Tuntee käsitteet URI, DNS, HTTP ja HTML. Osaa kertoa HTTP-protokollan tasolla palvelimelle lähetettävän GET ja POST-tyyppisen pyynnön rakenteen ja sisällön. Osaa kertoa HTTP-protokollan tasolla palvelimelta palautuvan vastauksen rakenteen. Tuntee menetelmiä tietokantojen ohjelmalliseen käsittelyyn. Tuntee käsitteen ORM ja osaa hyödyntää Javan ja Spring Bootin tietokanta-abstraktiota tiedon käsittelyyn. Käsittelee useampia tietokantatauluja sisältäviä sovelluksia ja tietää miten viitteet tietokantataulujen välillä määritellään. Osaa käsitellä transaktioita ohjelmallisesti. Tuntee N+1 kyselyn ongelman.
Internetin perusosat
Internetin peruskomponentit ovat (1) palveluiden, palvelinohjelmistojen ja resurssien yksilöintiin käytetyt merkkijonomuotoiset osoitteet (URI, Uniform Resource Identifier) sekä näiden merkkijonomuotoisten verkko-osoitteiksi käytettävä palvelu (DNS, Domain Name Services), (2) selainten ja palvelinten välisessä viestittelyssä käytettävä viestimuoto (protokolla) (HTTP, HyperText Transfer Protocol), sekä (3) yhteinen dokumenttien esityskieli (HTML, HyperText Markup Language).
URI ja DNS: Osoitteet ja niiden tulkinta
Verkossa sijaitseva resurssi tunnistetaan osoitteen perusteella. Osoite (URI eli Uniform Resource Identifier, myös terminä käyttöön jäänyt URL Uniform Resource Locator) koostuu resurssin nimestä ja sijainnista, joiden perusteella haluttu resurssi ja palvelin (sijainti) voidaan löytää verkossa olevien koneiden massasta.
Käytännössä URI-osoitteet näyttävät seuraavilta:
protokolla://isäntäkone[:portti]/polku/../[kohdedokumentti[.paate]][?parametri=arvo&toinen=arvo][#ankkuri]
- protokolla: kyselyssä käytettävä protokolla, esimerkiksi HTTP, FTP tai SSH.
- isäntäkone: kone tai palvelin johon luodaan yhteys. Voi olla joko IP-osoite tai tekstuaalinen kuvaus (esim www.cs.helsinki.fi).
- portti: portti isäntäkoneella johon yhteys luodaan. Selaimet olettavat, että palvelinohjelmisto kuuntelee pyyntöjä portissa 80. Web-sovellluksilla HTTP-palvelimien oletusportti on 80. Jos palvelin käyttää eri porttinumeroa kuin 80, tulee se merkitä osoitteeseen. Portti käytännössä määrittelee prosessin eli sovelluksen, johon yritetään ottaa yhteyttä.
- polku: periaatteessa polku resurssiin palvelimella. Käytännössä (nykyään) myös palvelun osoite, johon palvelin osaa osoittaa. Usein palvelut toimivat erillisessä koneessa sisäverkossa, ja ulkoverkkoon näkyvä kone vain toimii ohjaajana eli proxynä oikeaan palveluun.
- kohdedokumentti: haettava resurssi, jos kohdedokumenttia ei ole määritelty palvelin päättelee oletusdokumentin. Usein index.html
- .paate: resurssiin liittyvä tiedostotyyppi, ei pakollinen. Esimerkiksi .html
- kyselyparametrit: koostuu avain-arvo -pareista, joiden avulla palvelimelle pystyy toteuttamaan lisätoiminnallisuutta. Kuhunkin avaimeen liittyvä arvo esitetään = -merkillä, avain-arvo -parit erotetaan toisistaan &-merkillä.
- ankkuri: kertoo mihin kohtaan dokumentissa tulee mennä.
Tutki osoitetta https://fi.wikipedia.org/wiki/OSI-malli. Mitkä tai mikä ovat/on osoitteen:
- protokolla
- isäntäkone
- portti
- polku
- kohdedokumentti
- kyselyparametrit
- ankkuri
Mitkä näistä puuttuvat?
Kun käyttäjä kirjoittaa web-selaimen osoitekenttään osoitteen ja painaa enteriä, web-selain tekee kyselyn annettuun osoitteeseen. Koska tekstimuotoiset osoitteet ovat käytännössä vain ihmisiä varten, kääntää selain ensiksi halutun osoitteen IP-osoitteeksi. Jos IP-osoite on jo tietokoneen tiedossa esimerkiksi aiemmin osoitteeseen tehdyn kyselyjen takia, selain voi ottaa yhteyden IP-osoitteeseen. Jos IP-osoite taas ei ole tiedossa, tekee selain ensin kyselyn DNS-palvelimelle (Domain Name System), jonka tehtävänä on muuntaa tekstuaaliset osoitteet IP-osoitteiksi (esim. Tietojenkäsittelytieteen laitoksen kotisivu http://www.cs.helsinki.fi on IP-osoitteessa 128.214.166.78).
IP-osoitteet yksilöivät tietokoneet ja mahdollistavat koneiden löytämisen verkon yli. Käytännössä yhteys IP-osoitteen määrittelemään koneeseen avataan sovelluskerroksen HTTP-protokollan avulla kuljetuskerroksen TCP-protokollan yli. TCP-protokollan tehtävänä on varmistaa, että viestit pääsevät perille. Selain ei ota "suoraan" yhteyttä palvelinohjelmistoon, vaan välissä on tyypillisesti useita viestinvälityspalvelimia, jotka auttavat viestin perillepääsemisessä -- lisää tietoa konkreettisesta tietoliikenteestä löytyy kurssilla Tietoliikenteen perusteet.
HTTP: Selainten ja palvelinten välinen kommunikaatioprotokolla
HTTP (HyperText Transfer Protocol) on TCP/IP -protokollapinon sovellustason protokolla, jota web-palvelimet ja selaimet käyttävät kommunikointiin. HTTP-protokolla perustuu asiakas-palvelin malliin, jossa jokaista pyyntöä kohden on yksi vastaus (request-response paradigm). Tämä tarkoittaa sitä, että jokainen pyyntö käsitellään erillisenä kokonaisuutena, eikä saman käyttäjän kahta peräkkäistä pyyntöä yhdistetä automaattisesti toisiinsa.
Käytännössä HTTP-asiakasohjelma (jatkossa selain) lähettää HTTP-viestin HTTP-palvelimelle (jatkossa palvelin), joka palauttaa HTTP-vastauksen. Tällä hetkellä eniten käytetty HTTP-protokollan versio on 1.1, joka on määritelty RFC 2616-spesifikaatiossa.
Asiakas-palvelin malli
Asiakas-palvelin -mallissa (Client-Server model) asiakkaat käyttävät palvelimen tarjoamia palveluja. Kommunikointi asiakkaan ja palvelimen välillä tapahtuu usein verkon yli siten, että selain ja palvelin sijaitsevat erillisissä fyysisissä sijainneissa (eri tietokoneilla). Palvelin tarjoaa yhden tai useamman palvelun, joita käyttäjä käyttää selaimen kautta.
Käytännössä selain näyttää käyttöliittymän ohjelmiston käyttäjälle. Selaimen käyttäjän ei tarvitse tietää, että kaikki käytetty tieto ei ole hänen koneella. Käyttäjän tehdessä toiminnon selain pyytää tarpeen vaatiessa palvelimelta käyttäjän tarpeeseen liittyvää lisätietoa. Tyypillistä mallille on se, että palvelin tarjoaa vain asiakkaan pyytämät tiedot ja verkossa liikkuvan tiedon määrä pidetään vähäisenä.
Asiakas-palvelin -malli mahdollistaa hajautetut ohjelmistot: selainta käyttävät loppukäyttäjät voivat sijaita eri puolilla maapalloa palvelimen sijaitessa tietyssä paikassa.
Mene osoitteeseen https://en.wikipedia.org. Kirjoita sivuston oikeassa ylälaidassa olevaan kenttään "client server model" ja paina Enter-näppäintä. Mitkä seuraavista askeleista tapahtuivat selaimessa, mitkä palvelimella, mitkä muualla?
- Näppäimistön avulla kirjoittamasi osoitetekstin näyttäminen.
- Osoitetta https://en.wikipedia.org vastaavan IP-osoitteen etsiminen.
- Sivun https://en.wikipedia.org näyttäminen.
- https://en.wikipedia.org/wiki/Client–server_model -sivun näyttäminen
Tekstikentästä lähetetään viesti osoitteeseen https://en.wikipedia.org/w/index.php?search=client+server+model&title=Special%3ASearch&go=Go, mutta päädyt sivulle https://en.wikipedia.org/wiki/Client–server_model. Miksi näin tapahtuu?
Haasteena perinteisessä asiakas-palvelin mallissa on se, että palvelin sijaitsee yleensä tietyssä keskitetyssä sijainnissa. Keskitetyillä palveluilla on mahdollisuus ylikuormittua asiakasmäärän kasvaessa. Kapasiteettia rajoittavat muun muassa palvelimen fyysinen kapasiteetti (muisti, prosessorin teho, ..), palvelimeen yhteydessä olevan verkon laatu ja nopeus, sekä tarjotun palvelun tyyppi. Esimerkiksi pyynnöt, jotka johtavat tiedon tallentamiseen, vievät tyypillisesti enemmän resursseja kuin pyynnöt, jotka tarvitsevat vain staattista sisältöä.
Lähes kaikki sovellusten verkkoliikenne sovellustason protokollasta riippumatta käyttää TCP-yhteyksiä ja -portteja kommunikointiin. TCP-yhteyksiä käytetään Javassa Socket- ja ServerSocket-luokkien avulla. Lisää aiheesta löytyy tästä oppaasta.
