(Collectors.toCollection(ArrayList::new));
}
Tällä tavalla etsiessä menetämme kuitenkin hajautustauluun liittyvän nopeusedun. Hajautustaulu on toteutettu siten, että yksittäisen avaimen perusteella hakeminen erittäin nopeaa. Yllä olevassa esimerkissä käydään kaikkien kirjojen nimet läpi, kun tietyllä avaimella etsittäessä tarkasteltaisiin tasan yhden kirjan olemassaoloa.
Alkeistyyppiset muuttujat hajautustaulussa
Hajautustaulu olettaa, että siihen lisätään viittaustyyppisiä muuttujia (samoin kuin ArrayList). Java muuntaa alkeistyyppiset muuttujat viittaustyyppisiksi käytännössä kaikkia Javan valmiita tietorakenteita (kuten ArrayList ja HashMap) käytettäessä. Vaikka luku 1 voidaan esittää alkeistyyppisen muuttujan int arvona, tulee sen tyypiksi määritellä Integer ArrayListissä ja HashMapissa.
HashMap<Integer, String> taulu = new HashMap<>(); // toimii
taulu.put(1, "Ole!");
HashMap<int, String> taulu2 = new HashMap<>(); // ei toimi
Hajautustaulun avain ja tallennettava olio ovat aina viittaustyyppisiä muuttujia. Jos haluat käyttää alkeistyyppisiä muuttujia avaimena tai tallennettavana arvona, on niille olemassa viittaustyyppiset vastineet. Alla on esitelty muutama.
| Alkeistyyppi | Viittaustyyppinen vastine |
|---|---|
| int | Integer |
| double | Double |
| char | Character |
Java muuntaa alkeistyyppiset muuttujat automaattisesti viittaustyyppisiksi kun niitä lisätään HashMapiin tai ArrayListiin. Tätä automaattista muunnosta viittaustyyppisiksi kutsutaan Javassa auto-boxingiksi, eli automaattiseksi "laatikkoon" asettamiseksi. Automaattinen muunnos onnistuu myös toiseen suuntaan.
int avain = 2;
HashMap<Integer, Integer> taulu = new HashMap<>();
taulu.put(avain, 10);
int arvo = taulu.get(avain);
System.out.println(arvo);
10
Seuraava esimerkki kuvaa rekisterinumeroiden bongausten laskemiseen käytettävää luokkaa. Metodeissa metodeissa lisaaBongaus ja montakoKertaaBongattu tapahtuu automaattinen tyyppimuunnos.
public class Rekisteribongauslaskuri {
private HashMap<String, Integer> bongatut;
public Rekisteribongauslaskuri() {
this.bongatut = new HashMap<>();
}
public void lisaaBongaus(String bongattu) {
if (!this.bongatut.containsKey(bongattu)) {
this.bongatut.put(bongattu, 0);
}
int montakobongausta = this.bongatut.get(bongattu);
montakobongausta++;
this.bongatut.put(bongattu, montakobongausta);
}
public int montakoKertaaBongattu(String bongattu) {
this.bongatut.get(bongattu);
}
}
Tyyppimuunnoksissa piilee kuitenkin vaara. Jos yritämme muuntaa null-viitettä -- eli esimerkiksi bongausta, jota ei ole HashMapissa -- kokonaisluvuksi, näemme virheen java.lang.reflect.InvocationTargetException. Kun teemme automaattista muunnosta, tulee varmistaa että muunnettava arvo ei ole null. Yllä olevassa ohjelmassa oleva montakoKertaaBongattu-metodi tulee korjata esimerkiksi seuraavasti.
public int montakoKertaaBongattu(String bongattu) {
return this.bongatut.getOrDefault(bongattu, 0);
}
HashMapin metodi getOrDefault hakee sille ensimmäisenä parametrina annettua avainta HashMapista. Jos avainta ei löydy, palauttaa se toisena parametrina annetun arvon. Metodin toiminta vastaa seuraavaa metodia.
public int montakoKertaaBongattu(String bongattu) {
if (this.bongatut.containsKey(bongattu) {
return this.bongatut.get(bongattu);
}
return 0;
}
Siistitään vielä lisaaBongaus-metodia hieman. Alkuperäisessä versiossa metodin alussa lisätään hajautustauluun bongausten lukumääräksi arvo 0, jos bongattua ei löydy. Tämän jälkeen bongausten määrä haetaan, sitä kasvatetaan yhdellä, ja vanha bongausten lukumäärä korvataan lisäämällä arvo uudestaan hajautustauluun. Osan tästäkin toiminnallisuudesta voi korvata metodilla getOrDefault.
public class Rekisteribongauslaskuri {
private HashMap<String, Integer> bongatut;
public Rekisteribongauslaskuri() {
this.bongatut = new HashMap<>();
}
public void lisaaBongaus(String bongattu) {
int montakobongausta = this.bongatut.getOrDefault(bongattu, 0);
montakobongausta++;
this.bongatut.put(bongattu, montakobongausta);
}
public int montakoKertaaBongattu(String bongattu) {
return this.bongatut.getOrDefault(bongattu, 0);
}
}
Luo luokka Velkakirja, jolla on seuraavat toiminnot:
- konstruktori
public Velkakirja()luo uuden velkakirjan - metodi
public void asetaLaina(String kenelle, double maara)tallettaa velkakirjaan merkinnän lainasta tietylle henkilölle. - metodi
public double paljonkoVelkaa(String kuka)palauttaa velan määrän annetun henkilön nimen perusteella. Jos henkilöä ei löydy, palautetaan 0.
Luokkaa käytetään seuraavalla tavalla:
Velkakirja matinVelkakirja = new Velkakirja();
matinVelkakirja.asetaLaina("Arto", 51.5);
matinVelkakirja.asetaLaina("Mikael", 30);
System.out.println(matinVelkakirja.paljonkoVelkaa("Arto"));
System.out.println(matinVelkakirja.paljonkoVelkaa("Joel"));
Yllä oleva esimerkki tulostaisi:
51.5 0.0
Ole tarkkana tilanteessa, jossa kysytään velattoman ihmisen velkaa.
Huom! Velkakirjan ei tarvitse huomioida vanhoja lainoja. Kun asetat uuden velan henkilölle jolla on vanha velka, vanha velka unohtuu.
Velkakirja matinVelkakirja = new Velkakirja();
matinVelkakirja.asetaLaina("Arto", 51.5);
matinVelkakirja.asetaLaina("Arto", 10.5);
System.out.println(matinVelkakirja.paljonkoVelkaa("Arto"));
10.5
Ohjelmien rakenteesta
Kuudennen osan lopuksi muutama sana lähdekoodin kommentoinnista sekä ymmärrettävyydestä.
Lähdekoodin kommentointi
Lähdekoodiin voidaan lisätä kommentteja joko yhdelle riville kahden vinoviivan jälkeen // kommentti tai useammalle riville vinoviivan ja tähden sekä tähden ja vinoviivan rajaamalle alueelle /* kommentti */.
/*
Tulostaa luvut kymmenestä yhteen. Jokainen
luku tulostetaan omalle rivilleen.
*/
int luku = 10;
while (luku > 0) {
System.out.println(luku);
luku--; // sama kuin luku = luku - 1;
}
Kommenteilla on useita käyttötarkoituksia. Ohjelmointikurssilla ohjelmointia opettelevan kannattaa käyttää kommentteja ohjelman toiminnallisuuden itselleen selittämiseen. Kun yllä oleva lähdekoodi on selitetty kommenteissa rivi riviltä auki, näyttää se esimerkiksi seuraavalta.
/*
Tulostaa luvut kymmenestä yhteen. Jokainen
luku tulostetaan omalle rivilleen.
*/
// Luodaan kokonaislukutyyppinen muuttuja nimeltä
// luku, johon asetetaan arvo 10.
int luku = 10;
// Toistolauseen lohkon suoritusta jatketaan kunnes
// muuttujan luku arvo on nolla tai pienempi kuin nolla.
// Suoritus ei lopu _heti_ kun muuttujaan luku asetetaan
// arvo nolla, vaan vasta kun toistolauseen ehtolauseke
// evaluoidaan seuraavan kerran. Tämä tapahtuu aina lohkon
// suorituksen jälkeen.
while (luku > 0) {
// tulostetaan muuttujassa luku oleva arvo sekä rivinvaihto
System.out.println(luku);
// vähennetään yksi luku-muuttujan arvosta
luku--; // sama kuin luku = luku - 1;
}
Kommentit eivät vaikuta ohjelman suoritukseen, eli ohjelma toimii kommenttien kanssa täysin samalla tavalla kuin ilman kommentteja.
Edellä käytetty ohjelmoinnin opetteluun tarkoitettu kommentointityyli on kuitenkin ohjelmistokehitykseen kelpaamaton. Ohjelmistoja rakennettaessa lähdekoodin tulee kommentoida itse itsensä. Tällöin ohjelman toiminnallisuus tulee ilmi luokkien, metodien ja muuttujien nimistä.
Edelliset esimerkit voidaan yhtä hyvin kommentoida kapseloimalla ohjelmakoodi sopivasti nimettyn metodin sisään. Alla on kaksi esimerkkiä yllä olevan koodin kapseloivista metodeista -- toinen metodeista on hieman yleiskäyttöisempi kuin toinen. Toisaalta, jälkimmäisessä metodissa oletetaan, että käyttäjä tietää kumpaan parametreista asetetaan isompi ja kumpaan pienempi luku.
public void tulostaLuvutKymmenestaYhteen() {
int luku = 10;
while (luku > 0) {
System.out.println(luku);
luku--;
}
}
public void tulostaLuvutIsoimmastaPienimpaan(int mista, int mihin) {
while (mista >= mihin) {
System.out.println(mista);
mista--;
}
}
Kommenteista ja ymmärrettävyydestä
Alla on hieman kryptisempi ohjelma.
Tutustu ohjelmaan ja yritä selvittää mitä ohjelma tekee ennen materiaalissa etenemistä. Alla olevan ohjelman suorituksen selvittämisessä kannattaa käyttää esimerkiksi kynää ja paperia. Kun käytössäsi on kynä ja paperi, aloita ohjelmakoodin läpi käyminen rivi riviltä kuin olisit tietokone. Kirjaa jokaisen rivin jälkeen ylös ohjelman käyttämissä muuttujissa tapahtuneet muutokset.
ArrayList<Integer> l = new ArrayList<>();
l.add(12);
l.add(14);
l.add(18);
l.add(40);
l.add(41);
l.add(42);
l.add(47);
l.add(52);
l.add(59);
int x = 42;
int a = 0;
int b = l.size() - 1;
while (a <= b) {
int c = a + (b - a) / 2;
if (x < l.get(c)) {
b = c - 1;
} else if (x > l.get(c)) {
a = c + 1;
} else {
System.out.println(c);
}
}
System.out.println("-1");
Kun olet kokeillut ohjelman toiminnan seuraamista yllä olevalla ohjelmalla, toista harjoitus alla olevalla ohjelmalla. Alla olevassa ohjelmassa muuttujien nimet on muutettu kuvaavammiksi.