Eräs suosittu viestiprotokolla (eli säännöstö, joka kertoo kuinka kommunikoinnin tulee kulkea) alkaa sanoilla Knock knock!. Toinen osapuoli vastaa tähän Who's there?. Ensimmäinen osapuoli vastaa jotain, esim. Moustache, jonka jälkeen toisen osapuolen tulee vastata Moustache who?. Tähän ensimmäinen osapuoli vastaa viestillä joka päättyy "Bye.".
Server: Knock knock! Client: Who's there? Server: Moustache Client: Moustache who? Server: I Moustache you a question, but I'm shaving it for later! Bye.
Tehtäväpohjan mukana tulee projekti, on toteutettu valmiiksi palvelinpuolen toiminnallisuus luokassa KnockKnockServer. Palvelinohjelmisto kuuntelee pyyntöä portissa 12345.
Tehtävänäsi on toteuttaa valmiiksi toteutettua palvelinkomponenttia varten asiakaspuolen toiminnallisuus, eli sovellus, joka tekee kyselyjä palvelimelle. Asiakaspuolen toiminnallisuutta varten on jo olemassa allaoleva runko, joka tulee tehtäväpohjan pakkauksessa wad.knockknock.client olevassa luokassa KnockKnockClient.
Täydennä asiakasohjelmisto annettujen askelten mukaan siten, että sitä voi käyttää kommunikointiin viestiprotokollapalvelimen kanssa.
// Luodaan yhteys palvelimelle
Socket socket = new Socket("localhost", port);
Scanner serverMessageScanner = new Scanner(socket.getInputStream());
PrintWriter clientMessageWriter = new PrintWriter(
socket.getOutputStream(), true);
Scanner userInputScanner = new Scanner(System.in);
// Luetaan viestejä palvelimelta
while (serverMessageScanner.hasNextLine()) {
// 1. lue viesti palvelimelta
// 2. tulosta palvelimen viesti standarditulostusvirtaan näkyville
// 3. jos palvelimen viesti loppuu merkkijonon "Bye.", poistu toistolausekkeesta
// 4. pyydä käyttäjältä palvelimelle lähetettävää viestiä
// 5. kirjoita lähetettävä viesti palvelimelle. Huom! Käytä println-metodia.
}
Kirjoita asiakasohjelmiston lähdekoodi KnockKnockClient-luokan start-metodiin. Kun olet saanut ohjelmiston valmiiksi, suorita ohjelma, jotta voit kokeilla sitä. Tehtäväpohjan mukana on ohjelman käynnistävä main-metodin sisältävä luokka valmiina. Tulostuksen pitäisi olla esimerkiksi seuraavanlainen (käyttäjän syöttämät tekstit on merkitty punaisella):
Server: Knock knock! Type a message to be sent to the server: Who's there? Server: Lettuce Type a message to be sent to the server: Lettuce who? Server: Lettuce in! it's cold out here! Bye.
Jos asiakasohjelmisto lähettää virheellisiä viestejä, reagoi palvelin siihen seuraavasti:
Server: Knock knock! Type a message to be sent to the server: What? Server: You are supposed to ask: "Who's there?" Type a message to be sent to the server: Who's there? Server: Lettuce Type a message to be sent to the server: huh Server: You are supposed to ask: "Lettuce who?" Type a message to be sent to the server: Lettuce who? Server: Lettuce in! it's cold out here! Bye.
Kun olet saanut asiakaspuolen toiminnallisuuden toimimaan, palauta tehtävä TMC:lle.
Edellisessä tehtävässä toteutettu ohjelma voisi aivan yhtä hyvin tehdä kyselyitä web-palvelimelle, mutta tällöin käytettynä viestiprotokollana pitäisi olla HTTP-protokolla. Tutustutaan seuraavaksi tarkemmin HTTP-protokollaan, eli selainten ja palvelinten väliseen kommunikaatioon käytettyyn kommunikaatiotyyliin.
HTTP-viestin rakenne: palvelimelle lähetettävä kysely
HTTP-protokollan yli lähetettävät viestit ovat tekstimuotoisia. Viestit koostuvat riveistä jotka muodostavat otsakkeen, sekä riveistä jotka muodostavat viestin rungon. Viestin runkoa ei ole pakko olla olemassa -- joskus palautetaan esimerkiksi vain uudelleenohjauskomento. Viestin loppuminen ilmoitetaan kahdella peräkkäisellä rivinvaihdolla.
Palvelimelle lähetettävän viestin, eli kyselyn, ensimmäisellä rivillä on pyyntötapa, halutun resurssin polku ja HTTP-protokollan versionumero.
PYYNTÖTAPA /POLKU_HALUTTUUN_RESURSSIIN HTTP/versio otsake-1: arvo otsake-2: arvo valinnainen viestin runko
Pyyntötapa ilmaisee HTTP-protokollassa käytettävän pyynnön tavan (esim. GET tai POST), polku haluttuun resurssiin kertoo haettavan resurssin sijainnin palvelimella (esim. /index.html), ja HTTP-versio kertoo käytettävän version (esim. HTTP/1.0). Alla esimerkki hyvin yksinkertaisesta -- joskin yleisestä -- pyynnöstä. Huomaa että yhteys palvelimeen on jo muodostettu, eli palvelimen osoitetta ei merkitä erikseen.
GET /index.html HTTP/1.0
Yksittäisen tietokoneen käyttäminen yhteen web-palvelinohjelmistoon saapuviin pyyntöihin jättää helposti huomattavan osan tietokoneen kapasiteetista käyttämättä. Yleisesti käytössä oleva HTTP/1.1 -protokolla mahdollistaa useamman palvelimen pitämisen samassa IP-osoitteessa virtuaalipalvelintekniikan avulla. Tällöin yksittäiset palvelinkoneet voivat sisältää useita palvelimia. Käytännössä IP-osoitetta kuunteleva kone voi joko itsessään sisältää useita ohjelmistoilla emuloituja palvelimia, tai se voi toimia reitittimenä ja ohjata pyynnön tietylle esimerkiksi yrityksen sisäverkossa sijaitsevalle koneelle.
Koska yksittäinen IP-osoite voi sisältää useampia palvelimia, pelkkä polku haluttuun resurssiin ei riitä oikean resurssin löytämiseen: resurssi voisi olla millä tahansa koneeseen liittyvällä virtuaalipalvelimella. HTTP/1.1 -protokollassa on pyynnöissä pakko olla mukana käytetyn palvelimen osoitteen kertova Host-otsake.
GET /index.html HTTP/1.1 Host: www.munpalvelin.net
Yhteyden muodostaminen palvelimelle Java-maailmassa
Java-maailmassa yhteys toiselle koneelle muodostetaan Socket-luokan avulla. Kun yhteys on muodostettu, toiselle koneelle lähetettävä viesti kirjoitetaan socketin tarjoamaan OutputStream-rajapintaan. Tämän jälkeen luetaan vastaus socketin tarjoaman InputStream-rajapinnan kautta.
import java.io.PrintWriter;
import java.net.InetAddress;
import java.net.Socket;
import java.util.Scanner;
public class Main {
public static void main(String[] args) throws Exception {
// Connect to the Web server at an address
String address = "www.helsinki.fi";
// InetAddress.getByName retrieves an IP for the address
Socket socket = new Socket(InetAddress.getByName(address), 80);
// Send a HTTP-request to the server that we are connected to
PrintWriter writer = new PrintWriter(socket.getOutputStream());
writer.println("GET / HTTP/1.1");
writer.println("Host: " + address);
writer.println();
writer.flush();
// Read the response
Scanner reader = new Scanner(socket.getInputStream());
while (reader.hasNextLine()) {
System.out.println(reader.nextLine());
}
}
}
Yllä oleva ohjelma ottaa yhteyden etsii www.helsinki.fi -osoitteeseen liittyvän palvelimen, ottaa yhteyden palvelimen porttiin 80, ja lähettää palvelimelle seuraavan viestin:
GET / HTTP/1.1 Host: www.helsinki.fi
Tämän jälkeen ohjelma tulostaa palvelimelta saatavan vastauksen.
Vaikkei kyseessä olekaan selainohjelmointikurssi, on jokaisen hyvä toteuttaa selainohjelmiston ensimmäiset askeleet. Toteuta tehtäväpohjassa olevan HelloBrowser-luokan main-metodiin ohjelma, joka kysyy käyttäjältä sivun osoitetta, tekee syötetyn sivun juureen ("/") pyynnön, ja tulostaa käyttäjälle vastauksen.
Alla on esimerkkituloste, missä käyttäjän syöte on annettu punaisella.
================ THE INTERNETS! ================ Where to? www.google.com ========== RESPONSE ========== HTTP/1.1 302 Found Cache-Control: private Content-Type: text/html; charset=UTF-8 Location: http://www.google.fi/?gfe_rd=cr&ei=Q5dgVu7zDqOr8wer_4OoCA Content-Length: 256 Server: GFE/2.0 <HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8"> <TITLE>302 Moved</TITLE></HEAD><BODY> <H1>302 Moved</H1> The document has moved <A HREF="http://www.google.fi/?gfe_rd=cr&ei=Q5dgVu7zDqOr8wer_4OoCA">here</A>. </BODY></HTML>
Jos haettua osoitetta ei ole olemassa, ohjelman tulee heittää poikkeus.
Tehtävässä ei ole testejä. Palauta tehtävä kun ohjelma toimii ylläolevan esimerkin mukaisesti.
HTTP-viestin rakenne: palvelimelta saapuva vastaus
Palvelimelle tehtyyn pyyntöön saadaan aina jonkinlainen vastaus. Jos tekstimuotoiseen osoitteeseen ei ole liitetty IP-osoitetta DNS-palvelimilla, selain ilmoittaa ettei palvelinta löydy. Jos palvelin löytyy, ja pyyntö saadaan tehtyä palvelimelle asti, tulee palvelimen myös vastata jollain tavalla.