ArrayList<Integer> luvut = new ArrayList<>();
luvut.add(12);
luvut.add(14);
luvut.add(18);
luvut.add(40);
luvut.add(41);
luvut.add(42);
luvut.add(47);
luvut.add(52);
luvut.add(59);
int haettava = 42;
int alaraja = 0;
int ylaraja = luvut.size() - 1;
while (alaraja <= ylaraja) {
int keskikohta = alaraja + (ylaraja - alaraja) / 2;
if (haettava < luvut.get(keskikohta)) {
ylaraja = keskikohta - 1;
} else if (haettava > luvut.get(keskikohta)) {
alaraja = keskikohta + 1;
} else {
System.out.println(keskikohta);
}
}
System.out.println("-1");
Lähdekoodi, missä muuttujien nimet on selkeitä, on helpommin ymmärrettävää kuin lähdekoodi, missä muuttujien nimet eivät kuvaa niiden tarkoitusta. Haluamme ohjelmasta version, joka on nopeasti ymmärrettävissä. Luodaan siitä metodi ja nimetään metodi sopivasti.
public int binaariHaku(ArrayList<Integer> luvut, int haettava) {
int alaraja = 0;
int ylaraja = luvut.size() - 1;
while (alaraja <= ylaraja) {
int keskikohta = alaraja + (ylaraja - alaraja) / 2;
if (haettava < luvut.get(keskikohta)) {
ylaraja = keskikohta - 1;
} else if (haettava > luvut.get(keskikohta)) {
alaraja = keskikohta + 1;
} else {
return keskikohta;
}
}
return -1;
}
Lähdekoodi on nyt ymmärrettävissä suoraan metodin määrittelystä: public void binaariHaku(ArrayList<Integer> luvut, int haettava). Kyseessä on binäärihakualgoritmi, joka etsii listasta annettua lukua. Metodimäärittely ei kuitenkaan kerro binäärihakuun liittyvistä oletuksista tai sen palautusarvoista.
Korjataan tilanne kommentilla. Yllä esitetyn binäärihakualgoritmin toiminnan ehtona on se, että lista on järjestyksessä pienimmästä suurimpaan. Jos etsittävä luku löytyy, algoritmi palauttaa luvun indeksin. Jos lukua taas ei löydy, algoritmi palauttaa luvun -1.
Käytämme alla ohjelman dokumentointiin liittyvää kommentointitapaa, missä kommentti alkaa vinoviivalla ja kahdella tähdellä sekä päättyy yhteen tähteen ja vinoviivaan /** kommentti */. Ohjelmointiympäristöt näyttävät metodeihin liittyvät dokumenttikommentit muunmuassa lähdekoodin automaattisen täydennyksen yhteydessä.
/**
Binäärihaku etsii parametrina annetusta listasta parametrina annettua lukua.
Jos etsittävä luku löytyy, metodi palauttaa luvun indeksin listassa. Jos
etsittävää lukua ei löydy, metodi palauttaa arvon -1. Metodi olettaa, että
lista on järjestetty pienimmästä arvosta suurimpaan.
*/
public int binaariHaku(ArrayList<Integer> luvut, int haettava) {
int alaraja = 0;
int ylaraja = luvut.size() - 1;
while (alaraja <= ylaraja) {
int keskikohta = alaraja + (ylaraja - alaraja) / 2;
if (haettava < luvut.get(keskikohta)) {
ylaraja = keskikohta - 1;
} else if (haettava > luvut.get(keskikohta)) {
alaraja = keskikohta + 1;
} else {
return keskikohta;
}
}
return -1;
}
Alla olevassa kuvassa näytetään miten ohjelmointiympäristö näyttää metodiin liittyvän kommentin. Oletuksena on, että hakualgoritmi on luokassa Hakualgoritmit. Kun luokasta on tehty olio, ja ohjelmoija alkaa kirjoittamaan metodin nimeä, näyttää ohjelmointiympäristö metodiin aiemmin liitetyn dokumentaation. Kuvassa metodin parametrien määrittely poikkeaa hieman edellisestä esimerkistä.
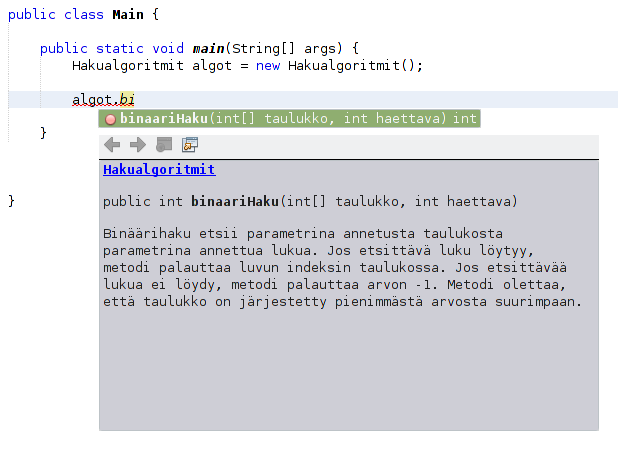
Kommentteja käytetään siis ensisijaisesti luokkien sekä metodien yleisen toiminnallisuuden kuvaamisessa sen sijaan, että kerrottaisiin yksityiskohtaisesti mitä ohjelma tekee. Yksityiskohtainen ohjelman toiminnan avaaminen on kuitenkin hyvä tapa selittää ohjelmakoodia itselleen. Yleisesti ottaen voidaan ajatella niin, että vaikeasti ymmärrettävät ohjelmat kannattaa pilkkoa luokkiin ja metodeihin, jotka kuvaavat ohjelman rakennetta. Dokumentointi ja kommentointi niiltä osin, mitkä eivät ole luokkien tai metodien nimistä selviä, on tärkeää -- esimerkiksi metodien paluuarvot sekä niiden toimintaan liittyvät oletukset on hyvä dokumentoida.
Sovellus ja sen osat
Edellä puhuimme kommenteista sekä ohjelman pilkkomisesta luokkiin ja metodeihin, jotka kuvaavat ohjelman rakennetta. Seuraava katkelma on Edsger W. Dijkstran artikkelista On the role of scientific thought.
Let me try to explain to you, what to my taste is characteristic for all intelligent thinking. It is, that one is willing to study in depth an aspect of one's subject matter in isolation for the sake of its own consistency, all the time knowing that one is occupying oneself only with one of the aspects. We know that a program must be correct and we can study it from that viewpoint only; we also know that it should be efficient and we can study its efficiency on another day, so to speak. In another mood we may ask ourselves whether, and if so: why, the program is desirable. But nothing is gained - on the contrary! - by tackling these various aspects simultaneously. It is what I sometimes have called "the separation of concerns", which, even if not perfectly possible, is yet the only available technique for effective ordering of one's thoughts, that I know of. This is what I mean by "focusing one's attention upon some aspect": it does not mean ignoring the other aspects, it is just doing justice to the fact that from this aspect's point of view, the other is irrelevant. It is being one- and multiple-track minded simultaneously.
Ohjelmoijan tulee pystyä tarkastelemaan ohjelmaansa eri näkökulmista ilman, että muut ohjelman osa-alueet vievät keskittymistä. Käyttöliittymään tulee voida keskittyä ilman, että ohjelmoijan tulee keskittyä sovelluksen ydinlogiikkaan. Vastaavasti ohjelmassa ja ongelma-alueessa esiintyviin käsitteisiin tulee voida keskittyä ilman, että ohjelmoijan tarvitsee välittää käyttöliittymästä. Vastaavasti ohjelmassa käytettävien algoritmien tehokkuus on oma "huolenaihe", johon ohjelmoijan tulee voida keskittyä ilman huolta muista osa-alueista.
Samaa ajatusta voidaan jatkaa vastuiden näkökulmasta. Robert "Uncle Bob" C. Martin kuvaa blogissaan termiä "single responsibility principle" seuraavasti.
When you write a software module, you want to make sure that when changes are requested, those changes can only originate from a single person, or rather, a single tightly coupled group of people representing a single narrowly defined business function. You want to isolate your modules from the complexities of the organization as a whole, and design your systems such that each module is responsible (responds to) the needs of just that one business function.
[..in other words..] Gather together the things that change for the same reasons. Separate those things that change for different reasons.
Selkeys saadaan aikaan sopivalla luokkarakenteella sekä nimeämiskäytänteiden seuraamisella. Jokaisella luokalla tulee olla vastuu, johon liittyviä tehtäviä luokka hoitaa. Metodeja käytetään toiston vähentämiseen ja luokkien sisäisten toimintojen jäsentämiseen. Myös metodeilla tulee olla selkeä vastuu eli metodien ei tule olla liian pitkiä ja liian montaa asiaa tekeviä. Liian montaa asiaa tekevät monimutkaiset metodit tuleekin pilkkoa useiksi pienemmiksi apumetodeiksi joita alkuperäinen metodi kutsuu.
Ohjelmistoja kehittäessä keskitytään tyypillisesti niihin ohjelmiston ominaisuuksiin, jotka tuovat eniten arvoa ohjelmiston käyttäjälle. Nämä ominaisuudet sovitaan yhdessä ohjelmiston kehittäjän sekä loppukäyttäjän kanssa, mikä mahdollistaa ominaisuuksien järjestämisen tärkeysjärjestykseen.
Ohjelmistoille on tyypillistä se, että ohjelmistoon liittyvät toiveet sekä ominaisuuksien tärkeysjärjestys muuttuu ohjelmiston elinkaaren aikana. Tämä johtaa siihen, että osia ohjelmistosta kirjoitetaan uudestaan, osia siirrellään paikasta toiseen ja osia poistetaan kokonaan.
Ohjelmoijan näkökulmasta tämä tarkoittaa ensisijaisesti sitä, että ohjelmisto kehittyy jatkuvasti. Uudelleenkirjoitettavat osat tulevat tyypillisesti paremmiksi, sillä ohjelmoija oppii ongelma-alueesta siihen liittyviä ratkaisuja kehittäessään. Samalla tämä tarkoittaa sitä, että ohjelmoijan tulee myös säilyttää kokonaiskuva ohjelman rakenteesta, sillä joitain osia saatetaan myös uudelleenkäyttää muissa osissa ohjelmistoa.