Palvelimelta saatavan vastauksen sisältö on seuraavanlainen. Ensimmäisellä rivillä HTTP-protokollan versio, viestiin liittyvä statuskoodi, sekä statuskoodin selvennys. Tämän jälkeen on joukko otsakkeita, tyhjä rivi, ja mahdollinen vastausrunko. Vastausrunko ei ole pakollinen.
HTTP/versio statuskoodi selvennys otsake-1: arvo otsake-2: arvo valinnainen vastauksen runko
Esimerkiksi:
HTTP/1.1 200 OK Date: Mon, 01 Sep 2014 03:12:45 GMT Server: Apache/2.2.14 (Ubuntu) Vary: Accept-Encoding Content-Length: 973 Connection: close Content-Type: text/html;charset=UTF-8 .. runko ..
Kun palvelin vastaanottaa tiettyyn resurssiin liittyvän pyynnön, tekee se resurssiin liittyviä toimintoja ja palauttaa lopulta vastauksen. Kun selain saa vastauksen, tarkistaa se vastaukseen liittyvän statuskoodin ja siihen liittyvät tiedot -- tyypillinen statuskoodi on 200 (OK). Tämän jälkeen selain päättelee, mitä vastauksella tehdään, ja esimerkiksi tuottaa vastaukseen liittyvän web-sivun käyttäjälle.
Statuskoodit (status code) kuvaavat palvelimella tapahtunutta toimintaa kolmella numerolla. Statuskoodien avulla palvelin kertoo mahdollisista ongelmista tai tarvittavista lisätoimenpiteistä. Yleisin statuskoodi on 200, joka kertoo kaiken onnistuneen oikein. HTTP/1.1 sisältää viisi kategoriaa vastausviesteihin.
- 1**: informaatioviestit (esim 100 "Continue")
- 2**: onnistuneet tapahtumat (esim 200 "OK")
- 3**: asiakasohjelmistolta tarvitaan lisätoimintoja (esim 301 "Moved Permanently" tai 304 "Not Modified" eli hae välimuistista)
- 4**: virhe pyynnössä tai erikoistilanne (esim 401 "Not Authorized" ja 404 "Not Found")
- 5**: virhe palvelimella (esim 500 "Internal Server Error")
Palvelimen toiminta Java-maailmassa
Palvelimen toiminta muistuttaa huomattavasti aiemmin nähtyä yhteyden muodostamista. Toisin kuin yhteyttä toiseen koneeseen muodostaessa, palvelinta toteutettaessa luodaan ServerSocket-olio, joka kuuntelee tiettyä koneessa olevaa porttia. Kun toinen kone ottaa yhteyden palvelimeen, saadaan käyttöön Socket-olio, joka tarjoaa mahdollisuuden lukemiseen ja kirjoittamiseen.
Web-palvelin lukee tyypillisesti ensin pyynnön, jonka jälkeen pyyntöön kirjoitetaan vastaus. Alla on esimerkki yksinkertaisen palvelimen toiminnasta -- palvelin on toiminnassa vain yhden pyynnön ajan.
import java.io.PrintWriter;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.Scanner;
public class Main {
public static void main(String[] args) throws Exception {
// Create a Server Socket that listens to requests on port 8080
ServerSocket server = new ServerSocket(8080);
// Wait for a request from a machine, once it apprears, accept it
Socket socket = server.accept();
// Read the request
Scanner requestReader = new Scanner(socket.getInputStream());
// Write the response
PrintWriter responseWriter = new PrintWriter(socket.getOutputStream());
// Close the streams and the socket
requestReader.close();
responseWriter.close();
socket.close();
// Close the server
server.close();
}
}
Kokeile ylläolevaa ohjelmaa omalla koneellasi. Kuten aiemmissa web-sovelluksissa, voit tässäkin tehdä HTTP-pyynnön porttiin 8080 kirjoittamalla selaimella osoitteeksi http://localhost:8080. Jos sovelluksen käynnistäminen ei onnistu, tarkista että portti ei ole varattu (et ole sammuttanut jotain aiemmin tekemääsi web-sovellusta).
ServerSocket-olion accept-metodi on blokkaava. Tämä tarkoittaa sitä, että accept-metodia kutsuttaessa ohjelman suoritus jää odottamaan kunnes palvelimeen otetaan yhteys. Kun yhteys on muodostettu, accept-metodi palauttaa Socket-olion, jota käytetään palvelimen ja yhteyden ottaneen koneen väliseen kommunikointiin.
Ohjelmoijan näkökulmasta Socket-oliota -- ja porttia yleisemminkin -- voi ajatella tiedostona. Tiedostoon voi kirjoittaa ja siellä olevaa tietoa voi lukea. Kirjoitettava ja luettava tieto ei kuitenkaan tule tiedostosta, vaan yhteyden toisessa päässä toimivasta ohjelmasta.
Tyypillisesti palvelin halutaan toteuttaa niin, että se kuuntelee ja käsittelee pyyntöjä jatkuvasti. Tämä onnistuu toistolauseen avulla.
// Create a Server Socket that listens to requests on port 8080
ServerSocket server = new ServerSocket(8080);
while (true) {
// Wait for a request from a machine, once it apprears, accept it
Socket socket = server.accept();
// Read the request
Scanner requestReader = new Scanner(socket.getInputStream());
// Write the response
PrintWriter responseWriter = new PrintWriter(socket.getOutputStream());
// Close the streams and the socket
requestReader.close();
responseWriter.close();
socket.close();
}
Web-palvelimet käsittelevät useampia pyyntöjä lähes samanaikaisesti, sillä palvelinohjelmistot ovat säikeistettyjä. Käytännössä jokainen pyyntö käsitellään erillisessä säikeessä, joka luo pyyntöön vastauksen ja palauttaa sen käyttäjille. Javassa säikeille löytyy oma Thread-luokka. Emme kuitenkaan tällä kurssilla perehdy säikeiden käyttöön sen tarkemmin -- tätä varten löytyy kurssi Käyttöjärjestelmät.
Jos kokeilet käynnistää palvelimen koneellasi portissa 80, saatat törmätä virheviestiin. Tähän on useita mahdollisia syitä: (1) koneellasi oleva palomuuri- tai tietoturvaohjelmisto ei salli portin avaamista, (2) portti on jo käytössä (koneellasi oleva ohjelma -- esimerkiksi palvelin -- käyttää porttia 80), tai käyttäjätunnuksellasi ei ole oikeuksia portin avaamiseen.
Tietokoneella on käytössä portit 0-65535, joista "normaali" käyttäjä saa tyypillisesti avata vain suurempia kuin 1024 olevia. Lue lisää porteista Wikipediasta.
Toteuta web-palvelin, joka kuuntelee pyyntöjä porttiin 8080.
Jos pyydetty polku on /quit, tulee palvelin sammuttaa.
Muulloin, minkä tahansa pyynnön vastaukseen kirjoitetaan resurssin siirtymisestä kertova (302-alkuinen) HTTP-statuskoodi sekä palvelimen osoite, eli http://localhost:8080.
Ota samalla selvää kuinka monta pyyntöä selaimesi tekee palvelimelle, ennen kuin se ymmärtää että jotain on vialla.
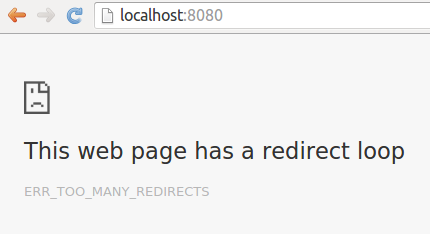
Tehtävässä ei ole testejä. Palauta ohjelma kun se toimii tehtävänannossa kuvatulla tavalla.
Google Chromen DevTools-apuvälineet löytää Tools-valikosta tai painamalla F12 (Linux). Apuvälineillä voi esimerkiksi tarkastella verkkoliikennettä ja lähetettyjä ja vastaanotettuja paketteja. Valitsemalla työvälineistä Network-välilehden, ja lataamalla sivun uudestaan, näet kaikki sivua varten ladattavat osat sekä kunkin osan lataamiseen kuluneen ajan.
Yksittäistä sivua avattaessa tehdään jokaista resurssia (kuva, tyylitiedosto, skripti) varten erillinen pyyntö. Esimerkiksi Helsingin sanomien verkkosivua avattaessa tehdään yli 270 erillistä pyyntöä.
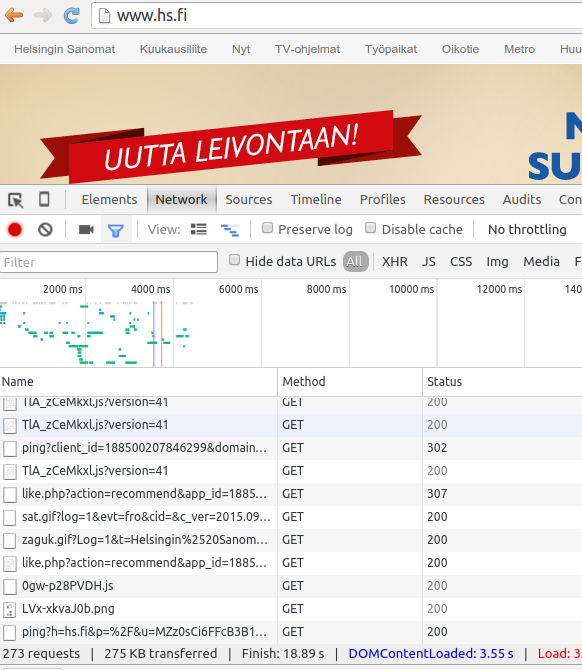
HTTP-liikenteen testaaminen telnet-työvälineellä
Linux-ympäristöissä on käytössä telnet-työkalu, jota voi käyttää yksinkertaisena asiakasohjelmistona pyyntöjen simulointiin. Telnet-yhteyden tietyn koneen tiettyyn porttiin saa luotua komennolla telnet isäntäkone portti. Esimerkiksi Helsingin sanomien www-palvelimelle saa yhteyden seuraavasti:
$ telnet www.hs.fi 80
Tätä seuraa telnetin infoa yhteyden muodostamisesta, jonka jälkeen pääsee kirjoittamaan pyynnön.
Trying 158.127.30.40... Connected to www.hs.fi. Escape character is '^]'.
Yritetään pyytää HTTP/1.1 -protokollalla juuridokumenttia. Huom! HTTP/1.1 -protokollassa tulee pyyntöön lisätä aina Host-otsake. Jos yhteys katkaistaan ennen kuin olet saanut kirjoitettua viestisi loppuun, ota apuusi tekstieditori ja copy-paste. Muistathan myös että viesti lopetetaan aina kahdella rivinvaihdolla.
GET / HTTP/1.1 Host: www.hs.fi
Palvelin palauttaa vastauksen, jossa on statuskoodi ja otsakkeita sekä dokumentin runko.
HTTP/1.1 200 OK X-UA-Compatible: IE=Edge,chrome=1 X-PageCache: true Content-Type: text/html;charset=UTF-8 Content-Language: en Content-Length: 485452 Set-Cookie: HSSESSIONID=0E325634FOOH806AC32F62E33F3CF624F3.fe04; Path=/; HttpOnly Vary: Accept-Encoding Connection: close <!DOCTYPE html> ...
Juuripolkua palvelimelta www.hs.fi haettaessa palvelin vastaa "OK" ja palauttaa dokumentin.
Jos käytössäsi ei ole Linux-konetta, voit käyttää Telnetiä esimerkiksi PuTTY-ohjelmiston avulla. Voit myös tehdä selailua käsin aiemmin toteutetun Java-ohjelman avulla.
Tee telnetillä pyyntö osoitteeseen hs.fi (portti 80) ja selvitä kuinka monta hyppyä tarvitaan siihen, että päästään Helsingin sanomien osoitteessa http://www.hs.fi olevalle etusivulle. Kuinka monta uudelleenohjausta palvelin palauttaa ennenkuin palvelin lopulta kertoo oikean etusivun osoitteen?
Huom! Jos et ehdi kirjoittamaan komentoa telnet-ikkunaan, voit ensin kirjoittaa sen esimerkiksi tekstieditoriin, ja kopioida sen sieltä telnet-ikkunaan.
GET / HTTP/1.1 Host: hs.fi
HTTP-protokollan pyyntötavat
HTTP-protokolla määrittelee kahdeksan erillistä pyyntötapaa (Request method), joista eniten käytettyjä ovat GET ja POST. Pyyntötavat määrittelevät rajoitteita ja suosituksia viestin rakenteeseen ja niiden prosessointiin palvelinpäässä. Esimerkiksi Java Servlet API (versio 2.5) sisältää seuraavan suosituksen GET-pyyntotapaan liittyen:
The GET method should be safe, that is, without any side effects for which users are held responsible. For example, most form queries have no side effects. If a client request is intended to change stored data, the request should use some other HTTP method.
Suomeksi yksinkertaistaen: GET-pyynnöt ovat tarkoitettu tiedon hakamiseen. Palvelinpuolen toiminnallisuutta suunniteltaessa tulee siis pyrkiä tilanteeseen, missä GET-tyyppisillä pyynnöillä ei muuteta palvelimella olevaa dataa.
Tiedon hakeminen: GET
GET-pyyntötapaa käytetään esimerkiksi dokumenttien hakemiseen: kun kirjoitat osoitteen selaimen osoitekenttään ja painat enter, selain tekee GET-pyynnön. GET-pyynnöt eivät tarvitse otsaketietoja HTTP/1.1:n vaatiman Host-otsakkeen lisäksi. Mahdolliset kyselyparametrit lähetetään palvelimelle osana haettavaa osoitetta.
GET /sivu.html?porkkana=1 HTTP/1.1 Host: palvelimen-osoite.net
Spring-sovelluksissa kontrollerimetodi kuuntelee GET-tyyppisiä pyyntöjä jos metodilla on annotaatio @GetMapping. Annotaatiolle määritellään parametrina kuunneltava polku.
Tiedon lähettäminen: POST
Käytännön ero POST- ja GET-kyselyn välillä on se, että POST-tyyppisillä pyynnoillä kyselyparametrit liitetään pyynnön runkoon. Rungon sisältö ja koko määritellään otsakeosiossa. POST-kyselyt mahdollistavat multimedian (kuvat, videot, musiikki, ...) lähettämisen palvelimelle.
POST /sivu.html HTTP/1.1 Host: palvelimen-osoite.net Content-Type: application/x-www-form-urlencoded Content-Length: 10 porkkana=1
Spring-sovelluksissa kontrollerimetodi kuuntelee POST-tyyppisiä pyyntöjä jos metodilla on annotaatio @PostMapping. Annotaatiolle määritellään parametrina kuunneltava polku.
Muita pyyntötyyppejä
Selaimen ja palvelimen välisessä kommunikoinnissa GET- ja POST-tyyppiset pyynnöt ovat eniten käytettyjä. Sivun tai siihen liittyvän osan kuten kuvan hakeminen tapahtuu käytännössä aina GET-tyyppisellä pyynnöllä, ja tiedon lähettäminen esimerkiksi lomakkeen kautta POST-tyyppisellä pyynnöllä. HTTP-protokolla määrittelee muitakin pyyntötyyppejä, joita käytetään palvelinohjelmistojen toteuttamisessa. Oleellisimpia ovat:
- OPTIONS pyytää tietoja resurssiin liittyvistä vaihtoehdoista (esimerkiksi voidaanko resurssi poistaa, ...)
- DELETE pyytää resurssin poistamista (
@DeleteMapping) - HEAD haluaa resurssiin liittyvät otsaketiedot, mutta ei resurssia
Web-sivustot sisältävät tyypillisesti useita erilaisia asioita: kuvia, tyylitiedostoja, musiikkia, videokuvaa ja niin edelleen. Sivun hakeminen tapahtuu useamman pyynnön aikana, missä ensin haetaan HTML-sivu, missä on viitteet sivun resursseihin kuten kuviin. Tämän jälkeen selain hakee jokaisen sivun resurssin erikseen. HTTP-protokollassa jokaisen resurssin hakemista varten muodostetaan uusi yhteys.
HTTP-protokollasta julkaistiin toukokuussa 2015 versio HTTP/2 (RFC 7540). Eräs uudistus protokollassa on palvelimelle jätetty mahdollisuus lähettää pyyntöön vastauksena useampia resursseja osana samaa vastausta. Tällöin yhteyden avaamiseen ja sulkemiseen käytetty aika vähenee ja web-sivustojen lataaminen mahdollisesti nopeutuu. HTTP/2 -protokolla sisältää muitakin parannuksia nykytilanteeseen -- suurin osa toiminnallisuudesta toteutetaan kuitenkin palvelinohjelmistoa pyörittävässä palvelimessa, eikä itse palvelinohjelmistossa.
HTML: Yhteinen dokumenttien esityskieli
HTML on rakenteellinen kuvauskieli, jolla voidaan esittää linkkejä sisältävää tekstiä sekä tekstin rakennetta. HTML koostuu elementeistä, jotka voivat olla sisäkkäin ja peräkkäin. Elementtejä käytetään ohjeina dokumentin jäsentämiseen ja käyttäjälle näyttämiseen. HTML-dokumenteissa elementit avataan elementin nimen sisältävällä pienempi kuin -merkillä (<) alkavalla ja suurempi kuin -merkkiin (>) loppuvalla merkkijonolla (<elementin_nimi>), ja suljetaan merkkijonolla jossa elementin pienempi kuin -merkin jälkeen on vinoviiva (</elementin_nimi>).
HTML-dokumentin rakennetta voi ajatella myös puuna. Juurisolmuna on elementti <html>, jonka lapsina ovat elementit <head> ja <body>.
Jos elementin sisällä ei ole muita elementtejä tai tekstisolmuja eli tekstiä, voi elementin yleensä avata ja sulkea samalla merkkijonolla: (<elementin_nimi />).
HTML:stä on useita erilaisia standardeja, joista viimeisin julkaistu versio löytyy osoitteesta http://www.w3.org/TR/html5/.
<!DOCTYPE html>
<html lang="fi">
<head>
<meta charset="UTF-8" />
<title>selainikkunassa näkyvä otsikko</title>
</head>
<body>
<p>
Tekstiä tekstielementin sisällä, tekstielementti runkoelementin sisällä,
runkoelementti html-elementin sisällä. Elementin sisältö voidaan asettaa
useammalle riville.
</p>
</body>
</html>
Ylläoleva HTML-dokumentti sisältää dokumentin tyypin ilmaisevan aloitustägin (<!DOCTYPE html>), dokumentin aloittavan html-elementin (<html>), otsake-elementin ja sivun otsikon (<head>, jonka sisällä <title>), sekä runkoelementin (<body>).
Elementit voivat sisältää attribuutteja ja attribuuteille voi antaa arvoja. Esimerkiksi ylläolevassa esimerkissä html-elementille on määritelty erillinen attribuutti lang, joka kertoo dokumentissa käytetystä kielestä. Ylläolevan esimerkin otsakkeessa on myös metaelementti, jota käytetään lisävinkin antamiseen selaimelle: "dokumentissa käytetään UTF-8 merkistöä". Tämä kannattaa olla dokumenteissa aina.