Yleisesti ottaen voidaan todeta, että hyvin harva ohjelma kirjoitetaan vain kerran. Tätä ajatusta jatkaen on hyvä pyrkiä tilanteeseen, missä ohjelman käyttäjä pääsee kokeilemaan sitä mahdollisimman nopeasti -- tällöin muutostoiveiden kerääminen myös alkaa nopeasti. Ohjelmistoja tehdessä onkin hyvä usein luoda ensin Proof of Concept-sovellus, jolla voidaan kokeilla idean toimivuutta. Jos idea on hyvä, sitä jatkokehitetään -- samalla myös ohjelma ja kehittyy.
Ongelmasta kokonaisuuteen ja takaisin osiin
Tarkastellaan erään ohjelman rakennusprosessia sekä tutustutaan sovelluksen vastuualueiden erottamiseen toisistaan. Ohjelma kysyy käyttäjältä sanoja kunnes käyttäjä syöttää saman sanan uudestaan. Ohjelma käyttää listaa sanojen tallentamiseen.
Anna sana: porkkana Anna sana: selleri Anna sana: nauris Anna sana: lanttu Anna sana: selleri Annoit saman sanan uudestaan!
Rakennetaan ohjelma osissa. Eräs haasteista on se, että on vaikea päättää miten lähestyä tehtävää, eli miten ongelma tulisi jäsentää osaongelmiksi, ja mistä osaongelmasta kannattaisi aloittaa. Yhtä oikeaa vastausta ei ole -- joskus on hyvä lähteä pohtimaan ongelmaan liittyviä käsitteitä ja niiden yhteyksiä, joskus taas ohjelman tarjoamaa käyttöliittymää.
Käyttöliittymän hahmottelu voisi lähteä liikenteeseen luokasta Kayttoliittyma. Käyttöliittymä käyttää Scanner-oliota, jonka sille voi antaa. Tämän lisäksi käyttöliittymällä on käynnistämiseen tarkoitettu metodi.
public class Kayttoliittyma {
private Scanner lukija;
public Kayttoliittyma(Scanner lukija) {
this.lukija = lukija;
}
public void kaynnista() {
// tehdään jotain
}
}
Käyttöliittymän luominen ja käynnistäminen onnistuu seuraavasti.
public static void main(String[] args) {
Scanner lukija = new Scanner(System.in);
Kayttoliittyma kayttoliittyma = new Kayttoliittyma(lukija);
kayttoliittyma.kaynnista();
}
Toisto ja lopetus
Ohjelmassa on (ainakin) kaksi "aliongelmaa". Ensimmäinen on sanojen toistuva lukeminen käyttäjältä kunnes tietty ehto toteutuu. Tämä voitaisiin hahmotella seuraavaan tapaan.
public class Kayttoliittyma {
private Scanner lukija;
public Kayttoliittyma(Scanner lukija) {
this.lukija = lukija;
}
public void kaynnista() {
while (true) {
System.out.print("Anna sana: ");
String sana = lukija.nextLine();
if (pitää lopettaa) {
break;
}
}
System.out.println("Annoit saman sanan uudestaan!");
}
}
Sanojen kysely jatkuu kunnes käyttäjä syöttää jo aiemmin syötetyn sanan. Täydennetään ohjelmaa siten, että se tarkastaa onko sana jo syötetty. Vielä ei tiedetä miten toiminnallisuus kannattaisi tehdä, joten tehdään siitä vasta runko.
public class Kayttoliittyma {
private Scanner lukija;
public Kayttoliittyma(Scanner lukija) {
this.lukija = lukija;
}
public void kaynnista() {
while (true) {
System.out.print("Anna sana: ");
String sana = lukija.nextLine();
if (onJoSyotetty(sana)) {
break;
}
}
System.out.println("Annoit saman sanan uudestaan!");
}
public boolean onJoSyotetty(String sana) {
// tänne jotain
return false;
}
}
Ohjelmaa on hyvä testata koko ajan, joten tehdään metodista kokeiluversio:
public boolean onJoSyotetty(String sana) {
if (sana.equals("loppu")) {
return true;
}
return false;
}
Nyt toisto jatkuu niin kauan kunnes syötteenä on sana loppu:
Anna sana: porkkana Anna sana: selleri Anna sana: nauris Anna sana: lanttu Anna sana: loppu Annoit saman sanan uudestaan!
Ohjelma ei toimi vielä kokonaisuudessaan, mutta ensimmäinen osaongelma eli ohjelman pysäyttäminen kunnes tietty ehto toteutuu on saatu toimimaan.
Oleellisten tietojen tallentaminen
Toinen osaongelma on aiemmin syötettyjen sanojen muistaminen. Lista sopii mainiosti tähän tarkoitukseen.
public class Kayttoliittyma {
private Scanner lukija;
private ArrayList<String> aiemmatSanat;
public Kayttoliittyma(Scanner lukija) {
this.lukija = lukija;
this.aiemmatSanat = new ArrayList<String>();
}
//...