Nykyaikaiset web-sivut sisältävät paljon muutakin kuin sarjan HTML-elementtejä. Linkitetyt resurssit, kuten kuvat ja tyylitiedostot, ovat oleellisia sivun ulkoasun ja rakenteen luomisessa. Selainpuolella suoritettavat skriptitiedostot, erityisesti Javascript, ovat luoneet huomattavan määrän syvyyttä nykyaikaiseen web-kokemukseen. Tällä kurssilla emme juurikaan syvenny selainpuolen toiminnallisuuteen.
Käytämme kurssilla Thymeleaf-komponenttia dynaamisen sisällön lisäämiseen sivuille. Thymeleaf on erittäin tarkka HTML-dokumentin muodosta, ja pienikin poikkeama voi johtaa virhetilanteeseen. Kannattaakin aina edetä pienin askelein, ja aina muokata ja testata vain yhtä paikkaa kerrallaan. Tällöin virhetilanteessa tyypillisesti tietää mistä kohdasta kannattaa lähteä etsimään virhettä.
Tiedon tallentaminen ja hakeminen
Suurin osa web-sovelluksista tarvitsee tiedon tallentamis- ja hakutoiminnallisuutta. Tietoa voidaan tallentaa levylle tiedostoihin, tai sitä voidaan tallentaa erilaisiin tietokantaohjelmistoihin. Nämä tietokantaohjelmistot voivat sijaita erillisellä koneella web-sovelluksesta, tai ne voivat itsekin olla web-sovelluksia. Toteutusperiaatteista riippumatta näiden sovellusten ensisijainen tehtävä on varmistaa, ettei käytettävä tieto katoa.
Tietokannan käyttäminen ohjelmallisesti
Käytämme tällä kurssilla H2-tietokantamoottoria, joka tarjoaa rajapinan SQL-kyselyiden tekemiseen. H2-tietokantamoottorin saa käyttöön lisäämällä projektin pom.xml-tiedostoon seuraavan riippuvuuden.
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.4.196</version>
</dependency>
Tietokantaa käyttävä ohjelma sisältää tyypillisesti tietokantayhteyden luomisen, tietokantakyselyn tekemisen tietokannalle, sekä tietokannan palauttamien vastausten läpikäynnin. Javalla edellämainittu näyttää esimerkiksi seuraavalta -- alla oletamme, että käytössä on tietokantataulu "Book", jossa on sarakkeet "id" ja "name".
// Open connection to database
Connection connection = DriverManager.getConnection("jdbc:h2:./database", "sa", "");
// Create query and retrieve result set
ResultSet resultSet = connection.createStatement().executeQuery("SELECT * FROM Book");
// Iterate through results
while (resultSet.next()) {
String id = resultSet.getString("id");
String name = resultSet.getString("name");
System.out.println(id + "\t" + name);
}
// Close the resultset and the connection
resultSet.close();
connection.close();
Oleellisin tässä on luokka ResultSet, joka tarjoaa pääsyn rivikohtaisiin tuloksiin. Kurssin tietokantojen perusteet oppimateriaali sisältää myös hieman tietoa ohjelmallisista tietokantakyselyistä.
Komento DriverManager.getConnection("jdbc:h2:./database", "sa", ""); luo JDBC-yhteyden tietokantaan nimeltä "database". Käyttäjätunnuksena käytetään tunnusta "sa", jonka salasana on "".
Jos "database"-nimistä tietokantaa ei ole, luodaan se levyjärjestelmään projektin juureen. Tässä tapauksessa luodaan tiedosto database.mv.db sekä mahdollisesti database.trace.db. Tietokantayhteyden voi luoda myös muistiin ladattavaan tietokantaan, jolloin tietokantaa ei luoda levyjärjestelmään -- tällöin tietokannassa oleva tieto kuitenkin katoaa ohjelman sammutuksen yhteydessä.
Tarkempi opas H2-tietokannan tarjoamiin toimintoihin löytyy osoitteesta http://www.h2database.com/html/tutorial.html.
Tietokannalla on tyypillisesti skeema, joka määrittelee tietokantataulujen rakenteen. Rakenteen lisäksi tietokantatauluissa on dataa. Kun tietokantasovellus käynnistetään ensimmäistä kertaa, nämä tyypillisesti ladataan myös käyttöön. H2-tietokantamoottori tarjoaa tätä varten työvälineitä RunScript-luokassa. Alla olevassa esimerkissä tietokantayhteyden avaamisen jälkeen yritetään lukea tekstitiedostoista database-schema.sql ja database-import.sql niiden sisältö tietokantaan.
Tiedosto database-schema.sql sisältää tietokantataulujen määrittelyt, ja tiedosto database-import.sql tietokantaan lisättävää tietoa. Järjestys on oleellinen -- jos tietokantataulujen määrittelyiden syöttämisessä tapahtuu virhe, ovat tietokantataulut olemassa. Tällöin tietoa ei myöskään ladata tietokantaan.
// Open connection to database
Connection connection = DriverManager.getConnection("jdbc:h2:./database", "sa", "");
try {
// If database has not yet been created, create it
RunScript.execute(connection, new FileReader("database-schema.sql"));
RunScript.execute(connection, new FileReader("database-import.sql"));
} catch (Throwable t) {
System.out.println(t.getMessage());
}
// ...
Käytössäsi on agenttien tietoja sisältävä tietokantataulu, joka on määritelty seuraavasti:
CREATE TABLE Agent (
id varchar(9) PRIMARY KEY,
name varchar(200)
);
Kirjoita ohjelma, joka tulostaa kaikki tietokannassa olevat agentit.
Tehtävässä ei ole testejä. Palauta tehtävä kun se toimii halutulla tavalla.
Käytössäsi on edellisessä tehtävässä käytetty agenttien tietoja sisältävä tietokantataulu. Toteuta tässä tehtävässä tietokantaan lisäämistoiminnallisuus. Ohjelman tulee toimia seuraavasti:
Agents in database: Secret Clank Gecko Gex Robocod James Pond Fox Sasha Nein Add one: What id? Riddle What name? Voldemort Agents in database: Secret Clank Gecko Gex Robocod James Pond Fox Sasha Nein Riddle Voldemort
Seuraavalla käynnistyskerralla agentti Voldemort on tietokannassa heti sovelluksen käynnistyessä.
Agents in database: Secret Clank Gecko Gex Robocod James Pond Fox Sasha Nein Riddle Voldemort Add one: What id? Feather What name? Major Tickle Agents in database: Secret Clank Gecko Gex Robocod James Pond Fox Sasha Nein Riddle Voldemort Feather Major Tickle
Tehtävässä ei ole testejä. Palauta tehtävä kun se toimii halutulla tavalla.
Edelliset tehtävät antavat vain pienen pintaraapaisun siihen teknologiaan, minkä päälle nykyaikaisten web-sovellusten käyttämät tietokantakirjastot rakentuvat. Vaikka web-sovelluksia voi toteuttaa ilman suurempaa tietämystä niihin liittyvistä taustateknologioista ja ratkaisuista, syventyminen teemaan kannattaa.
Oliot ja relaatiotietokannat
Relaatiotietokantojen ja olio-ohjelmoinnin välimaastossa sijaitsee tarve olioiden muuntamiseen tietokantataulun riveiksi ja takaisin. Tähän tehtävään käytetään ORM (Object-relational mapping) -ohjelmointitekniikkaa, jota varten löytyy merkittävä määrä valmiita työvälineitä sekä kirjastoja.
ORM-työvälineet tarjoavat ohjelmistokehittäjälle mm. toiminnallisuutta tietokantataulujen luomiseen määritellyistä luokista, jonka lisäksi ne helpottavat kyselyjen muodostamista ja hallinnoivat luokkien välisiä viittauksia. Tällöin ohjelmoijan vastuulle jää sovellukselle tarpeellisten kyselyiden toteuttaminen vain niiltä osin kun ORM-kehykset eivät niitä pysty automaattisesti luomaan.
Relaatiotietokantojen käsittelyyn Javalla löytyy joukko ORM-sovelluksia. Oracle/Sun standardoi olioiden tallentamisen relaatiotietokantoihin JPA (Java Persistence API) -standardilla. JPA:n toteuttavat kirjastot (esim. Hibernate) abstrahoivat relaatiotietokannan ja helpottavat kyselyjen tekemistä suoraan ohjelmakoodista.
Koska huomattava osa tietokantatoiminnallisuudesta on hyvin samankaltaista ("tallenna", "lataa", "poista", ...), voidaan perustoiminnallisuus piilottaa käytännössä kokonaan ohjelmoijalta. Tällöin ohjelmoijalle jää tehtäväksi usein vain sopivan rajapintaluokan määrittely. Esimerkiksi aiemmin nähdyn Henkilo-luokan tallentamistoiminnallisuuteen tarvitaan seuraavanlainen rajapinta.
// pakkaus ja importit
public interface HenkiloRepository extends JpaRepository<Henkilo, Long> {
}Kun rajapintaa käytetään, Spring osaa tuoda sopivan toteutuksen ohjelman käyttöön. Käytössä tulee olla Maven-riippuvuus Spring-projektin Data JPA -kirjastoon.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>Luokan määrittely tallennettavaksi
JPA-standardin mukaan luokka tulee määritellä entiteetiksi, jotta siitä tehtyjä olioita voi tallentaa JPA:n avulla tietokantaan.
Jokaisella tietokantaan tallennettavalla luokalla tulee olla annotaatio @Entity sekä @Id-annotaatiolla merkattu attribuutti, joka toimii tietokantataulun ensisijaisena avaimena. JPA:ta käytettäessä id-attribuutti on usein numeerinen (Long tai Integer), mutta merkkijonojen käyttö on yleistymässä. Näiden lisäksi, luokan tulee toteuttaa Serializable-rajapinta.