Kun uusi sana syötetään, on se lisättävä syötettyjen sanojen joukkoon. Tämä tapahtuu lisäämällä while-silmukkaan listan sisältöä päivittävä rivi:
while (true) {
System.out.print("Anna sana: ");
String sana = lukija.nextLine();
if (onJoSyotetty(sana)) {
break;
}
// lisätään uusi sana aiempien sanojen listaan
this.aiemmatSanat.add(sana);
}
Kayttoliittyma näyttää kokonaisuudessaan seuraavalta.
public class Kayttoliittyma {
private Scanner lukija;
private ArrayList<String> aiemmatSanat;
public Kayttoliittyma(Scanner lukija) {
this.lukija = lukija;
this.aiemmatSanat = new ArrayList<String>();
}
public void kaynnista() {
while (true) {
System.out.print("Anna sana: ");
String sana = lukija.nextLine();
if (onJoSyotetty(sana)) {
break;
}
// lisätään uusi sana aiempien sanojen listaan
this.aiemmatSanat.add(sana);
}
System.out.println("Annoit saman sanan uudestaan!");
}
public boolean onJoSyotetty(String sana) {
if (sana.equals("loppu")) {
return true;
}
return false;
}
}
Jälleen kannattaa testata, että ohjelma toimii edelleen. Voi olla hyödyksi esimerkiksi lisätä kaynnista-metodin loppuun testitulostus, joka varmistaa että syötetyt sanat todella menivät listaan.
// testitulostus joka varmistaa että kaikki toimii edelleen
this.aiemmatSanat.stream().forEach(s -> System.out.println(s));
Osaongelmien ratkaisujen yhdistäminen
Muokataan vielä äsken tekemämme metodi onJoSyotetty tutkimaan onko kysytty sana jo syötettyjen joukossa, eli listassa.
public boolean onJoSyotetty(String sana) {
return this.aiemmatSanat.contains(sana);
}
Nyt sovellus toimii kutakuinkin halutusti.
Oliot luonnollisena osana ongelmanratkaisua
Rakensimme äsken ratkaisun ongelmaan, missä luetaan käyttäjältä sanoja, kunnes käyttäjä antaa saman sanan uudestaan. Syöte ohjelmalle oli esimerkiksi seuraavanlainen.
Anna sana: porkkana Anna sana: selleri Anna sana: nauris Anna sana: lanttu Anna sana: selleri Annoit saman sanan uudestaan!
Päädyimme ratkaisuun
public class Kayttoliittyma {
private Scanner lukija;
private ArrayList<String> aiemmatSanat;
public Kayttoliittyma(Scanner lukija) {
this.lukija = lukija;
this.aiemmatSanat = new ArrayList<String>();
}
public void kaynnista() {
while (true) {
System.out.print("Anna sana: ");
String sana = lukija.nextLine();
if (onJoSyotetty(sana)) {
break;
}
// lisätään uusi sana aiempien sanojen listaan
aiemmatSanat.add(sana);
}
System.out.println("Annoit saman sanan uudestaan!");
}
public boolean onJoSyotetty(String sana) {
return this.aiemmatSanat.contains(sana);
}
}
Ohjelman käyttämä apumuuttuja lista aiemmatSanat on yksityiskohta käyttöliittymän kannalta. Käyttöliittymän kannaltahan on oleellista, että muistetaan niiden sanojen joukko jotka on nähty jo aiemmin. Sanojen joukko on selkeä erillinen "käsite", tai abstraktio. Tälläiset selkeät käsitteet ovat potentiaalisia olioita; kun koodissa huomataan "käsite" voi sen eristämistä erilliseksi luokaksi harkita.
Sanajoukko
Tehdään luokka Sanajoukko, jonka käyttöönoton jälkeen käyttöliittymän metodi kaynnista on seuraavanlainen:
while (true) {
String sana = lukija.nextLine();
if (aiemmatSanat.sisaltaa(sana)) {
break;
}
aiemmatSanat.lisaa(sana);
}
System.out.println("Annoit saman sanan uudestaan!");
Käyttöliittymän kannalta Sanajoukolla kannattaisi siis olla metodit boolean sisaltaa(String sana) jolla tarkastetaan sisältyykö annettu sana jo sanajoukkoon ja void lisaa(String sana) jolla annettu sana lisätään joukkoon.
Huomaamme, että näin kirjoitettuna käyttöliittymän luettavuus on huomattavasti parempi.
Luokan Sanajoukko runko näyttää seuraavanlaiselta:
public class Sanajoukko {
// oliomuuttuja(t)
public Sanajoukko() {
// konstruktori
}
public boolean sisaltaa(String sana) {
// sisältää-metodin toteutus
return false;
}
public void lisaa(String sana) {
// lisaa-metodin toteutus
}
}
Toteutus aiemmasta ratkaisusta
Voimme toteuttaa sanajoukon siirtämällä aiemman ratkaisumme listan sanajoukon oliomuuttujaksi:
import java.util.ArrayList;
public class Sanajoukko {
private ArrayList<String> sanat;
public Sanajoukko() {
this.sanat = new ArrayList<>();
}
public void lisaa(String sana) {
this.sanat.add(sana);
}
public boolean sisaltaa(String sana) {
return this.sanat.contains(sana);
}
}
Ratkaisu on nyt melko elegantti. Erillinen käsite on saatu erotettua ja käyttöliittymä näyttää siistiltä. Kaikki "likaiset yksityiskohdat" on saatu siivottua eli kapseloitua olion sisälle.
Muokataan käyttöliittymää niin, että se käyttää Sanajoukkoa. Sanajoukko annetaan käyttöliittymälle samalla tavalla parametrina kuin Scanner.
public class Kayttoliittyma {
private Scanner lukija;
private Sanajoukko sanajoukko;
public Kayttoliittyma(Scanner lukija, Sanajoukko sanajoukko) {
this.lukija = lukija;
this.sanajoukko = sanajoukko;
}
public void kaynnista() {
while (true) {
System.out.print("Anna sana: ");
String sana = lukija.nextLine();
if (this.sanajoukko.sisaltaa(sana)) {
break;
}
this.sanajoukko.lisaa(sana);
}
System.out.println("Annoit saman sanan uudestaan!");
}
}
Ohjelman käynnistäminen tapahtuu nyt seuraavasti:
public static void main(String[] args) {
Scanner lukija = new Scanner(System.in);
Sanajoukko joukko = new Sanajoukko();
Kayttoliittyma kayttoliittyma = new Kayttoliittyma(lukija, joukko);
kayttoliittyma.kaynnista();
}
Luokan sisäisen toteutuksen muuttaminen
Olemme päätyneet tilanteeseen missä Sanajoukko ainoastaan "kapseloi" ArrayList:in. Onko tässä järkeä? Kenties. Voimme nimittäin halutessamme tehdä Sanajoukolle muitakin muutoksia. Ennen pitkään saatamme esim. huomata, että sanajoukko pitää tallentaa tiedostoon. Jos tekisimme nämä muutokset Sanajoukkoon muuttamatta käyttöliittymän käyttävien metodien nimiä, ei käyttöliittymää tarvitsisi muuttaa mitenkään.
Oleellista on tässä se, että Sanajoukko-luokkaan tehdyt sisäiset muutokset eivät vaikuta luokkaan Käyttöliittymä. Tämä johtuu siitä, että käyttöliittymä käyttää sanajoukkoa sen tarjoamien metodien -- eli julkisten rajapintojen -- kautta.
Uusien toiminnallisuuksien toteuttaminen: palindromit
Voi olla, että jatkossa ohjelmaa halutaan laajentaa siten, että Sanajoukko-luokan olisi osattava uusia asiota. Jos ohjelmassa haluttaisiin esimerkiksi tietää kuinka moni syötetyistä sanoista oli palindromi, voidaan sanajoukkoa laajentaa metodilla palindromeja.
public void kaynnista() {
while (true) {
System.out.print("Anna sana: ");
String sana = lukija.nextLine();
if (this.sanajoukko.sisaltaa(sana)) {
break;
}
this.sanajoukko.lisaa(sana);
}
System.out.println("Annoit saman sanan uudestaan!");
System.out.println("Sanoistasi " + this.sanajoukko.palindromeja() + " oli palindromeja");
}
Käyttöliittymä säilyy siistinä ja palindromien laskeminen jää Sanajoukko-olion huoleksi. Metodin toteutus voisi olla esimerkiksi seuraavanlainen.
import java.util.ArrayList;
public class Sanajoukko {
private ArrayList<String> sanat;
public Sanajoukko() {
this.sanat = new ArrayList<>();
}
public boolean sisaltaa(String sana) {
return this.sanat.contains(sana);
}
public void lisaa(String sana) {
this.sanat.add(sana);
}
public int palindromeja() {
return (int) this.sanat.stream().filter(s -> onPalindromi(s)).count();
}
public boolean onPalindromi(String sana) {
int loppu = sana.length() - 1;
int i = 0;
while (i < sana.length() / 2) {
// metodi charAt palauttaa annetussa indeksissä olevan merkin
if(sana.charAt(i) != sana.charAt(loppu - i)) {
return false;
}
i++;
}
return true;
}
}
Metodissa palindromeja käytetään sekä apumetodia onPalindromi että virran filter-metodia. Virran count-metodi palauttaa long-tyyppisen kokonaisluvun, joka tulee muuntaa int-tyyppiseksi ennen sen palautusta metodista.
Uusiokäyttö
Kun ohjelmakoodin käsitteet on eriytetty omiksi luokikseen, voi niitä uusiokäyttää helposti muissa projekteissa. Esimerkiksi luokkaa Sanajoukko voisi käyttää yhtä hyvin graafisesta käyttöliittymästä, ja se voisi myös olla osa kännykässä olevaa sovellusta. Tämän lisäksi ohjelman toiminnan testaaminen on huomattavasti helpompaa silloin kun ohjelma on jaettu erillisiin käsitteisiin, joita kutakin voi käyttää myös omana itsenäisenä yksikkönään.
Neuvoja ohjelmointiin
Yllä kuvatussa laajemmassa esimerkissä noudatettiin seuraavia neuvoja.
- Etene pieni askel kerrallaan
- Yritä pilkkoa ongelma osaongelmiin ja ratkaise vain yksi osaongelma kerrallaan
- Testaa aina että ohjelma on etenemässä oikeaan suuntaan eli että osaongelman ratkaisu meni oikein
- Tunnista ehdot, minkä tapauksessa ohjelman tulee toimia eri tavalla. Esimerkiksi yllä tarkistus, jolla katsotaan onko sana jo syötetty, johtaa erilaiseen toiminnallisuuden.
- Kirjoita mahdollisimman "siistiä" koodia
- sisennä koodi
- käytä kuvaavia muuttujien ja metodien nimiä
- älä tee liian pitkiä metodeja, edes mainia
- tee yhdessä metodissa vaan yksi asia
- poista koodistasi kaikki copy-paste
- korvaa koodisi "huonot" ja epäsiistit osat siistillä koodilla
- Astu tarvittaessa askel taaksepäin ja mieti kokonaisuutta. Jos ohjelma ei toimi, voi olla hyvä idea palata aiemmin toimineeseen tilaan. Käänteisesti voidaan sanoa, että rikkinäinen ohjelma korjaantuu harvemmin lisäämällä siihen lisää koodia.