Numeeriselle avainattribuutille voidaan lisäksi määritellä annotaatio @GeneratedValue(strategy = GenerationType.AUTO), joka antaa id-kentän arvojen luomisen vastuun tietokannalle. Tietokantatauluun tallennettava luokka näyttää seuraavalta:
// pakkaus
import java.io.Serializable;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Henkilo implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String nimi;
// getterit ja setterit
Tietokantaan luotavien sarakkeiden ja tietokantataulun nimiä voi muokata annotaatioiden @Column ja @Table avulla.
// pakkaus
import java.io.Serializable;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "Henkilo")
public class Henkilo implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "id")
private Long id;
@Column(name = "nimi")
private String nimi;
// getterit ja setterit
Ylläoleva konfiguraatio määrittelee luokasta Henkilo tietokantataulun nimeltä "Henkilo", jolla on sarakkeet "id" ja "nimi". Sarakkeiden tyypit päätellään muuttujien tyyppien perusteella.
Spring Data JPA:n AbstractPersistable-luokkaa käytettäessä ylläolevan luokan määrittely kutistuu hieman. Yläluokka AbstractPersistable määrittelee pääavaimen, jonka lisäksi luokka toteuttaa myös rajapinnan Serializable.
// pakkaus ja importit
@Entity
@Table(name = "Henkilo")
public class Henkilo extends AbstractPersistable<Long> {
@Column(name = "nimi")
private String nimi;
// getterit ja setterit
Jos tietokantataulun ja sarakkeiden annotaatioita ei eksplisiittisesti määritellä, niiden nimet päätellään luokan ja muuttujien nimistä.
// pakkaus ja importit
@Entity
public class Henkilo extends AbstractPersistable<Long> {
private String nimi;
// getterit ja setterit
Rajapinta tallennettavan luokan käsittelyyn
Kun käytössämme on tietokantaan tallennettava luokka, voimme luoda tietokannan käsittelyyn käytettävän rajapinnan. Kutsutaan tätä rajapintaoliota nimellä HenkiloRepository.
// pakkaus
import wad.domain.Henkilo;
import org.springframework.data.jpa.repository.JpaRepository;
public interface HenkiloRepository extends JpaRepository<Henkilo, Long> {
}
Rajapinta perii Spring Data-projektin JpaRepository-rajapinnan; samalla kerromme, että tallennettava olio on tyyppiä Henkilo ja että tallennettavan olion pääavain on tyyppiä Long. Tämä tyyppi on sama kuin aiemmin AbstractPersistable-luokan perinnässä parametriksi asetettu tyyppi. Spring osaa käynnistyessään etsiä mm. JpaRepository-rajapintaluokan periviä luokkia. Jos niitä löytyy, se luo niiden pohjalta tietokannan käsittelyyn sopivan olion sekä asettaa olion ohjelmoijan haluamiin muuttujiin.
Tietokanta-abstraktion tuominen kontrolleriin
Kun olemme luoneet rajapinnan HenkiloRepository, voimme lisätä sen kontrolleriluokkaan. Tämä tapahtuu määrittelemällä tietokanta-abstraktiota kuvaavan rajapinnan olio kontrollerin oliomuuttujaksi. Oliomuuttujalle asetetaan lisäksi annotaatio @Autowired, mikä kertoo Springille, että rajapintaan tulee asettaa olio. Palaamme annotaation @Autowired merkitykseen tarkemmin myöhemmin.
// ...
@Controller
public class HenkiloController {
@Autowired
private HenkiloRepository henkiloRepository;
// ...
}
Nyt tietokantaan pääsee käsiksi HenkiloRepository-olion kautta. Osoitteessa http://docs.spring.io/spring-data/jpa/docs/current/api/org/springframework/data/jpa/repository/JpaRepository.html on JpaRepository-rajapinnan API-kuvaus, mistä löytyy rajapinnan tarjoamien metodien kuvauksia. Voimme esimerkiksi toteuttaa tietokannassa olevien olioiden listauksen sekä yksittäisen olion haun seuraavasti:
// ...
@Controller
public class HenkiloController {
@Autowired
private HenkiloRepository henkiloRepository;
@GetMapping("/")
public String list(Model model) {
model.addAttribute("list", henkiloRepository.findAll());
return "henkilot"; // erillinen henkilot.html
}
@GetMapping("/{id}")
public String findOne(Model model, @PathVariable Long id) {
Henkilo henkilo = henkiloRepository.getOne(id);
model.addAttribute("henkilo", henkilo);
return "henkilo"; // erillinen henkilo.html
}
}
Pääavaimella etsittäessä tulee löytyä korkeintaan yksi henkilö Spring Data JPA:n API käyttää osassa kyselyitä Java 8:n tarjoamaa Optional-luokkaa tämän rajoitteen varmistamiseen.
Tässä tehtävässä on valmiiksi toteutettuna tietokantatoiminnallisuus sekä esineiden noutaminen tietokannasta. Lisää sovellukseen toiminnallisuus, jonka avulla esineiden tallentaminen tietokantaan onnistuu valmiiksi määritellyllä lomakkeella.
Toteuta siis kontrolleriluokkaan sopiva metodi (tarkista parametrin tai parametrien nimet HTML-sivulta) ja hyödynnä rajapinnan ItemRepository tarjoamia metodeja.
Alla esimerkki sovelluksesta kun tietokantaan on lisätty muutama rivi:
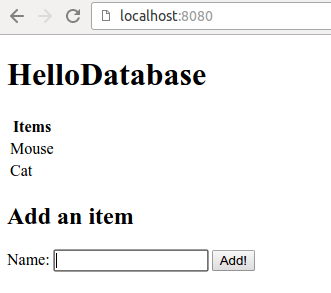
Sovellus luo oletuksena tehtäväpohjan juuripolkuun tietokantatiedostot database.mv.db ja database.trace.db. Jos haluat tyhjentää tietokannan, poista nämä tiedostot ja käynnistä sovellus uudestaan (tai, vaihtoehtoisesti, lisää ohjelmaan poistotoiminnallisuus..)
Luo tässä ensimmäisen osan TodoApplication-tehtävässä nähty tehtävien hallintaan tarkoitettu toiminnallisuus mutta siten, että tehtävät tallennetaan tietokantaan. Tässä entiteettiluokan nimeksi tulee asettaa TodoItem ja avaimen tyypin tulee olla Long.
@Entity
public class TodoItem extends AbstractPersistable<Long> {
...
Noudata lisäksi tehtäväpohjassa annettujen HTML-sivujen rakennetta ja toiminnallisuutta.
Sovellus luo tehtäväpohjan juuripolkuun tietokantatiedostot database.mv.db ja database.trace.db. Tietokannan skeema alustetaan kuitenkin uudestaan jokaisen palvelimen käynnistyksen yhteydessä, joten voit hyvin muuttaa tietokantaan tallennettavan tiedon muotoa. Palaamme olemassaolevan tietokannan päivittämiseen myöhemmin kurssilla.
Tehtävä on kahden yksittäisen tehtävän arvoinen.
Transaktioiden hallinta
Transaktioiden avulla varmistetaan, että joko kaikki halutut operaatiot suoritetaan, tai yhtäkään niistä ei suoriteta.
Tietokantatransaktiot määritellään metodi- tai luokkatasolla annotaation @Transactional avulla. Annotaatiolla @Transactional merkittyä metodia suoritettaessa metodin alussa aloitetaan tietokantatransaktio, jossa tehdyt muutokset viedään tietokantaan metodin lopussa. Jos annotaatio @Transactional määritellään luokkatasolla, se koskee jokaista luokan metodia.
Alla on kuvattuna tilisiirto, joka on ehkäpä klassisin transaktiota vaativa tietokantaesimerkki. Jos ohjelmakoodin suoritus epäonnistuu (esim. päätyy poikkeukseen) sen jälkeen kun toiselta tililtä on otettu rahaa, mutta toiselle sitä ei vielä ole lisätty, peruuntuu myös rahan ottaminen tililtä. Jos metodille ei olisi määritelty @Transactional-annotaatiota, rahat katoaisivat.
@Transactional
public void siirraRahaa(Long tililta, Long tilille, Double paljonko) {
Tili mista = tiliRepository.getOne(tililta);
Tili minne = tiliRepository.getOne(tilille);
mista.setSaldo(mista.getSaldo() - paljonko);
minne.setSaldo(minne.getSaldo() + paljonko);
}
Annotaatiolle @Transactional voidaan määritellä parametri readOnly, jonka avulla määritellään kirjoitetaanko muutokset tietokantaan. Jos parametrin readOnly arvo on true, metodiin liittyvä transaktio perutaan metodin lopussa (rollback). Tällöin metodi ei yksinkertaisesti voi muuttaa tietokannassa olevaa tietoa.
Rajapinnalla JpaRepository on määriteltynä transaktiot luokkatasolle. Tämä tarkoittaa sitä, että yksittäiset tallennusoperaatiot toimivat myös ilman @Transactional-annotaatiota.
Entiteettien automaattinen hallinta
Jos metodille on määritelty annotaatio @Transactional, pitää JPA kirjaa tietokannasta ladatuista entiteeteistä ja tarkastelee niihin tapahtuvia muutoksia. Muutokset viedään tietokantaan metodin suorituksen lopussa. Aiempi esimerkkimme siis tekee suorittaa tilisiirrot vaikka tilejä ei erikseen tallennettaisi.
@Transactional
public void siirraRahaa(Long tililta, Long tilille, Double paljonko) {
Tili mista = tiliRepository.getOne(tililta);
Tili minne = tiliRepository.getOne(tilille);
mista.setSaldo(mista.getSaldo() - paljonko);
minne.setSaldo(minne.getSaldo() + paljonko);
}
Jos taas annotaatiota @Transactional ei olisi määritelty, tulisi tilit erikseen tallentaa, jotta niihin tapahtuneet muutokset vietäisiin tietokantaan.
public void siirraRahaa(Long tililta, Long tilille, Double paljonko) {
Tili mista = tiliRepository.getOne(tililta);
Tili minne = tiliRepository.getOne(tilille);
mista.setSaldo(mista.getSaldo() - paljonko);
minne.setSaldo(minne.getSaldo() + paljonko);
tiliRepository.save(mista);
tiliRepository.save(minne);
}Tehtäväpohjassa on valmiina yksinkertainen sovellus tilien hallintaan ja tilisiirtojen tekemiseen. Sovelluksen tilisiirtotoiminnallisuudessa on kuitenkin vielä viilattavaa. Mitä tietokantamuutoksille tapahtuisi jos sovellus kaatuu kesken suorituksen?
Selvitä minkälaisia korjauksia tilisiirtotoiminnallisuus tarvitsee ja toteuta ne.
Tehtävässä ei ole automaattisia testejä. Palauta tehtävä TMC:lle kun olet ratkaissut oleellisimmat tilisiirtoon liittyvät ongelmat. Huom! Tässä ei tarvitse miettiä esimerkiksi tunnistautumista.
Viitteet tietokantataulujen välillä
Luokkien -- tai tietokantataulujen -- väliset viittaukset tapahtuvat kuten normaalistikin, mutta ohjelmoijan tulee lisäksi määritellä osallistumisrajoitteet. Osallistumisrajoitteet -- yksi moneen (one to many), moni yhteen (many to one), moni moneen (many to many) lisätään annotaatioiden avulla. Luodaan esimerkiksi luokka Henkilo, joka voi omistaa joukon esineitä. Kukin esine on vain yhden henkilön omistama -- suhde siis yksi moneen -- annotaatio @OneToMany.
@Entity
public class Henkilo extends AbstractPersistable<Long> {
private String nimi;
@OneToMany
private List<Esine> esineet;
// ...
public List<Esine> getEsineet() {
if (this.esineet == null) {
this.esineet = new ArrayList<>();
}
return this.esineet;
}
// ...
Yllä olevaa esimerkkiä käytettäessä luokalle Esine luodaan tietokantatauluun automaattisesti sarake, johon tallennetaan omistavan Henkilo-olion yksilöivä tunnus. Esinelista luodaan tarvittaessa jos sitä ei ole jo olemassa.
Monesta moneen yhteys tapahtuu tietokantatauluja suunniteltaessa liitostaulun avulla. JPA:ssa moni-moneen yhteydet määritellään annotaatiolla @ManyToMany. Tällöin yhteys tulee merkitä kummallekin puolelle. Jos henkilö voi omistaa useita esineitä, ja esineellä voi olla useita omistajia, toteutus on seuraavanlainen.
@Entity
public class Henkilo extends AbstractPersistable<Long> {
private String nimi;
@ManyToMany
private List<Esine> esineet;
...
@Entity
public class Esine extends AbstractPersistable<Long> {
private String nimi;
private Double paino;
@ManyToMany(mappedBy = "esineet")
private List<Henkilo> omistajat;
Yllä oleva määritelmä luo liitostaulun Esine- ja Henkilo-taulujen välille. Esine-luokassa olevassa @ManyToMany-annotaatiossa oleva parametri mappedBy = "esineet" kertoo että Esine-luokan omistajat-lista saadaan liitostaulusta, ja että se kytketään luokan Henkilo listaan esineet.
Kun kirjoitat NetBeansissa viitteen entiteettiluokasta toiseen, ohjelmointiympäristö kuten NetBeans kysyy viittauksen tyyppiä. Tutustu tähän toiminnallisuuteen, sillä se helpottaa työtäsi jatkossa merkittävästi.
Sovelluksessa on toteutettuna entiteetit tilien ja asiakkaiden hallintaan, mutta niiden väliltä puuttuu kytkös. Muokkaa sovellusta siten, että asiakkaalla voi olla monta tiliä, mutta jokaiseen tiliin liittyy tasan yksi asiakas.
Tilin lisäämisen tulee kytkeä tili myös asiakkaaseen. Alla olevassa esimerkissä tietokannassa on kaksi asiakasta ja kolme tiliä.
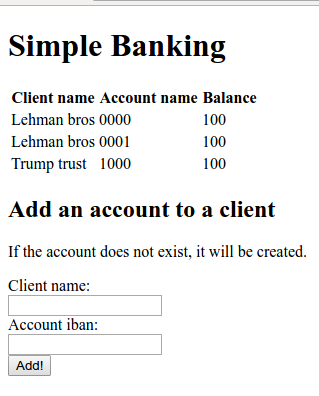
Kun olet valmis, lähetä sovellus TMC:lle tarkistettavaksi.
Transaktiot ja viitteiden automaattinen hallinta
Haluamme usein tallentaa olion joka viittaa olioon, josta viitataan takaisin.
Pohditaan tätä kontekstissa, jossa tavoitteena on lisätä uusia Henkilo-olioita olemassaolevan esineen omistajiksi. Esineellä on lista sen omistajista. Yksi ratkaisu on seuraava.
@Transactional
public void lisaaOmistaja(Long henkiloId, Long esineId) {
Esine esine = esineRepository.getOne(esineId);
Henkilo henkilo = henkiloRepository.getOne(henkiloId);
henkilo.getEsineet().add(esine);
esine.getOmistajat().add(henkilo);
}
Koska ylläolevassa esimerkissä koodi suoritetaan transaktion sisällä, ladattuihin olioihin tehdyt muutokset viedään tietokantaan transaktion lopussa.
Olemassaolevan olion poistaminen
Pohditaan seuraavaksi tilannetta, jossa haluaisimme poistaa tietyn henkilön. Ensimmäinen hahmotelma on kutakuinkin seuraavanlainen:
@Transactional
public void remove(Long henkiloId) {
personRepository.deleteById(henkiloId);
}
Yllä ongelmana on kuitenkin se, että esineet eivät kadota viittausta henkilöön. Käytännössä henkilö jää "haamuksi" järjestelmään tai saamme virheen poistoa yrittäessä. Jos haluamme poistaa viittaukset henkilöön, joudumme tekemään sen käsin.
@Transactional
public void remove(Long henkiloId) {
Henkilo henkilo = personRepository.getOne(henkiloId);
for (Esine esine: henkilo.getEsineet()) {
esine.getOmistajat().remove(henkilo);
}
personRepository.delete(person);
}Ei kovin nättiä.
Omien kyselyiden toteuttaminen
Spring Data JPA ei tarjoa kaikkia kyselyitä valmiiksi. Uudet kyselyt, erityisesti attribuuttien perusteella tapahtuvat kyselyt, tulee määritellä erikseen. Laajennetaan aiemmin määriteltyä rajapintaa HenkiloRepository siten, että sillä on metodi List<Henkilo> findByNimi(String nimi) -- eli hae henkilöt, joilla on tietty nimi.
// pakkaus
import org.springframework.data.repository.JpaRepository;
public interface HenkiloRepository extends JpaRepository<Henkilo, Long> {
List<Henkilo> findByNimi(String nimi);
}
Ylläoleva esimerkki on esimerkki kyselystä, johon ei tarvitse erillistä toteutusta. Koska tietokantataululla on valmis sarake nimi, arvaa Spring Data JPA että kysely olisi muotoa SELECT * FROM Henkilo WHERE nimi = :nimi ja luo sen valmiiksi. Lisää Spring Data JPA:n kyselyistä löytyy sen dokumentaatiosta.
Java Persistence APIn kautta tehdyt kyselyt eivät ole natiivia SQL:ää, vaan seuraavat JPQL-määritelmää (Java Persistence Query Language), joka kuitenkin muistuttaa SQL:ää. JPQL-kielestä löytyy lisää tietoa osoitteesta http://docs.oracle.com/javaee/6/tutorial/doc/bnbtg.html.
Tehdään toinen esimerkki, jossa joudumme oikeasti luomaan oman kyselyn. Lisätään rajapinnalle HenkiloRepository metodi findJackBauer, joka suorittaa kyselyn "SELECT h FROM Henkilo h WHERE h.nimi = 'Jack Bauer'".
// pakkaus
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.JpaRepository;
public interface HenkiloRepository extends JpaRepository<Henkilo, Long> {
List<Henkilo> findByNimi(String nimi);
@Query("SELECT h FROM Henkilo h WHERE h.nimi = 'Jack Bauer'")
Henkilo findJackBauer();
}
Käytössämme on nyt myös metodi findJackBauer, joka suorittaa @Query-annotaatiossa määritellyn kyselyn. Tarkempi kuvaus kyselyiden määrittelystä osana rajapintaa löytyy Spring Data JPAn dokumentaatiosta.
Viitattujen olioiden noutaminen tietokannasta
Tietokanta-abstraktioita tarjoavat komponentit kuten Hibernate päättävät mitä tehdään haettavaan olioon liittyville viitteille. Yksi vaihtoehto on hakea viitatut oliot automaattisesti kyselyn yhteydessä ("Eager"), toinen vaihtoehto taas on hakea viitatut oliot vasta kun niitä pyydetään eksplisiittisesti esimerkiksi get-metodin kautta ("Lazy").
Tyypillisesti one-to-many ja many-to-many -viitteet haetaan vasta niitä tarvittaessa, ja one-to-one ja many-to-one viitteet heti. Oletuskäyttäytymistä voi muuttaa FetchType-parametrin avulla. Esimerkiksi alla ehdotamme, että asunnot-lista noudetaan heti.