Ohjelmoijat noudattavat näitä käytänteitä sen takia että ohjelmointi olisi helpompaa. Käytänteiden noudattaminen tekee myös ohjelmien lukemisesta, ylläpitämisestä ja muokkaamisesta helpompaa muille.
Tässä tehtäväsarjassa toteutetaan sanakirja, josta voi hakea suomen kielen sanoille englanninkielisiä käännöksiä. Sanakirjan tekemisessä käytetään HashMap-tietorakennetta.
Luokka Sanakirja
Toteuta luokka nimeltä Sanakirja. Luokalla on aluksi seuraavat metodit:
-
public String kaanna(String sana)metodi palauttaa parametrinsa käännöksen. Jos sanaa ei tunneta, palautetaan null. -
public void lisaa(String sana, String kaannos)metodi lisää sanakirjaan uuden käännöksen
Toteuta luokka Sanakirja siten, että sen ainoa oliomuuttuja on HashMap-tietorakenne.
Testaa sanakirjasi toimintaa:
Sanakirja sanakirja = new Sanakirja();
sanakirja.lisaa("apina", "monkey");
sanakirja.lisaa("banaani", "banana");
sanakirja.lisaa("cembalo", "harpsichord");
System.out.println(sanakirja.kaanna("apina"));
System.out.println(sanakirja.kaanna("porkkana"));
monkey null
Sanojen lukumäärä
Lisää sanakirjaan metodi public int sanojenLukumaara(), joka palauttaa sanakirjassa olevien sanojen lukumäärän.
Sanakirja sanakirja = new Sanakirja();
sanakirja.lisaa("apina", "monkey");
sanakirja.lisaa("banaani", "banana");
System.out.println(sanakirja.sanojenLukumaara());
sanakirja.lisaa("cembalo", "harpsichord");
System.out.println(sanakirja.sanojenLukumaara());
2 3
Tässä osassa kannattaa tutkiskella HashMapin valmiiksi tarjoamia metodeja... Vaihtoehtoisesti long-tyyppisen muuttujan saa muunnettua int-tyyppiseksi seuraavalla tavalla.
long lukuLongina = 1L;
int lukuInttina = (int) lukuLongina;
Kaikkien sanojen listaaminen
Lisää sanakirjaan metodi public ArrayList<String> kaannoksetListana() joka palauttaa sanakirjan sisällön listana avain = arvo muotoisia merkkijonoja.
Sanakirja sanakirja = new Sanakirja();
sanakirja.lisaa("apina", "monkey");
sanakirja.lisaa("banaani", "banana");
sanakirja.lisaa("cembalo", "harpsichord");
ArrayList<String> kaannokset = sanakirja.kaannoksetListana();
kaannokset.stream().forEach(k -> System.out.println(k));
banaani = banana apina = monkey cembalo = harpsichord
Tekstikäyttöliittymän alku
Harjoitellaan erillisen tekstikäyttöliittymän tekemistä. Luo luokka Tekstikayttoliittyma, jolla on seuraavat metodit:
- konstruktori
public Tekstikayttoliittyma(Scanner lukija, Sanakirja sanakirja) - metodi
public void kaynnista(), joka käynnistää tekstikäyttöliittymän.
Tekstikäyttöliittymä tallettaa konstruktorin parametrina saamansa lukijan ja sanakirjan oliomuuttujiin. Muita oliomuuttujia ei tarvita. Käyttäjän syötteen lukeminen tulee hoitaa konstruktorin parametrina saatua lukija-olioa käyttäen! Myös kaikki käännökset on talletettava konstruktorin parametrina saatuun sanakirja-olioon. Tekstikäyttöliittymä ei saa luoda Scanneria tai Sanakirjaa itse!
HUOM: vielä uudelleen edellinen, eli Tekstikäyttöliittymä ei saa luoda itse skanneria vaan sen on käytettävä parametrina saamaansa skanneria syötteiden lukemiseen!
Tekstikäyttöliittymässä tulee aluksi olla vain komento lopeta, joka poistuu tekstikäyttöliittymästä. Jos käyttäjä syöttää jotain muuta, käyttäjälle sanotaan "Tuntematon komento".
Scanner lukija = new Scanner(System.in);
Sanakirja sanakirja = new Sanakirja();
Tekstikayttoliittyma kayttoliittyma = new Tekstikayttoliittyma(lukija, sanakirja);
kayttoliittyma.kaynnista();
Komennot: lopeta - poistuu käyttöliittymästä Komento: apua Tuntematon komento. Komento: lopeta Hei hei!
Sanojen lisääminen ja kääntäminen
Lisää tekstikäyttöliittymälle komennot lisaa ja kaanna. Komento lisaa lisää kysyy käyttäjältä sanaparin ja lisää sen sanakirjaan. Komento kaanna kysyy käyttäjältä sanaa ja tulostaa sen käännöksen.
Scanner lukija = new Scanner(System.in);
Sanakirja sanakirja = new Sanakirja();
Tekstikayttoliittyma kayttoliittyma = new Tekstikayttoliittyma(lukija, sanakirja);
kayttoliittyma.kaynnista();
Komennot: lisaa - lisää sanaparin sanakirjaan kaanna - kysyy sanan ja tulostaa sen käännöksen lopeta - poistuu käyttöliittymästä Komento: lisaa Suomeksi: porkkana Käännös: carrot Komento: kaanna Anna sana: porkkana Käännös: carrot Komento: lopeta Hei hei!