// pakkaus
@Entity
public class Henkilo extends AbstractPersistable<Long> {
private String nimi;
// oletamme, että Asunto-entiteetti on olemassa
@OneToMany(fetch=FetchType.EAGER)
@JoinColumn
private List<Asunto> asunnot;
// getterit ja setterit
}
Käytännössä tietokannasta tarvittaessa haku toteutetaan muokkaamalla get-metodia siten, että tietokantakysely tapahtuu metodia kutsuttaessa. Staattisesti tyypitetyissä ohjelmointikielissä tämä käytännössä vaatii sitä, että luokkien rakennetta muutetaan joko ajonaikaisesti tai lähdekooditiedostojen kääntövaiheessa -- käyttämämme komponentit tekevät tämän puolestamme.
N+1 Kyselyn ongelma
Viitattujen olioiden lataaminen vasta niitä tarvittaessa on yleisesti ottaen hyvä idea, mutta sillä on myös kääntöpuolensa. Pohditaan tilannetta, missä kirjalla voi olla monta kirjoittajaa, ja kirjoittajalla monta kirjaa -- @ManyToMany. Jos haemme tietokannasta listan kirjoja (1 kysely), ja haluamme tulostaa kirjoihin liittyvät kirjoittajat, tehdään jokaisen kirjan kohdalla erillinen kysely kyseisen kirjan kirjoittajille (n kyselyä). Tätä ongelmaa kutsutaan N+1 -kyselyn ongelmaksi.
Jos kirjoja tarvitaan sekä ilman kirjoittajaa että kirjoittajan kanssa, on FetchType-parametrin asettaminen EAGER-tyyppiseksi yksi vastaus. Tällöin kuitenkin osassa tapauksista haetaan ylimääräistä dataa tietokannasta. Toinen vaihtoehto on luoda erillinen kysely yhdelle vaihtoehdoista, ja lisätä kyselyyn vinkki (Spring Data JPA, applying query hints) kyselyn toivotusta toiminnallisuudesta.
Muutamat ovat kysyneet miten ohjelmakoodissa tehdyt muutokset saa automaattisesti päivittymään selaimeen. Javalla toimivat ohjelmat käynnistetään tavukoodiksi, ja nämä tavukoodit suoritetaan ohjelmaa käynnistettäessä, joten automaattinen siirto ei ole täysin suoraviivaista.
Tähän löytyy kuitenkin asian osittain ratkaiseva projekti, spring-boot-devtools, joka tarjoaa välineitä ohjelmistokehitysprosessin nopeuttamiseksi.
Projektin lisääminen Maveniin tapahtuu seuraavan riippuvuuden avulla:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
</dependency>
Kun ylläoleva riippuvuus on lisätty projektiin, käynnistetään ohjelman käynnistyksen yhteydessä myös LiveReload-palvelin. Kun selaimeen asentaa LiveReload-liitännäisen (Chromelle osoitteesta https://chrome.google.com/webstore/detail/livereload/jnihajbhpnppcggbcgedagnkighmdlei) ja kytkee liitännäisen päälle, LiveReload-liitännäinen ja palvelin keskustelevat toistensa kanssa ja päivittävät näkymää tarvittaessa.
Devtools-projektin lisääminen sovellukseen johtaa myös siihen, että sovellus ladataan uudestaan aina kun sen lähdekoodi muuttuu. Tämän lisäksi osoitteessa http://localhost:8080/h2-console on tietokantakonsoli, jonka avulla voi käydä tarkastelemassa tietokannan tilaa -- tietokannan JDBC URL on oletuksena jdbc:h2:mem:testdb. Huom! Tämä toimii vain, jos käytössä on H2-tietokantamoottori.
Jatkokehitetään tässä tehtävässä sovellusta lentokoneiden ja lentokenttien hallintaan. Projektissa on jo valmiina ohjelmisto, jossa voidaan lisätä ja poistaa lentokoneita. Tavoitteena on lisätä toiminnallisuus lentokoneiden kotikenttien asettamiseksi.
Tallennettavat: Aircraft ja Airport.
Lisää luokkaan Aircraft attribuutti airport, joka kuvaa lentokoneen kotikenttää, ja on tyyppiä Airport. Koska usealla lentokoneella voi olla sama kotikenttä, käytä attribuutille airport annotaatiota @ManyToOne. Lisää attribuutille myös @JoinColumn-annotaatio, jonka avulla kerrotaan että tämä attribuutti viittaa toiseen tauluun. Lisää luokalle myös oleelliset get- ja set-metodit.
Lisää seuraavaksi Airport-luokkaan attribuutti aircrafts, joka kuvaa kaikkia koneita, keiden kotikenttä kyseinen kenttä on, ja joka on tyyppiä List<Aircraft>. Koska yhdellä lentokentällä voi olla useita koneita, lisää attribuutille annotaatio @OneToMany. Koska luokan Aircraft attribuutti airport viittaa tähän luokkaan, aseta annotaatioon @OneToMany parametri mappedBy="airport". Nyt luokka Airport tietää että attribuuttiin aircrafts tulee ladata kaikki Aircraft-oliot, jotka viittaavat juuri tähän kenttään.
Lisää lisäksi Airport-luokan @OneToMany-annotaatioon parametri fetch = FetchType.EAGER, jolloin lentokenttään liittyvät lentokoneet haetaan kyselyn yhteydessä.
Lisää lopuksi luokalle Airport oleelliset get- ja set-metodit.
Lentokentän asetus lentokoneelle
Lisää sovellukselle toiminnallisuus lentokentän lisäämiseen lentokoneelle. Käyttöliittymä sisältää jo tarvittavan toiminnallisuuden, joten käytännössä tässä tulee toteuttaa luokalle AircraftController metodi String assignAirport. Kun käyttäjä lisää lentokoneelle lentokenttää, käyttöliittymä lähettää POST-tyyppisen kyselyn osoitteeseen /aircrafts/{aircraftId}/airports, missä aircraftId on lentokoneen tietokantatunnus. Pyynnön mukana tulee lisäksi parametri airportId, joka sisältää lentokentän tietokantatunnuksen.
Toteuta metodi siten, että haet aluksi pyynnössä saatuja tunnuksia käyttäen lentokoneen ja lentokentän, tämän jälkeen asetat lentokoneelle lentokentän ja lentokentälle lentokoneen, ja lopuksi tallennat haetut oliot.
Ohjaa lopuksi pyyntö osoitteeseen /aircrafts
Kun olet valmis, lähetä sovellus TMC:lle tarkistettavaksi.
Tämä on avoin tehtävä jossa saat itse suunnitella huomattavan osan ohjelman sisäisestä rakenteesta. Ainoat määritellyt asiat ohjelmassa ovat käyttöliittymä ja domain-oliot, jotka tulevat tehtäväpohjan mukana. Tehtäväpohjassa on myös valmis konfiguraatio.
Tehtävästä on mahdollista saada yhteensä 4 pistettä.
Huom! Kannattanee aloittaa näyttelijän lisäämisestä ja poistamisesta. Hyödynnä valmiiksi tarjottuja käyttöliittymätiedostoja kontrollerien ym. toteuttamisessa.
pisteytys
- + 1p: Näyttelijän lisääminen ja poistaminen onnistuu. Käyttöliittymän olettamat osoitteet ja niiden parametrit:
GET /actors- näyttelijöiden listaus, ei parametreja pyynnössä. Lisää pyyntöön attribuutinactors, joka sisältää kaikki näyttelijät ja luo sivun/src/main/resources/templates/actors.htmlpohjalta näkymän.POST /actors- parametriname, jossa on lisättävän näyttelijän nimi. Lisäyksen tulee lopulta ohjata pyyntö osoitteeseen/actors.DELETE /actors/{actorId}- polun parametriactorId, joka sisältää poistettavan näyttelijän tunnuksen. Poiston tulee lopulta ohjata pyyntö osoitteeseen/actors. Käytä kontrollerimetodin toteutuksessa annotaatiota@DeleteMapping.
- + 1p: Elokuvan lisääminen ja poistaminen onnistuu. Käyttöliittymän olettamat osoitteet ja niiden parametrit:
GET /movies- elokuvien listaus, ei parametreja pyynnössä. Lisää pyyntöön attribuutinmovies, joka sisältää kaikki elokuvat ja luo sivun/src/main/resources/templates/movies.htmlpohjalta näkymän.POST /movies- elokuvan lisäys, parametritname, joka sisältää lisättävän elokuvan nimen, jalengthInMinutes, joka sisältää elokuvan pituuden minuuteissa. Lisäyksen tulee lopulta ohjata pyyntö osoitteeseen/movies.DELETE /movies/{movieId}- polun parametrimovieId, joka sisältää poistettavan elokuvan tietokantatunnuksen. Poiston tulee lopulta ohjata pyyntö osoitteeseen/movies.
- + 2p: Näyttelijän voi lisätä elokuvaan (kun näyttelijä tai elokuva poistetaan, tulee myös poistaa viitteet näyttelijästä elokuvaan ja elokuvasta näyttelijään). Käyttöliittymän olettamat osoitteet ja niiden parametrit:
GET /actors/{actorId}- polun parametriactorId, joka sisältää näytettävän näyttelijän tietokantatunnuksen. Asettaa pyyntöön sekä attribuutinactorjossa näyttelijä-olio että attribuutinmovies, jossa kaikki elokuvat, sekä luo sivun/src/main/resources/templates/actor.htmlpohjalta näkymän.POST /actors/{actorId}/movies- polun parametriactorId, joka sisältää kytkettävän näyttelijän tietokantatunnuksen, ja parametrimovieId, joka sisältää kytkettävän elokuvan tietokantatunnuksen. Lisäämisen tulee lopulta ohjata pyyntö osoitteeseen/actors.